Designer提供自訂Python指令碼的功能,您可以使用Python指令碼組件自訂安裝依賴包及運行自訂的Python函數。本文為您介紹Python指令碼組件的配置方法及使用樣本。
背景資訊
Python指令碼組件位於Designer組件的自訂演算法組件檔案夾下。
前提條件
已完成DLC相關許可權授權,授權方法詳情請參見雲產品依賴與授權:DLC。
由於Python指令碼需要依賴於DLC作為底層計算資源,因此您需要在工作空間關聯DLC計算資源,詳情請參見管理工作空間。
由於Python指令碼依賴OSS作為代碼儲存環境,因此您需要先建立OSS Bucket,詳情請參見建立儲存空間。
重要建立的OSS Bucket必須與Designer和DLC在同一地區。
已在工作空間中,為使用該組件的RAM帳號添加演算法開發角色,詳情請參見管理工作空間成員。如果操作帳號還需同時使用MaxCompute作為資料來源,還需要同時添加MaxCompute開發角色。
可視化配置組件
輸入樁
Python指令碼組件共有4個輸入連接埠,均可以串連OSS路徑或MaxCompute表類型的資料。
OSS路徑輸入
來自上遊組件的OSS輸入,會被掛載到Python指令碼執行的節點上,系統會將掛載後的檔案路徑,以arguments的形式,傳遞給Python指令碼,無需手工配置。arguments的規範如
python main.py --input1 /ml/input/data/input1,代表第一個輸入連接埠輸入的OSS路徑。在Python指令碼中可以按照讀本地檔案的方式訪問/ml/input/data/input1來讀取掛載後的檔案。MaxCompute表輸入
MaxCompute表的輸入不支援掛載,系統會將對應的表資訊以URI的形式,作為arguments傳遞給Python指令碼,無需手工配置。arguments的規範如
python main.py --input1 odps://some-project-name/tables/table,代表第一個輸入連接埠輸入的MaxCompute表。對於MaxCompute URI形式的輸入,您可以使用該組件代碼模板內的parse_odps_url函數解析出對應的ProjectName、TableName和Partition等元資訊,詳情請參見使用樣本。
輸出樁
Python指令碼組件共有4個輸出連接埠,其中輸出連接埠1和輸出連接埠2是OSS路徑輸出連接埠,輸出連接埠3和輸出連接埠4是MaxCompute表輸出連接埠。
OSS路徑輸出
該組件的指令碼設定頁簽的任務輸出路徑參數配置的OSS路徑,會被系統自動掛載到
/ml/output/下。該組件的輸出連接埠OSS輸出-1和OSS輸出-2,分別對應子目錄/ml/output/output1和/ml/output/output2。在指令碼中可以按照寫本地檔案的方式將需要傳遞給下遊節點的檔案寫到這兩個目錄中。MaxCompute表輸出
如果當前工作空間配置了MaxCompute專案,系統會自動傳遞一個暫存資料表URI到Python指令碼,例如:
python main.py --output3 odps://<some-project-name>/tables/<output-table-name>,您可以通過PyODPS來建立暫存資料表URI中指定的表,並將Python指令碼處理完成的資料寫出到這個表,最後通過組件連線將表傳遞給下遊組件,詳情可參考下文中的樣本。
組件參數
指令碼設定
參數
描述
任務輸出路徑
選擇任務輸出的OSS路徑。
配置好的OSS目錄會掛載到作業容器的
/ml/output/路徑下,任務寫出到/ml/output/路徑下的資料,會被持久化儲存到對應的OSS目錄。組件的輸出連接埠OSS輸出-1和OSS輸出-2分別對應
/ml/output/路徑下的子路徑output1和output2。當組件的OSS輸出連接埠接入下遊組件時,下遊組件接收到的資料為對應子路徑的資料。
設定代碼源
(任選一種即可)
編輯框提交
Python代碼:選擇代碼儲存的OSS路徑,編輯框中寫入的代碼會儲存在該OSS路徑下。Python代碼的檔案名稱預設為main.py。
重要第一次單擊儲存前,請確認指定的代碼儲存路徑下無同名檔案,避免檔案被覆蓋。
Python代碼編輯器:編輯框內預設提供範例程式碼,詳情請參見使用樣本。您可以直接在編輯器內編寫代碼。
指定Git配置
Git地址:Git倉庫地址。
代碼分支:代碼分支,預設為master。
代碼Commit:Commit的優先順序大於Branch,如果您填寫了該參數,則Branch不生效。
Git使用者名稱:如果您需要訪問私人代碼集,則需要指定該參數。
Git訪問Token:訪問私人代碼倉庫時必填。更多資訊,請參見附錄:擷取GitHub帳號的Token。
選擇代碼配置
選擇代碼配置:選擇已建立的代碼配置。具體操作,請參見代碼配置。
