Triton Inference Server 是由 NVIDIA 開發的一款適用於深度學習與機器學習模型的推理服務引擎,支援將TensorRT、TensorFlow、PyTorch或ONNX等多種AI架構的模型部署為線上推理服務,並支援多模型管理、自訂backend等功能。本文介紹如何在PAI-EAS上部署基於 Triton 的推理服務。
前提條件
與 PAI 同地區的Object Storage Service Bucket。
已訓練好的模型檔案(如
.pt、.onnx、.plan、.savedmodel)。
快速入門:部署單模型服務
步驟一:準備模型倉庫
Triton 要求在Object Storage Service Bucket 中使用特定的目錄結構。請按以下格式建立目錄。具體操作請參見管理目錄及上傳檔案。
oss://your-bucket/models/triton/
└── your_model_name/
├── 1/ # 版本目錄(必須為數字)
│ └── model.pt # 模型檔案
└── config.pbtxt # 模型設定檔
關鍵要求:
版本目錄必須使用數字命名(
1、2、3等)。數字越大表示版本越新。
每個模型都需要一個
config.pbtxt設定檔。
步驟二:建立模型設定檔
建立 config.pbtxt 檔案,配置模型的基礎資訊,樣本如下:
name: "your_model_name"
platform: "pytorch_libtorch"
max_batch_size: 128
input [
{
name: "INPUT__0"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]
# 使用GPU推理
# instance_group [
# {
# kind: KIND_GPU
# }
# ]
# 模型版本配置
# 僅載入最新版本(預設行為)
# version_policy: { latest: { num_versions: 1 }}
# 載入所有版本
# version_policy: { all { }}
# 載入最新的兩個版本
# version_policy: { latest: { num_versions: 2 }}
# 載入指定版本
# version_policy: { specific: { versions: [1, 3] }}配置參數說明
參數 | 是否必選 | 說明 |
| 否 | 模型名稱。如指定,必須與模型目錄名一致。 |
| 是 | 模型架構。可選值: |
| 是 |
|
| 是 | 最大批處理大小。設為 |
| 是 | 輸入張量配置: |
| 是 | 輸出張量配置: |
| 否 | 指定推理裝置: |
| 否 | 控制載入哪些模型版本(配置樣本見前文 |
platform 和 backend 至少配置一項。
步驟三:部署服務
步驟四:啟用gRPC(可選)
預設情況下,Triton 在連接埠 8000 提供 HTTP 服務。如需使用 gRPC:
單擊服務配置頁面右上方的切换为自定义部署。
在环境信息地區,將端口号修改為
8001。在服务功能 > 高级网络下,啟用gRPC。
單擊部署。
模型部署成功後即可調用服務。
部署多模型服務
如需在單個 Triton 執行個體中部署多個模型,只需將多個模型放在同一倉庫目錄下:
oss://your-bucket/models/triton/
├── resnet50_pytorch/
│ ├── 1/
│ │ └── model.pt
│ └── config.pbtxt
├── densenet_onnx/
│ ├── 1/
│ │ └── model.onnx
│ └── config.pbtxt
└── classifier_tensorflow/
├── 1/
│ └── model.savedmodel/
│ ├── saved_model.pb
│ └── variables/
└── config.pbtxt
部署步驟與單模型相同。Triton 會自動載入倉庫中的所有模型。
使用Python Backend自訂推理邏輯
當您需要自訂預先處理、後處理或推理邏輯時,可以使用 Triton 的 Python Backend。
目錄結構
your_model_name/
├── 1/
│ ├── model.pt # 模型檔案
│ └── model.py # 自訂推理邏輯
└── config.pbtxt
實現Python Backend
建立 model.py 檔案,定義 TritonPythonModel 類:
import json
import os
import torch
from torch.utils.dlpack import from_dlpack, to_dlpack
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
"""必須以 "TritonPythonModel" 為類名"""
def initialize(self, args):
"""
初始化函數,可選實現,在載入模型時被調用一次,可用於初始化與模型屬性、模型配置相關的資訊。
Parameters
----------
args : 字典類型,其中keys和values都為string 類型,具體包括:
* model_config:JSON格式模型配置資訊。
* model_instance_kind:裝置型號。
* model_instance_device_id:裝置ID。
* model_repository:模型倉庫路徑。
* model_version:模型版本。
* model_name:模型名。
"""
# 將JSON字串類型的模型配置內容轉為Python的字典類型。
self.model_config = model_config = json.loads(args["model_config"])
# 擷取模型設定檔中的屬性。
output_config = pb_utils.get_output_config_by_name(model_config, "OUTPUT__0")
# 將Triton types轉為numpy types。
self.output_dtype = pb_utils.triton_string_to_numpy(output_config["data_type"])
# 擷取模型倉庫的路徑。
self.model_directory = os.path.dirname(os.path.realpath(__file__))
# 擷取模型推理使用的裝置,本例中使用GPU。
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device: ", self.device)
model_path = os.path.join(self.model_directory, "model.pt")
if not os.path.exists(model_path):
raise pb_utils.TritonModelException("Cannot find the pytorch model")
# 通過.to(self.device)將pytorch模型載入到GPU上。
self.model = torch.jit.load(model_path).to(self.device)
print("Initialized...")
