邊聚類係數(Edge Clustering Coefficient)用于衡量網路中一條邊在其鄰域內形成三角形閉合程度的指標。具體而言,它通過計算串連兩個節點的邊在共同鄰置中形成三角形的比例來實現。該係數有助於理解網路的局部聚集模式和群體結構,廣泛應用於社交網路分析和社區檢測等領域。
配置組件
方法一:可視化方式
在Designer工作流程頁面添加邊聚類係數組件,並在介面右側配置相關參數:
參數類型 | 參數 | 描述 |
欄位設定 | 起始節點 | 邊表的起點所在列。 |
終止節點 | 邊表的終點所在列。 | |
執行調優 | 進程數量 | 作業並存執行的節點數。數字越大並行度越高,但是架構通訊開銷會增大。 |
進程記憶體 | 單個作業可使用的最大記憶體量,單位:MB,預設值為4096。 如果實際使用記憶體超過該值,會拋出 | |
資料切分大小 | 資料切分的大小,單位:MB,預設值為64。 |
方法二:PAI命令方式
使用PAI命令配置邊聚類係數組件參數。您可以使用SQL指令碼組件進行PAI命令調用,詳情請參見情境4:在SQL指令碼組件中執行PAI命令。
PAI -name EdgeDensity
-project algo_public
-DinputEdgeTableName=EdgeDensity_func_test_edge
-DfromVertexCol=flow_out_id
-DtoVertexCol=flow_in_id
-DoutputTableName=EdgeDensity_func_test_result;參數 | 是否必選 | 預設值 | 描述 |
inputEdgeTableName | 是 | 無 | 輸入邊表名。 |
inputEdgeTablePartitions | 否 | 全表讀入 | 輸入邊表的分區。 |
fromVertexCol | 是 | 無 | 輸入邊表的起點所在列。 |
toVertexCol | 是 | 無 | 輸入邊表的終點所在列。 |
outputTableName | 是 | 無 | 輸出表名。 |
outputTablePartitions | 否 | 無 | 輸出表的分區。 |
lifecycle | 否 | 無 | 輸出表的生命週期。 |
workerNum | 否 | 未設定 | 作業並存執行的節點數。數字越大並行度越高,但是架構通訊開銷會增大。 |
workerMem | 否 | 4096 | 單個作業可使用的最大記憶體量,單位:MB,預設值為4096。 如果實際使用記憶體超過該值,會拋出 |
splitSize | 否 | 64 | 資料切分的大小,單位:MB。 |
使用樣本
添加SQL指令碼組件,去勾選使用Script模式和是否由系統添加Create Table語句,並在SQL指令碼中輸入以下SQL語句。
drop table if exists EdgeDensity_func_test_edge; create table EdgeDensity_func_test_edge as select * from ( select '1' as flow_out_id,'2' as flow_in_id union all select '1' as flow_out_id,'3' as flow_in_id union all select '1' as flow_out_id,'5' as flow_in_id union all select '1' as flow_out_id,'7' as flow_in_id union all select '2' as flow_out_id,'5' as flow_in_id union all select '2' as flow_out_id,'4' as flow_in_id union all select '2' as flow_out_id,'3' as flow_in_id union all select '3' as flow_out_id,'5' as flow_in_id union all select '3' as flow_out_id,'4' as flow_in_id union all select '4' as flow_out_id,'5' as flow_in_id union all select '4' as flow_out_id,'8' as flow_in_id union all select '5' as flow_out_id,'6' as flow_in_id union all select '5' as flow_out_id,'7' as flow_in_id union all select '5' as flow_out_id,'8' as flow_in_id union all select '7' as flow_out_id,'6' as flow_in_id union all select '6' as flow_out_id,'8' as flow_in_id )tmp; drop table if exists EdgeDensity_func_test_result; create table EdgeDensity_func_test_result ( node1 string, node2 string, node1_edge_cnt bigint, node2_edge_cnt bigint, triangle_cnt bigint, density double );對應的資料結構圖:
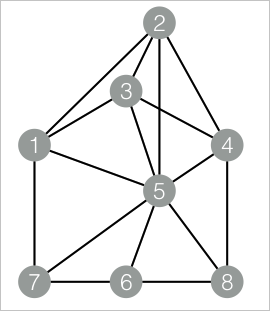
添加SQL指令碼組件,去勾選使用Script模式和是否由系統添加Create Table語句,在SQL指令碼中輸入以下PAI命令,並將步驟 1和步驟 2的組件進行連線。
drop table if exists ${o1}; PAI -name EdgeDensity -project algo_public -DinputEdgeTableName=EdgeDensity_func_test_edge -DfromVertexCol=flow_out_id -DtoVertexCol=flow_in_id -DoutputTableName=${o1};單擊左上方
 ,運行工作流程。
,運行工作流程。待運行結束,按右鍵步驟 2的組件,選擇查看資料 > SQL指令碼的輸出,查看訓練結果。
| node1 | node2 | node1_edge_cnt | node2_edge_cnt | triangle_cnt | density | | ----- | ----- | -------------- | -------------- | ------------ | ------- | | 3 | 1 | 4 | 4 | 2 | 0.5 | | 5 | 1 | 7 | 4 | 3 | 0.75 | | 7 | 1 | 3 | 4 | 1 | 0.33333 | | 1 | 2 | 4 | 4 | 2 | 0.5 | | 4 | 2 | 4 | 4 | 2 | 0.5 | | 2 | 3 | 4 | 4 | 3 | 0.75 | | 5 | 3 | 7 | 4 | 3 | 0.75 | | 3 | 4 | 4 | 4 | 2 | 0.5 | | 8 | 4 | 3 | 4 | 1 | 0.33333 | | 2 | 5 | 4 | 7 | 3 | 0.75 | | 4 | 5 | 4 | 7 | 3 | 0.75 | | 7 | 5 | 3 | 7 | 2 | 0.66667 | | 5 | 6 | 7 | 3 | 2 | 0.66667 | | 8 | 6 | 3 | 3 | 1 | 0.33333 | | 6 | 7 | 3 | 3 | 1 | 0.33333 | | 5 | 8 | 7 | 3 | 2 | 0.66667 |