在大語言模型(LLM)應用中,使用者請求與模型響應的長度差異、模型在Prompt和Generate階段產生的Token數量的隨機性,以及GPU資源佔用的不確定性,使得傳統負載平衡策略難以即時感知後端負載壓力,導致執行個體負載不均,影響系統輸送量和響應效率。EAS推出LLM智能路由群組件,基於LLM特有的Metrics動態分發請求,均衡各推理執行個體的算力與顯存分配,提升叢集資源使用率與系統穩定性。
工作原理
架構概覽
LLM智能路由是由LLM Gateway、LLM Scheduler以及LLM Agent三個核心組件構成,它們協同工作,為後端的大語言模型推理執行個體叢集提供智能的流量分發和管理。
LLM智能路由本質上是一種特殊的EAS服務,必須和推理服務部署在同一個服務群組下,才能正常工作。

核心流程如下:
執行個體註冊:推理服務啟動後,
LLM Agent等待推理引擎就緒,然後向LLM Scheduler註冊該執行個體,並開始周期性上報健康情況和效能指標。流量接入:使用者的請求首先到達
LLM Gateway。調度決策:
LLM Gateway向LLM Scheduler發起調度請求。智能調度:
LLM Scheduler基於調度策略和從各LLM Agent收集的即時指標,選擇一個當前最優的後端執行個體。請求轉寄:
LLM Scheduler將決策結果返回給LLM Gateway,LLM Gateway隨即把使用者的原始請求轉寄到該目標執行個體。請求緩衝:當所有後端執行個體均處於高負載狀態時,新請求會暫時緩衝在
LLM Gateway的隊列中,等待LLM Scheduler找到合適的轉寄時機,以避免請求失敗。
核心組件
組件 | 核心職責 |
LLM Gateway | 流量入口與請求處理中心。負責接收所有使用者請求,並根據
|
LLM Scheduler | 智能調度的大腦。它彙集所有 |
LLM Agent | 部署在推理執行個體旁的探針。作為Sidecar容器與每個推理執行個體一同部署。負責採集推理引擎的效能指標,與 |
Failover機制
系統設計了多層容錯機制以保障服務穩定性:
LLM Gateway(高可用):作為無狀態的流量接入層,建議部署至少2個執行個體。當某個執行個體故障時,流量會自動切換至其他健康執行個體,保證服務的持續可用性。
LLM Scheduler(降級容錯):作為請求調度組件,單一實例運行以實現全域調度。
LLM Scheduler發生故障時,LLM Gateway會在心跳失敗後自動降級,採用輪詢策略將請求直接轉寄給後端執行個體。這保證了服務的可用性,但會犧牲調度效能。待LLM Scheduler恢複後,LLM Gateway會自動切換回智能調度模式。推理執行個體或LLM Agent(自動摘除):當某個推理執行個體或其伴生的
LLM Agent發生故障時,LLM Agent與LLM Scheduler之間的心跳會中斷。LLM Scheduler會立即將該執行個體從可用服務列表中移除,不再向其分配新流量。待執行個體恢複並重新上報心跳後,它將自動重新加入服務列表。
多推理引擎支援
由於不同LLM推理引擎的/metrics介面返回的指標資訊存在差異,LLM Agent負責對這些指標進行採集並統一格式化處理後上報。LLM Scheduler無需關注具體推理引擎的實現細節,只需基於統一化指標進行調度演算法的編寫。目前支援的LLM推理引擎及其對應的採集指標如下:
LLM推理引擎 | 指標 | 說明 |
vLLM | vllm:num_requests_running | 正在啟動並執行請求數。 |
vllm:num_requests_waiting | 在排隊等待的請求數。 | |
vllm:gpu_cache_usage_perc | GPU KV Cache的使用率。 | |
vllm:prompt_tokens_total | 總Prompt的Token數。 | |
vllm:generation_tokens_total | 產生的總的Token數。 | |
SGLang | sglang:num_running_reqs | 正在啟動並執行請求數。 |
sglang:num_queue_reqs | 在排隊等待的請求數。 | |
sglang:token_usage | KV Cache的使用率。 | |
sglang:prompt_tokens_total | 總Prompt的Token數。 | |
sglang:gen_throughput | 每秒產生的Token數。 |
使用限制
不支援更新時添加:LLM智能路由功能僅能在建立新服務時配置。對於一個已存在的、未使用智能路由的推理服務,無法通過更新服務操作來為其添加智能路由。
推理引擎節流:目前僅支援 vLLM 或 SGLang。
推薦部署多推理執行個體:在部署多個推理執行個體的情境下,LLM智能路由的功能價值才能得以發揮。
快速開始:使用LLM智能路由
步驟一:部署LLM智能路由服務
登入PAI控制台,在頁面上方選擇目標地區。
在左側導覽列單擊模型在线服务(EAS),選擇目標工作空間後進入EAS。