代碼分支:代碼分支,預設為master。
代碼Commit:Commit的優先順序大於Branch,如果您填寫了該參數,則Branch不生效。
從OSS中選擇檔案或目錄
在OSS路徑選擇對應代碼上傳的路徑。
執行命令
在文字框中,輸入您需要執行的命令,比如:
python main.py。說明系統會自動按照指令碼名稱和組件輸入輸出連接埠的串連情況來產生執行命令,無需手動設定。
進階選項
第三方依賴庫:在文字框中,您可以通過添加指令碼的方式安裝第三方依賴庫,格式與Python的requirement.txt相同,具體如下所示。節點執行前,會自動安裝文字框中配置的第三方依賴庫。
cycler==0.10.0 # via matplotlib kiwisolver==1.2.0 # via matplotlib matplotlib==3.2.1 numpy==1.18.5 pandas==1.0.4 pyparsing==2.4.7 # via matplotlib python-dateutil==2.8.1 # via matplotlib, pandas pytz==2020.1 # via pandas scipy==1.4.1 # via seaborn是否開啟容錯監控:勾選該參數後,會出現容錯監控配置文字框,您可以在文字框中通過添加容錯監控具體參數,指定容錯監控的內容。
執行配置
參數
描述
選擇資源群組
支援選擇DLC公用資源群組:
當選擇公用資源群組時,您需要配置選擇機器執行個體類型參數,支援配置CPU或GPU機器執行個體。預設為:ecs.c6.large。
預設為當前工作空間下的DLC雲原生資源的預設資源群組。
專用網路配置
支援選擇已建立的專用網路進行掛載。
安全性群組
支援選擇已建立的安全性群組進行掛載。
進階選項
選中該參數後,支援配置以下參數:
選擇機器執行個體個數:您可以按照實際需要配置機器執行個體個數,預設為1。
選擇作業鏡像:預設為開源的xgboost1.6.0版本,如果您需要使用深度學習架構,則需要修改鏡像。
選擇任務類型:僅當提交的代碼按照分布式實現時,才需要修改該參數,支援以下取值:
XGBoost/LightGBM Job
TensorFlow Job
PyTorch Job
MPI Job
使用樣本
預設範例程式碼解析
Python指令碼組件預設提供的範例程式碼如下。
import os
import argparse
import json
"""
Python V2 組件範例程式碼
"""
# 當前工作空間下的預設MaxCompute執行環境,包含MaxCompute專案的名稱以及Endpoint。
# 需要當前的工作空間下有MaxCompute專案時,作業的執行環境才會注入。
# 樣本: {"endpoint": "http://service.cn.maxcompute.aliyun-inc.com/api", "odpsProject": "lq_test_mc_project"}。
ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION"
def init_odps():
from odps import ODPS
# 當前工作空間的預設MaxCompute專案資訊。
mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION])
o = ODPS(
access_id="<YourAccessKeyId>",
secret_access_key="<YourAccessKeySecret>",
# 請根據Project所在的Region選擇,比如:http://service.cn-shanghai.maxcompute.aliyun-inc.com/api。
endpoint=mc_execution["endpoint"],
project=mc_execution["odpsProject"],
)
return o
def parse_odps_url(table_uri):
from urllib import parse
parsed = parse.urlparse(table_uri)
project_name = parsed.hostname
r = parsed.path.split("/", 2)
table_name = r[2]
if len(r) > 3:
partition = r[3]
else:
partition = None
return project_name, table_name, partition
def parse_args():
parser = argparse.ArgumentParser(description="PythonV2 component script example.")
