Notebook Lab 提供了一個輕量化編輯器,讓您無需啟動任何計算資源,即可預覽和編輯儲存在Object Storage Service上的Notebook檔案。當需要運行時,再將Notebook串連到DSW執行個體。這種模式允許多個Notebook共用同一個執行個體,從而顯著提升DSW執行個體的資源使用率。
與DSW的區別
功能對比 | Notebook Lab | DSW 執行個體 |
核心理念 | 輕量級 Notebook 編輯器,多個Notebook共用同一個執行個體 | 完整的 AI 開發環境 |
檔案儲存體 | 儲存在Object Storage Service,與計算解耦 | 與執行個體的工作目錄綁定 |
計費模式 | 編輯不計費 | 執行個體啟動即計費 |
工具集 | 專註於 Notebook 編寫 | 包含 Notebook、WebIDE、Terminal |
快速入門
步驟一:進入Notebook
登入PAI控制台,左上方選擇目標地域。
在左側導覽列選擇工作空间列表,單擊目標工作空間名稱進入工作空間。
在左側導覽列選擇模型开发与训练 > 交互式建模(DSW),單擊Notebook頁簽。
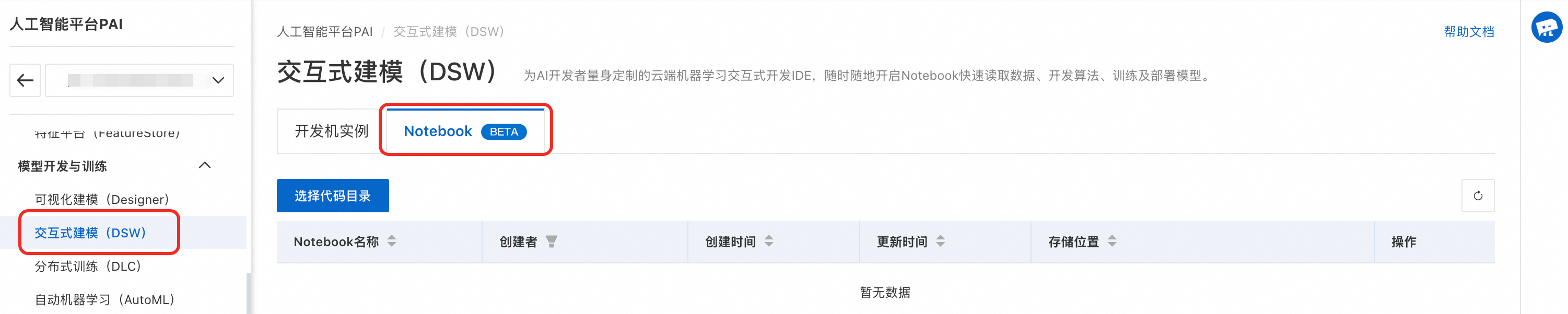
步驟二:選擇代碼目錄
單擊选择代码目录,選擇Object Storage ServiceBucket,建立目錄如:notebook_test並選擇。該目錄後續用於儲存Notebook檔案。代碼目錄配置完成後,Notebook列表會掃描該目錄,並列出OSS路徑下所有的Notebook檔案(*.ipynb檔案)。
步驟三:建立Notebook並開發代碼
單擊创建实例會進入Notebook開發環境,並會建立一個Notebook檔案。
編輯代碼。單擊+Python添加Python代碼儲存格,之後您即可在儲存格中開發代碼。

程式碼範例如下:
說明先安裝依賴包:由於Notebook檔案和DSW執行個體相互分離,因此建議您將環境依賴的下載安裝邏輯都寫在Notebook檔案中,以便於切換不同的DSW執行個體時都能正常運行。
注意儲存代碼:Notebook Lab預設不會自動儲存代碼,修改代碼後請及時儲存代碼。
步驟四:關聯DSW執行個體並運行代碼
單擊關聯DSW,然後選擇處於運行狀態的執行個體。多個Notebook可以關聯同一個DSW執行個體,提升資源使用效率。
單擊
 表徵圖運行代碼。
表徵圖運行代碼。
如果Notebook右上方選擇核心處無法載入核心,請嘗試重新整理瀏覽器重新載入環境。
範例程式碼輸出:
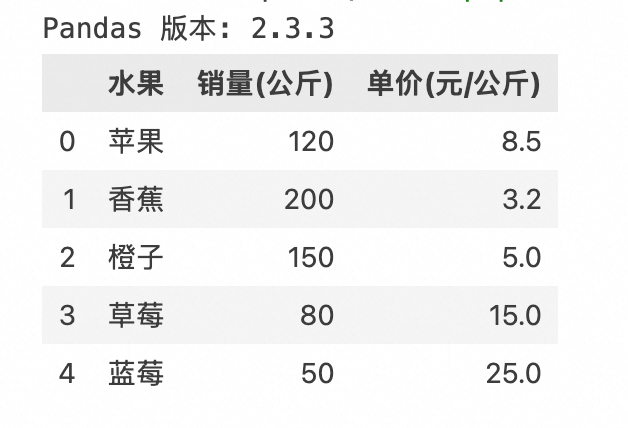
及時停止DSW執行個體:如果您建立的是隨用隨付執行個體,執行個體處於運行中狀態即開始按運行時間長度計費,即使您不開啟WebIDE或者運行代碼。當不需要使用DSW時請及時停止或刪除執行個體,以免繼續計費。
使用Copilot輔助編程
您可以使用Copilot功能輔助編程,觸發Copilot方式如下:
方式一:通過Notebook Lab工具列單擊產生按鈕觸發Copilot。