單擊部署服务,選擇场景化模型部署>LLM智能路由部署。
配置參數:
參數
描述
基本信息
服务名称
自訂服務名稱,例如
llm_gateway。资源信息
部署资源
LLM Gateway的資源配置。為確保高可用,副本数預設為2,建議保持。預設 CPU 為4核,記憶體 為8 GB。调度配置
LLM Scheduler的資源配置。預設 CPU 為2核,記憶體為 4 GB。调度策略
選擇後端推理執行個體的負載平衡策略,預設基于前缀缓存。詳細對比和選擇建議請參見調度策略詳解與選擇。
單擊部署。當服務狀態變為运行中,表示部署成功。
部署成功後,系統會自動建立一個群組服務,命名格式為group_<LLM智能路由服務名稱>。您可以前往模型在线服务(EAS)頁面的灰度发布頁簽進行查看。
由於智能路由與服務隊列存在衝突,同一服務群組中兩者不可同時存在。
步驟二:部署LLM服務
必須在部署新LLM服務時配置智能路由功能,無法通過更新已有LLM服務來添加。
以部署 Qwen3-8B 為例,步驟如下:
單擊部署服务,選擇场景化模型部署> LLM大语言模型部署。
配置以下關鍵參數:
參數
值
基本信息
模型配置
選擇公共模型,搜尋並選擇Qwen3-8B。
推理引擎
選擇vLLM(推薦,相容 OpenAI API)。
說明如果LLM智能路由服務選擇基于前缀缓存的調度策略,部署LLM服務時若推理引擎選擇vLLM,請確保開啟引擎的首碼緩衝功能。
部署模板
選擇單機。系統將根據模板自動填滿推薦的執行個體規格、鏡像等參數。
服务功能
LLM智能路由
開啟開關,從下拉式清單中選擇步驟一部署的LLM智能路由服務。
單擊部署,服務部署耗時約5分鐘。當服務狀態變為运行中,表示部署成功。
步驟三:調用測試
所有請求都應發送到LLM智能路由服務的訪問地址,而不是後端的具體推理服務。
擷取訪問憑證。
單擊LLM智能路由服務進入概览頁面,在基本信息地區單擊查看调用信息。
在調用資訊頁面,複製服务独立流量入口下的公网调用地址和Token。

構建請求URL並發起調用。
URL結構:
<LLM智能路由訪問地址>/<LLM服務API路徑>樣本:
http://********.pai-eas.aliyuncs.com/api/predict/group_llm_gateway.llm_gateway/v1/chat/completions
請求樣本:
# 將 <YOUR_GATEWAY_URL> 和 <YOUR_TOKEN> 替換為您的實際資訊 curl -X POST "<YOUR_GATEWAY_URL>/v1/chat/completions" \ -H "Authorization: Bearer <YOUR_TOKEN>" \ -H "Content-Type: application/json" \ -N \ -d '{ "messages": [{"role": "user", "content": "你好"}], "stream": true }'返回結果樣本如下:
data: {"id":"chatcmpl-9a9f8299*****","object":"chat.completion.chunk","created":1762245102,"model":"Qwen3-8B","choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]} data: {"id":"chatcmpl-9a9f8299*****","object":"chat.completion.chunk","created":1762245102,"model":"Qwen3-8B","choices":[{"index":0,"delta":{"content":"<think>","tool_calls":[]}}]} ... data: [DONE]
高階配置
JSON獨立部署提供了更靈活的配置選項,可以對LLM Gateway 指定資源規格,對請求處理行為進行精細化配置。
配置入口:在推理服务頁面,單擊部署服务,然後在自定义模型部署地區,單擊JSON独立部署。
配置樣本:
{ "cloud": { "computing": { "instance_type": "ecs.c7.large" } }, "llm_gateway": { "max_queue_size": 128, "retry_count": 2, "wait_schedule_timeout": 5000, "wait_schedule_try_period": 500 }, "llm_scheduler": { "cpu": 2, "memory": 4000, "policy": "prefix-cache" }, "metadata": { "group": "group_llm_gateway", "instance": 2, "name": "llm_gateway", "type": "LLMGatewayService" } }參數說明:
參數
說明
metadata
type
必填。固定為
LLMGatewayService,表示部署一個LLM智能路由服務。instance