parser.add_argument("--input1", type=str, default=None, help="Component input port 1.")
parser.add_argument("--input2", type=str, default=None, help="Component input port 2.")
parser.add_argument("--input3", type=str, default=None, help="Component input port 3.")
parser.add_argument("--input4", type=str, default=None, help="Component input port 4.")
parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.")
parser.add_argument("--output2", type=str, default=None, help="Output OSS port 2.")
parser.add_argument("--output3", type=str, default=None, help="Output MaxComputeTable 1.")
parser.add_argument("--output4", type=str, default=None, help="Output MaxComputeTable 2.")
args, _ = parser.parse_known_args()
return args
def write_table_example(args):
# 樣本:通過執行SQL語句複製PAI提供的公用表資料,作為當前組件輸出連接埠3指定的暫存資料表。
output_table_uri = args.output3
o = init_odps()
project_name, table_name, partition = parse_odps_url(output_table_uri)
o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;")
def write_output1(args):
# 樣本:將資料結果寫入掛載的OSS路徑(輸出連接埠1的子目錄),對應的結果可以通過連線傳遞到下遊組件。
output_path = args.output1
os.makedirs(output_path, exist_ok=True)
p = os.path.join(output_path, "result.text")
with open(p, "w") as f:
f.write("TestAccuracy=0.88")
if __name__ == "__main__":
args = parse_args()
print("Input1={}".format(args.input1))
print("Output1={}".format(args.output1))
# write_table_example(args)
# write_output1(args)
常用函數說明:
init_odps():初始化一個ODPS執行個體,用來讀取MaxCompute表資料,需要填寫您的AccessKeyId和AccessKeySecret,關於如何擷取AccessKey,詳情請參見擷取AccessKey。
parse_odps_url(table_uri):解析輸入的MaxCompute表的URI,返回解析完成得到的專案名稱、表名和分區。table_uri格式為:
odps://${your_projectname}/tables/${table_name}/${pt_1}/${pt_2}/,比如:odps://test/tables/iris/pa=1/pb=1,其中pa=1/pb=1為一個多級分區。parse_args():解析傳入指令碼的arguments,輸入輸出資料會以arguments的方式傳遞給執行的指令碼。