def execute(self, requests):
"""
模型執行函數,必須實現;每次請求推理都會調用該函數,若設定了 batch 參數,還需由使用者自行實現批處理功能
Parameters
----------
requests : pb_utils.InferenceRequest類型的請求列表。
Returns
-------
pb_utils.InferenceResponse 類型的返回列表。列表長度必須與請求列表一致。
"""
output_dtype = self.output_dtype
responses = []
# 遍曆request列表,並為每個請求都建立對應的response。
for request in requests:
# 擷取輸入tensor。
input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT__0")
# 將Triton tensor轉換為Torch tensor。
pytorch_tensor = from_dlpack(input_tensor.to_dlpack())
if pytorch_tensor.shape[2] > 1000 or pytorch_tensor.shape[3] > 1000:
responses.append(
pb_utils.InferenceResponse(
output_tensors=[],
error=pb_utils.TritonError(
"Image shape should not be larger than 1000"
),
)
)
continue
# 在GPU上進行推理計算。
prediction = self.model(pytorch_tensor.to(self.device))
# 將Torch output tensor轉換為Triton tensor。
out_tensor = pb_utils.Tensor.from_dlpack("OUTPUT__0", to_dlpack(prediction))
inference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor])
responses.append(inference_response)
return responses
def finalize(self):
"""
模型卸載時調用,可選實現,可用於模型清理工作。
"""
print("Cleaning up...")
當使用Python Backend時,Triton的某些行為會發生改變,請務必注意:
max_batch_size失效:config.pbtxt中的max_batch_size參數對Python Backend的動態批處理無效。您必須在execute方法中自行遍曆requests列表,手動拼接Batch進行推理。instance_group失效:config.pbtxt中的instance_group無法控制Python Backend使用CPU或GPU。您必須在initialize和execute方法中,通過代碼(如pytorch_tensor.to(torch.device("cuda")))顯式地將模型和資料移動到目標裝置。
更新設定檔
name: "resnet50_pt"
backend: "python"
max_batch_size: 128
input [
{
name: "INPUT__0"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]
parameters: {
key: "FORCE_CPU_ONLY_INPUT_TENSORS"
value: {string_value: "no"}
}其中關鍵參數說明如下:
backend:需指定為python。
parameters:可選配置,當模型推理使用GPU時,可將
FORCE_CPU_ONLY_INPUT_TENSORS參數設定為no,來避免推理計算時輸入Tensor在CPU與GPU之間來回拷貝產生不必要的開銷。
部署服務
使用Python backend必須設定共用記憶體。在填寫如下JSON配置並部署,即可實現自訂模型推理邏輯。
{
"metadata": {
"name": "triton_server_test",
"instance": 1
},
"cloud": {
"computing": {
"instance_type": "ml.gu7i.c8m30.1-gu30",
"instances": null
}
},
"containers": [
{
"command": "tritonserver --model-repository=/models",
"image": "eas-registry-vpc.<region>.cr.aliyuncs.com/pai-eas/tritonserver:25.03-py3",