必填。
LLM Gateway的副本數。建議至少設定為2,以防止單點故障。cpu
LLM Gateway每個副本的CPU(核心數)。memory
LLM Gateway的記憶體(GB)。group
LLM智能路由服務歸屬的服務群組。
cloud.computing.instance_type
指定
LLM Gateway使用的資源規格。此時無需配置metadata.cpu與metadata.memory。llm_gateway
max_queue_size
LLM Gateway緩衝隊列的最大長度,預設是512。當超過後端推理架構處理能力時,多餘的請求會緩衝在該隊列,等待調度。
retry_count
重試次數,預設是2。當後端推理執行個體異常時,進行請求重試並轉寄到新的執行個體。
wait_schedule_timeout
當後端引擎處於滿負荷時,請求會間隔嘗試進行調度。該參數表示嘗試調度的時間,預設為10秒。
wait_schedule_try_period
每次嘗試調度的間隔時間,預設為1秒。
llm_scheduler
cpu
LLM Scheduler的CPU(核心數),預設為4核。memory
LLM Scheduler的記憶體(GB),預設為4 GB。policy
調度策略,預設值
prefix-cache。可選值及說明請參見調度策略詳解與選擇。prefill_policy
policy選擇pd-split時,需分別指定Prefill和Decode階段的調度策略。可取值:prefix-cache、llm-metric-based、least-request、least-token。
decode_policy
調度策略詳解與選擇
選擇合適的調度策略是發揮LLM智能路由價值的關鍵。下表詳細對比了各種策略的邏輯、適用情境及優缺點,協助您做出最佳決策。
策略名稱稱 | JSON值 | 核心邏輯 | 適用情境 | 優點 | 注意事項 |
基于前缀缓存 | prefix-cache | (推薦) 綜合性策略。優先將具有相同歷史上下文(Prompt)的請求發往已緩衝其KV Cache的執行個體。 | 多輪對話機器人、RAG系統中System Prompt固定的情境。 | 顯著降低TTFT,提升多輪對話效能和輸送量。 | 需推理引擎開啟Prefix Caching功能。 |
基于LLM指标 | llm-metric-based | 根據後端執行個體的綜合負載指標(如排隊請求數、運行中請求數、KV Cache使用率)進行智能調度。 | 請求模式多樣化,無明顯對話特徵的通用LLM工作負載。 | 能夠很好地平衡不同執行個體的負載,提高資源使用率。 | 調度邏輯相對複雜,不如首碼緩衝策略在特定情境下效果極致。 |
最少请求 | least-request | 將新請求發送到當前正在處理的請求數量最少的執行個體。 | 請求的計算複雜度(Token長度、產生長度)相對均勻的情境。 | 簡單高效,能快速均衡執行個體間的請求數量。 | 無法感知請求的實際負載,可能導致短請求執行個體空閑,長請求執行個體過載。 |
最少token | least-token | 將新請求發送到當前正在處理的Token總數(輸入+輸出)最少的執行個體。 | Token數量能較好地反映請求處理成本的情境。 | 比“最少請求”更能反映執行個體的真實負載。 | 依賴對Token數量的預估,且並非所有引擎都上報此指標。 |
静态PD分离 | pd-split | 需預先將執行個體劃分為Prefill組和Decode組,並為兩組分別指定調度策略。 | Prefill和Decode階段的計算/訪存特性差異巨大,且分離部署能帶來顯著收益的情境。 | 極致最佳化,最大化硬體利用率。 | 配置複雜,需要對模型和業務有深入理解,並獨立部署Prefill和Decode服務。 |
动态PD分离 | dynamic-pd-split | 執行個體無需預設角色,調度器根據即時負載動態地將請求的Prefill或Decode階段分發給最合適的執行個體。 | 同上,但適用於負載動態變化的情境。 | 比靜態分離更靈活,能自適應負載變化。 | 配置更複雜,對調度器和引擎要求更高。 |
查看服務監控指標
部署服務後,可以在EAS控制台查看服務的核心效能指標,以評估智能路由的效果。
在模型線上服務(EAS)頁面,單擊已部署的LLM智能路由服務進入服務詳情。在监控頁簽,關注以下核心指標:
Token Throughput LLM輸入和輸出Token的輸送量
| GPU Cache Usage LLM Engine GPU KV Cache的使用率
|
Engine Current Requests LLM Engine即時請求並發數
| Gateway Current Requests LLM智能路由即時請求數
|
Time To First Token 請求的首包延時
| Time Per Output Token 請求的每包延時
|
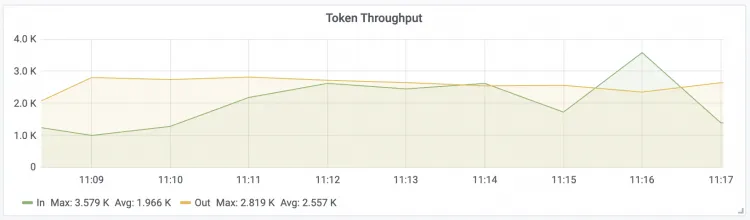
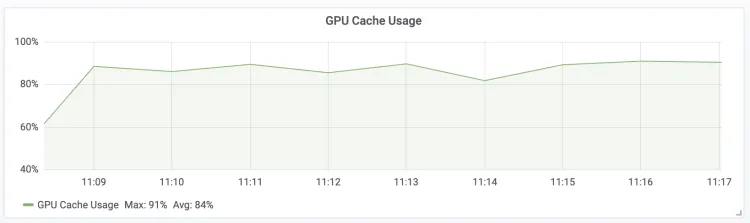