使用樣本1:Python指令碼組件與其他組件串聯使用
參考並修改心臟病預測案例模板,來說明Python指令碼組件如何與Designer其他組件串聯使用。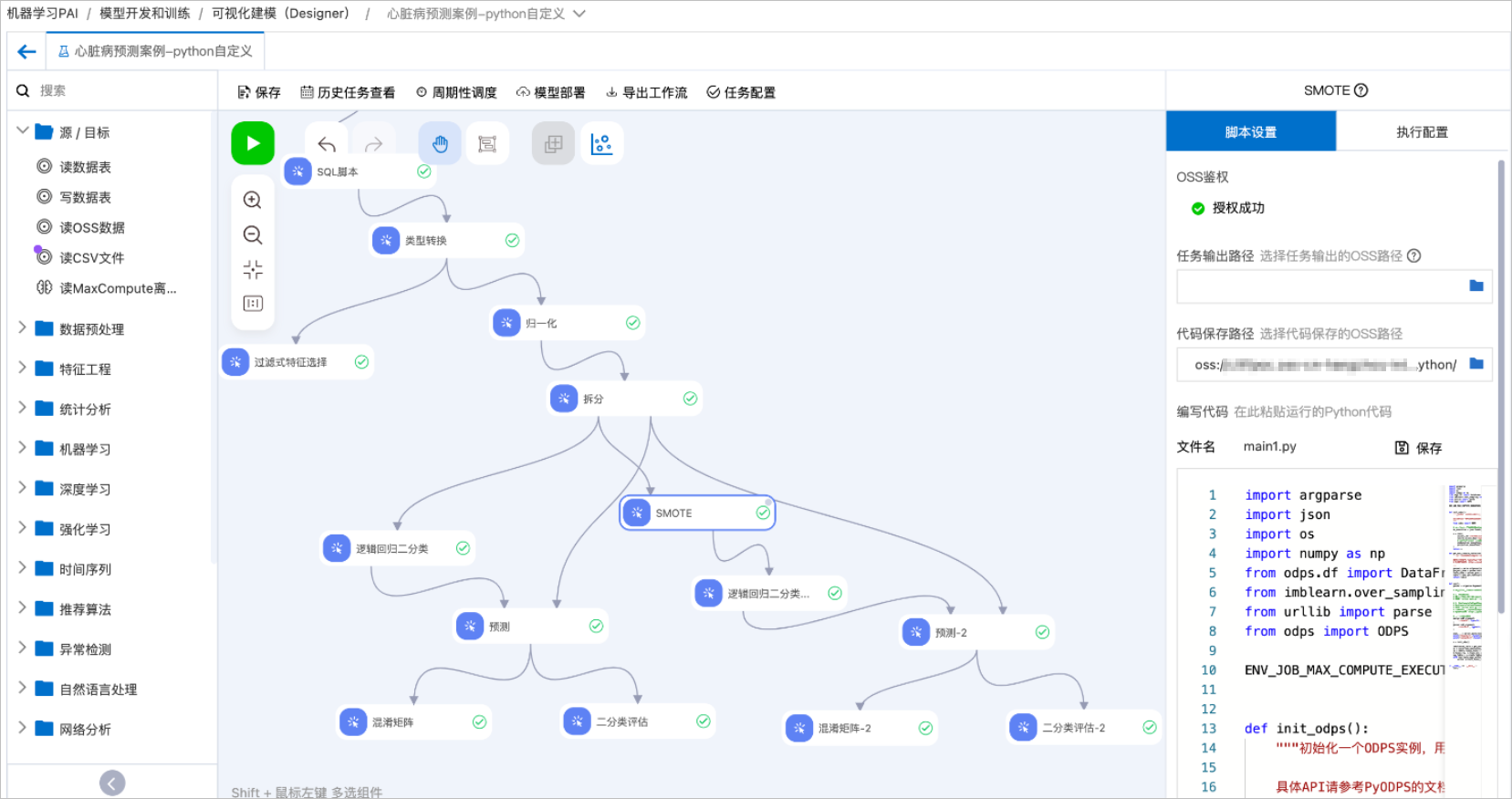 工作流程配置說明:
工作流程配置說明:
建立心臟病預測案例模板並進入工作流程,具體操作請參見心臟病預測。
將Python指令碼組件拖入畫布並重新命名為SMOTE,並配置以下代碼。
重要在我們使用的鏡像中沒有imblearn庫,需要在該組件的指令碼設定頁簽的第三方依賴庫中配置imblearn。在節點執行前,會自動安裝該庫。
import argparse import json import os from odps.df import DataFrame from imblearn.over_sampling import SMOTE from urllib import parse from odps import ODPS ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION" def init_odps(): # 當前工作空間的預設MaxCompute專案資訊。 mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION]) o = ODPS( access_id="<替換成您自己的AccessKey>", secret_access_key="<替換成您自己的AccessKeySecret>", # 請根據Project所在的Region選擇,比如:http://service.cn-shanghai.maxcompute.aliyun-inc.com/api。 endpoint=mc_execution["endpoint"], project=mc_execution["odpsProject"], ) return o def get_max_compute_table(table_uri, odps): parsed = parse.urlparse(table_uri) project_name = parsed.hostname table_name = parsed.path.split('/')[2] table = odps.get_table(project_name + "." + table_name) return table def run(): parser = argparse.ArgumentParser(description='PythonV2 component script example.') parser.add_argument( '--input1', type=str, default=None, help='Component input port 1.' ) parser.add_argument( '--output3', type=str, default=None, help='Component input port 1.' ) args, _ = parser.parse_known_args() print('Input1={}'.format(args.input1)) print('output3={}'.format(args.output3)) o = init_odps() imbalanced_table = get_max_compute_table(args.input1, o) df = DataFrame(imbalanced_table).to_pandas() sm = SMOTE(random_state=2) X_train_res, y_train_res = sm.fit_resample(df, df['ifhealth'].ravel()) new_table = o.create_table(get_max_compute_table(args.output3, o).name, imbalanced_table.schema, if_not_exists=True) with new_table.open_writer() as writer: writer.write(X_train_res.values.tolist()) if __name__ == '__main__': run()其中access_id和secret_access_key需要配置您自己的AccessKey和AccessKeySecret。關於如何擷取AccessKey,詳情請參見擷取AccessKey。