"port": 8000,
"prepare": {
"pythonRequirements": [
"torch==2.0.1"
]
}
}
],
"storage": [
{
"mount_path": "/models",
"oss": {
"path": "oss://oss-test/models/triton_backend/"
}
},
{
"empty_dir": {
"medium": "memory",
// 配置共用記憶體為1 GB。
"size_limit": 1
},
"mount_path": "/dev/shm"
}
]
}關鍵JSON配置說明:
containers[0].image: Triton官方鏡像。請將cn-hangzhou替換為您服務所在的地區。containers[0].prepare.pythonRequirements: 在此列出您的Python依賴庫,EAS會在服務啟動前自動安裝。storage: 包含兩個掛載項。第一個將您的OSS模型倉庫路徑掛載到容器的
/models目錄。第二個是必須配置的共用記憶體。Triton Server與Python Backend進程之間通過共用記憶體
/dev/shm傳遞張量資料以實現零拷貝,從而最大化效能。size_limit單位為GB,請根據模型和並發量估算所需大小。
調用服務
擷取服務端點和Token
進入模型在线服务(EAS)頁面,單擊服務名稱。
在服务详情頁簽,單擊查看调用信息,複製公网调用地址和Token。
發送HTTP請求
連接埠號碼配置為8000時,服務支援發送HTTP請求。
import numpy as np
# 安裝tritonclient包請執行命令:pip install tritonclient
import tritonclient.http as httpclient
# 服務部署後產生訪問地址(服務端點),不帶http://
url = '1859257******.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/triton_server_test'
triton_client = httpclient.InferenceServerClient(url=url)
image = np.ones((1,3,224,224))
image = image.astype(np.float32)
inputs = []
inputs.append(httpclient.InferInput('INPUT__0', image.shape, "FP32"))
inputs[0].set_data_from_numpy(image, binary_data=False)
outputs = []
outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False)) # 擷取 1000 維的向量
# 指定模型名稱、請求Token、輸入輸出。
results = triton_client.infer(
model_name="<your-model-name>",
model_version="<version-num>",
inputs=inputs,
outputs=outputs,
headers={"Authorization": "<your-service-token>"},
)
output_data0 = results.as_numpy('OUTPUT__0')
print(output_data0.shape)
print(output_data0)發送gRPC請求
連接埠號碼配置為8001,並添加gRPC相關配置後,服務支援發送gRPC請求。
注意:gRPC的訪問地址和HTTP的不相同,請重新從服務詳情頁面擷取。
#!/usr/bin/env python
import grpc
# 安裝tritonclient包請執行命令:pip install tritonclient
from tritonclient.grpc import service_pb2, service_pb2_grpc
import numpy as np
if __name__ == "__main__":
# 服務部署後產生訪問地址(服務端點),不帶http://,末尾添加“:80”
host = (
"service_name.115770327099****.cn-beijing.pai-eas.aliyuncs.com:80"
)
# 服務Token,實際應用中應使用真實的Token。
token = "<your-service-token>"
# 模型名稱和版本。
model_name = "<your-model-name>"
model_version = "<version-num>"