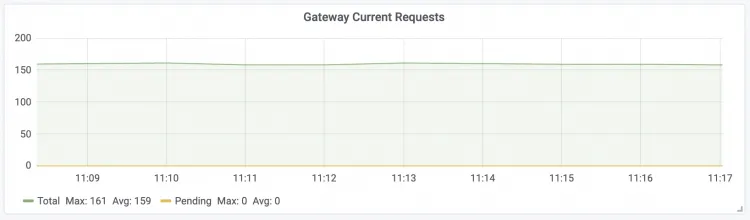


附錄:使用Claude Code調用
設定 Claude Code 使用EAS智能路由服務提供的 BASE URL 與 TOKEN。
# 將 <YOUR_GATEWAY_URL> 和 <YOUR_TOKEN> 替換為您的實際資訊 export ANTHROPIC_BASE_URL=<YOUR_GATEWAY_URL> export ANTHROPIC_AUTH_TOKEN=<YOUR_TOKEN>直接運行 Claude Code 工具。
claude "寫一個 Python 的 Hello World"
附錄:效能測試對比
通過對Distill-Qwen-7B、QwQ-32B和Qwen2.5-72B三個模型進行測試,發現LLM智能路由在推理服務的速度和吞吐上有顯著的效能提升,具體的測試環境和測試結果如下。
以下測試結果僅供參考,實際表現請以您的實際測試結果為準。
測試環境
調動策略:prefix-cache
測試資料: ShareGPT_V3_unfiltered_cleaned_split.json (多輪對話資料集)
推理引擎: vLLM (0.7.3)
後端執行個體數: 5
測試結果
測試模型 | Distill-Qwen-7B | QwQ-32B | Qwen2.5-72b | ||||||
卡型 | ml.gu8tf.8.40xlarge | ml.gu8tf.8.40xlarge | ml.gu7xf.8xlarge-gu108 | ||||||
並發數 | 500 | 100 | 100 | ||||||
指標 | 無LLM智能路由 | 使用LLM智能路由 | 效果提升 | 無LLM智能路由 | 使用LLM智能路由 | 效果提升 | 無LLM智能路由 | 使用LLM智能路由 | 效果提升 |
Successful requests | 3698 | 3612 | - | 1194 | 1194 | - | 1194 | 1194 | - |
Benchmark duration | 460.79 s | 435.70 s | - | 1418.54 s | 1339.04 s | - | 479.53 s | 456.69 s | - |
Total input tokens | 6605953 | 6426637 | - | 2646701 | 2645010 | - | 1336301 | 1337015 | - |
Total generated tokens | 4898730 | 4750113 | - | 1908956 | 1902894 | - | 924856 | 925208 | - |
Request throughput | 8.03 req/s | 8.29 req/s | +3.2% | 0.84 req/s | 0.89 req/s | +5.95% | 2.49 req/s | 2.61 req/s | +4.8% |
Output token throughput | 10631.17 tok/s | 10902.30 tok/s | +2.5% | 1345.72 tok/s | 1421.08 tok/s | +5.6% | 1928.66 tok/s | 2025.92 tok/s | +5.0% |
Total Token throughput | 24967.33 tok/s | 25652.51 tok/s | +2.7% | 3211.52 tok/s | 3396.38 tok/s | +5.8% | 4715.34 tok/s | 4953.56 tok/s | +5.0% |
Mean TTFT | 532.79 ms | 508.90 ms | +4.5% | 1144.62 ms | 859.42 ms | +25.0% | 508.55 ms | 389.66 ms | +23.4% |
Median TTFT | 274.23 ms | 246.30 ms | - | 749.39 ms | 565.61 ms | - | 325.33 ms | 190.04 ms | - |
P99 TTFT | 3841.49 ms | 3526.62 ms | - | 5339.61 ms | 5027.39 ms | - | 2802.26 ms | 2678.70 ms | - |
Mean TPOT | 40.65 ms | 39.20 ms | +3.5% | 68.78 ms | 65.73 ms | +4.4% | 46.83 ms | 43.97 ms | +4.4% |
Median TPOT | 41.14 ms | 39.61 ms | - | 69.19 ms | 66.33 ms | - | 45.37 ms | 43.30 ms | - |
P99 TPOT | 62.57 ms | 58.71 ms | - | 100.35 ms | 95.55 ms | - | 62.29 ms | 54.79 ms | - |