將SMOTE組件接入拆分組件的下遊,使用經典的SMOTE演算法對拆分完得到的訓練資料做過採樣,對訓練集裡樣本數量較少的類別進行過採樣,合成新的樣本來緩解類不平衡。
將SMOTE組件得到的新資料接入羅吉斯迴歸二分類組件做訓練。
將訓練得到的模型與左側分支中的模型一樣,串連相同的預測資料和評估組件做橫向對比。組件運行成功後,單擊
 進入可視化頁面,查看最終評估結果。
進入可視化頁面,查看最終評估結果。
額外做過採樣並未對模型效果有特別明顯的提升,說明原樣本分布及模型效果都比較好。
使用樣本2:使用Designer做純DLC任務的編排
您可以在Designer中串連多個自訂Python指令碼組件,來實現一組DLC任務的Pipeline編排和定時調度。以下圖為例,按照Directed Acyclic Graph(DAG)圖順序啟動4個DLC任務。
如果DLC的執行代碼不需要讀取上遊節點資料,也不需要給下遊節點傳遞資料,則節點之間的連線只表示調度執行的依賴關係和先後順序。
 後續您可以將使用Designer開發完成的整個工作流程,一鍵部署到DataWorks做定時調度,具體操作請參見使用DataWorks離線調度Designer工作流程。
後續您可以將使用Designer開發完成的整個工作流程,一鍵部署到DataWorks做定時調度,具體操作請參見使用DataWorks離線調度Designer工作流程。
使用樣本3:將全域變數傳入Python指令碼組件
配置全域變數。
在Designer工作流程頁面單擊空白畫布,在右側全域變數頁簽配置全域變數。

使用以下兩種方式將已配置的全域變數傳入Python指令碼組件,您可以任意選擇一種方式。
單擊Python指令碼元件節點,在右側指令碼設定頁簽選中進階選項,在執行命令中配置傳入參數為全域變數。
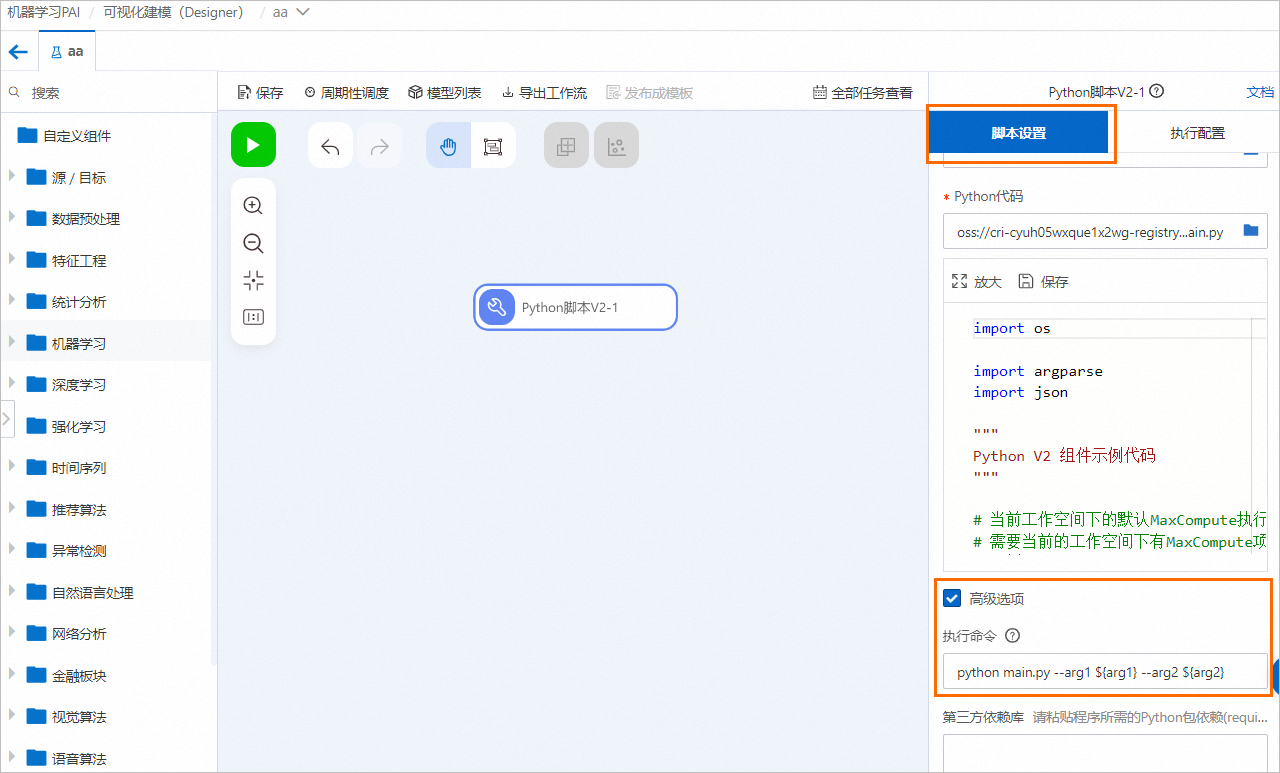
修改Python代碼,使用argparser解析參數。
更新後的Python代碼如下,該代碼以步驟1配置的全域變數為例,您需要根據實際配置的全域變數更新代碼。後續您可以直接將更新後的代碼替換到Python指令碼元件節點指令碼設定頁簽的代碼編輯地區。
import os import argparse import json """ Python V2 組件範例程式碼 """ ENV_JOB_MAX_COMPUTE_EXECUTION = "JOB_MAX_COMPUTE_EXECUTION" def init_odps(): from odps import ODPS mc_execution = json.loads(os.environ[ENV_JOB_MAX_COMPUTE_EXECUTION]) o = ODPS( access_id="<YourAccessKeyId>", secret_access_key="<YourAccessKeySecret>", endpoint=mc_execution["endpoint"], project=mc_execution["odpsProject"], ) return o def parse_odps_url(table_uri): from urllib import parse parsed = parse.urlparse(table_uri) project_name = parsed.hostname r = parsed.path.split("/", 2) table_name = r[2] if len(r) > 3: partition = r[3] else: partition = None return