方式二:選中儲存格後,使用以下快速鍵:

Windows系統:
Ctrl+ImacOS系統:
Command+I
運行MaxCompute SQL
安裝依賴包。請先添加一個Python儲存格並執行如下命令:
!pip install https://dataworks-notebook-cn-shanghai.oss-cn-shanghai.aliyuncs.com/public-datasets/pypi/dataworks-magic/dataworks_magic-0.1.5-py3-none-any.whl jupysql tenacity sqlparse maxframe alibabacloud_emr_serverless_spark20230808 alibabacloud_ververica20220718 psycopg2-binary綁定MaxCompute資源。
單擊頂部工具列+SQL建立一個SQL節點,或者在建立的Python代碼節點右下角單擊切換為MaxCompute SQL。

綁定計算資源。單擊請選擇計算資源,然後單擊綁定計算資源,跳轉至DataWorks完成綁定計算資源。

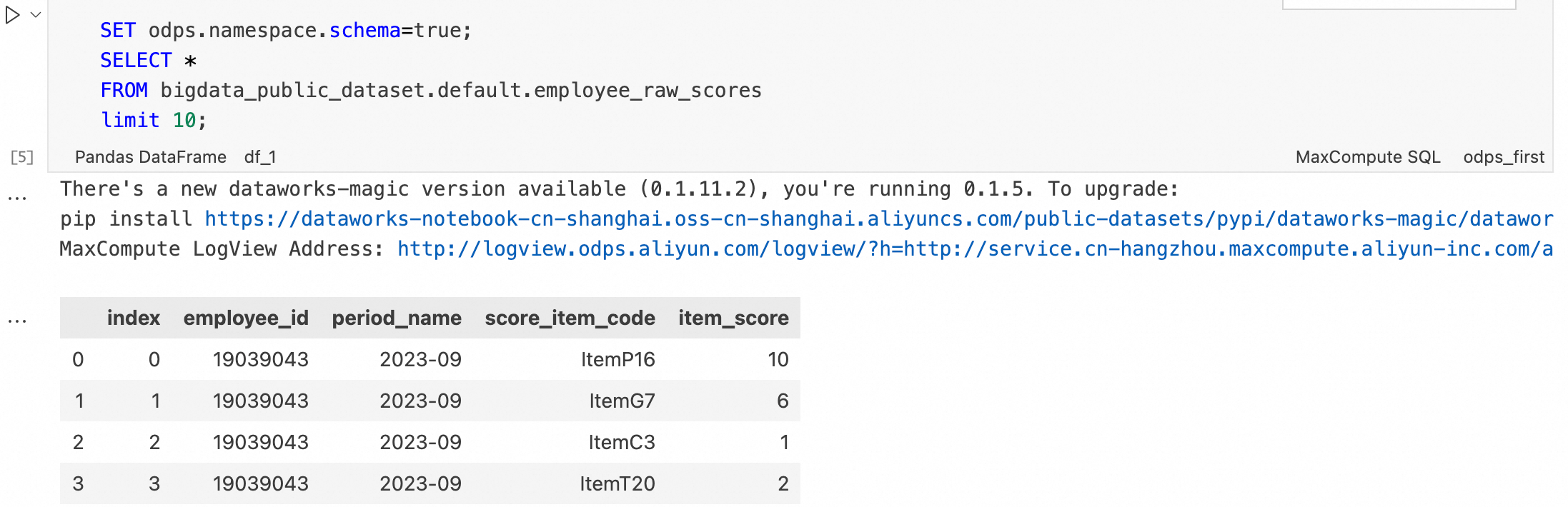
編寫SQL運行儲存格。如下為使用公用資料集的測試SQL。
SET odps.namespace.schema=true; SELECT * FROM bigdata_public_dataset.default.employee_raw_scores limit 10;運行結果:
計費說明
在Notebook Lab中編寫代碼不產生費用,當關聯了運行中DSW執行個體時,按DSW計費規則計費,詳情請參見互動式建模(DSW)計費說明。
如果使用了MaxCompute資源運行SQL,則按MaxCompute計費規則計費,詳情請參見MaxCompute計費概述。