project_name, table_name, partition def parse_args(): parser = argparse.ArgumentParser(description="PythonV2 component script example.") parser.add_argument("--input1", type=str, default=None, help="Component input port 1.") parser.add_argument("--input2", type=str, default=None, help="Component input port 2.") parser.add_argument("--input3", type=str, default=None, help="Component input port 3.") parser.add_argument("--input4", type=str, default=None, help="Component input port 4.") parser.add_argument("--output1", type=str, default=None, help="Output OSS port 1.") parser.add_argument("--output2", type=str, default=None, help="Output OSS port 2.") parser.add_argument("--output3", type=str, default=None, help="Output MaxComputeTable 1.") parser.add_argument("--output4", type=str, default=None, help="Output MaxComputeTable 2.") # 根據已配置的全域變數,新增代碼。 parser.add_argument("--arg1", type=str, default=None, help="Argument 1.") parser.add_argument("--arg2", type=int, default=None, help="Argument 2.") args, _ = parser.parse_known_args() return args def write_table_example(args): output_table_uri = args.output3 o = init_odps() project_name, table_name, partition = parse_odps_url(output_table_uri) o.run_sql(f"create table {project_name}.{table_name} as select * from pai_online_project.heart_disease_prediction;") def write_output1(args): output_path = args.output1 os.makedirs(output_path, exist_ok=True) p = os.path.join(output_path, "result.text") with open(p, "w") as f: f.write("TestAccuracy=0.88") if __name__ == "__main__": args = parse_args() print("Input1={}".format(args.input1)) print("Output1={}".format(args.output1)) # 根據已配置的全域變數,新增代碼。 print("Argument1={}".format(args.arg1)) print("Argument2={}".format(args.arg2)) # write_table_example(args) # write_output1(args)