# 建立gRPC中繼資料,用於Token驗證。
metadata = (("authorization", token),)
# 建立gRPC通道和存根,用於與伺服器通訊。
channel = grpc.insecure_channel(host)
grpc_stub = service_pb2_grpc.GRPCInferenceServiceStub(channel)
# 構建推理請求。
request = service_pb2.ModelInferRequest()
request.model_name = model_name
request.model_version = model_version
# 構造輸入張量,對應模型設定檔中定義的輸入參數。
input = service_pb2.ModelInferRequest().InferInputTensor()
input.name = "INPUT__0"
input.datatype = "FP32"
input.shape.extend([1, 3, 224, 224])
# 構造輸出張量,對應模型設定檔中定義的輸出參數。
output = service_pb2.ModelInferRequest().InferRequestedOutputTensor()
output.name = "OUTPUT__0"
# 建立輸入請求。
request.inputs.extend([input])
request.outputs.extend([output])
# 構造隨機數組並序列化為位元組序列,作為輸入資料。
request.raw_input_contents.append(np.random.rand(1, 3, 224, 224).astype(np.float32).tobytes()) #數實值型別
# 發起推理請求,並接收響應。
response, _ = grpc_stub.ModelInfer.with_call(request, metadata=metadata)
# 提取響應中的輸出張量。
output_contents = response.raw_output_contents[0] # 假設只有一個輸出張量。
output_shape = [1, 1000] # 假設輸出張量的形狀是[1, 1000]。
# 將輸出位元組轉換為numpy數組。
output_array = np.frombuffer(output_contents, dtype=np.float32)
output_array = output_array.reshape(output_shape)
# 列印模型的輸出結果。
print("Model output:\n", output_array)調試技巧
啟用詳細日誌
設定 verbose=True 可列印請求和響應的 JSON 資料:
client = httpclient.InferenceServerClient(url=url, verbose=True)
輸出樣本:
POST /api/predict/triton_test/v2/models/resnet50_pt/versions/1/infer, headers {'Authorization': '************1ZDY3OTEzNA=='}
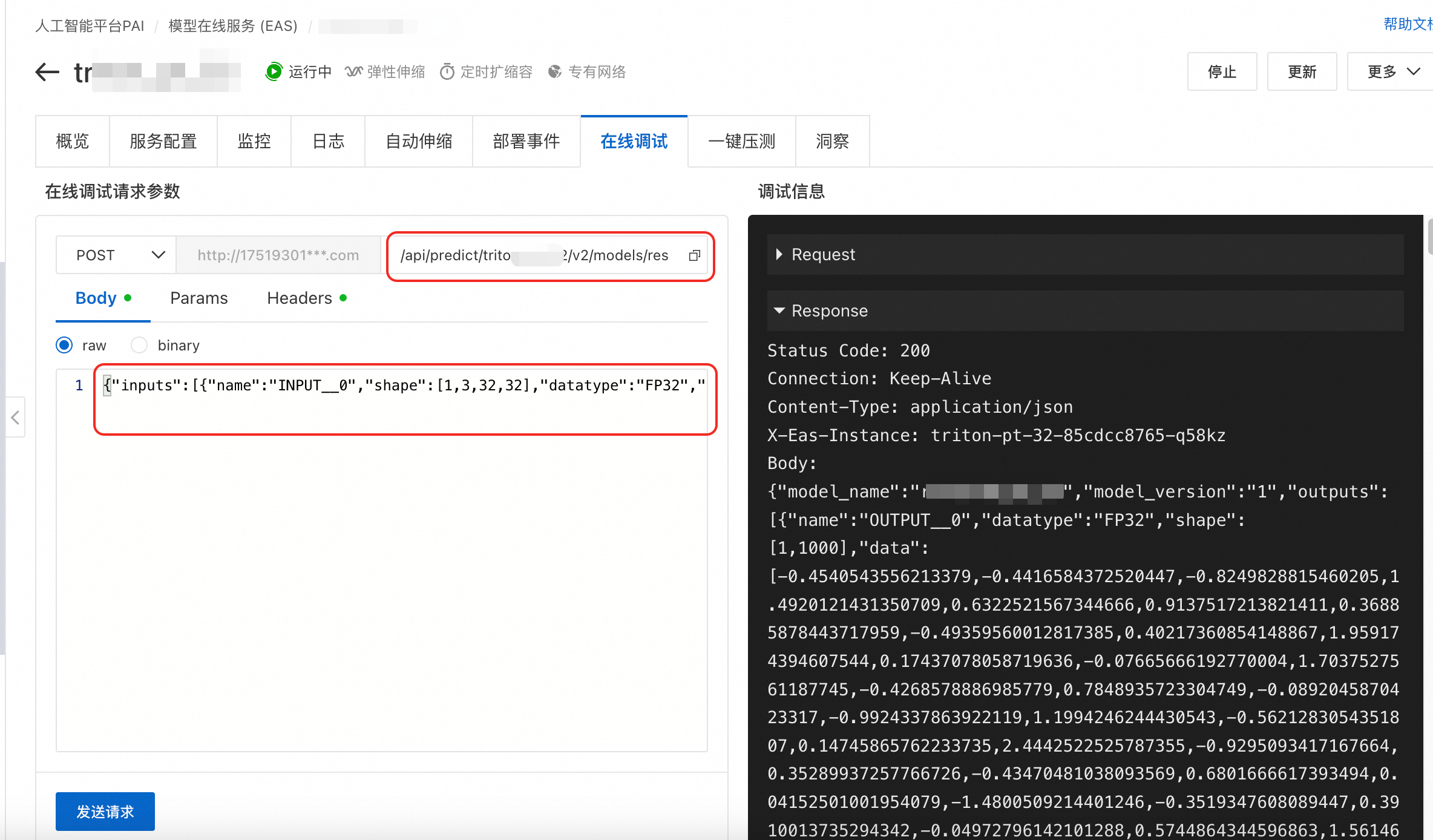
b'{"inputs":[{"name":"INPUT__0","shape":[1,3,32,32],"datatype":"FP32","data":[1.0,1.0,1.0,.....,1.0]}],"outputs":[{"name":"OUTPUT__0","parameters":{"binary_data":false}}]}'線上調試
可以直接在控制台的線上調試功能中進行測試,請求地址補全為/api/predict/triton_test/v2/models/resnet50_pt/versions/1/infer,Body使用詳細日誌中的 JSON 請求資料。
壓測服務
以單個資料壓測為例,操作步驟如下,更多壓測說明請參見通用情境服務壓測:
在壓測任務頁簽,單擊添加壓測任務,選擇已部署的Triton服務,並填寫壓測地址。
資料來源選擇單個資料,並參考如下代碼將JSON請求體轉換為Base64編碼的字串。
import base64 # 已有的 JSON 請求體字串 json_str = '{"inputs":[{"name":"INPUT__0","shape":[1,3,32,32],"datatype":"FP32","data":[1.0,1.0,.....,1.0]}]}' # 直接編碼 base64_str = base64.b64encode(json_str.encode('utf-8')).decode('ascii') print(base64_str)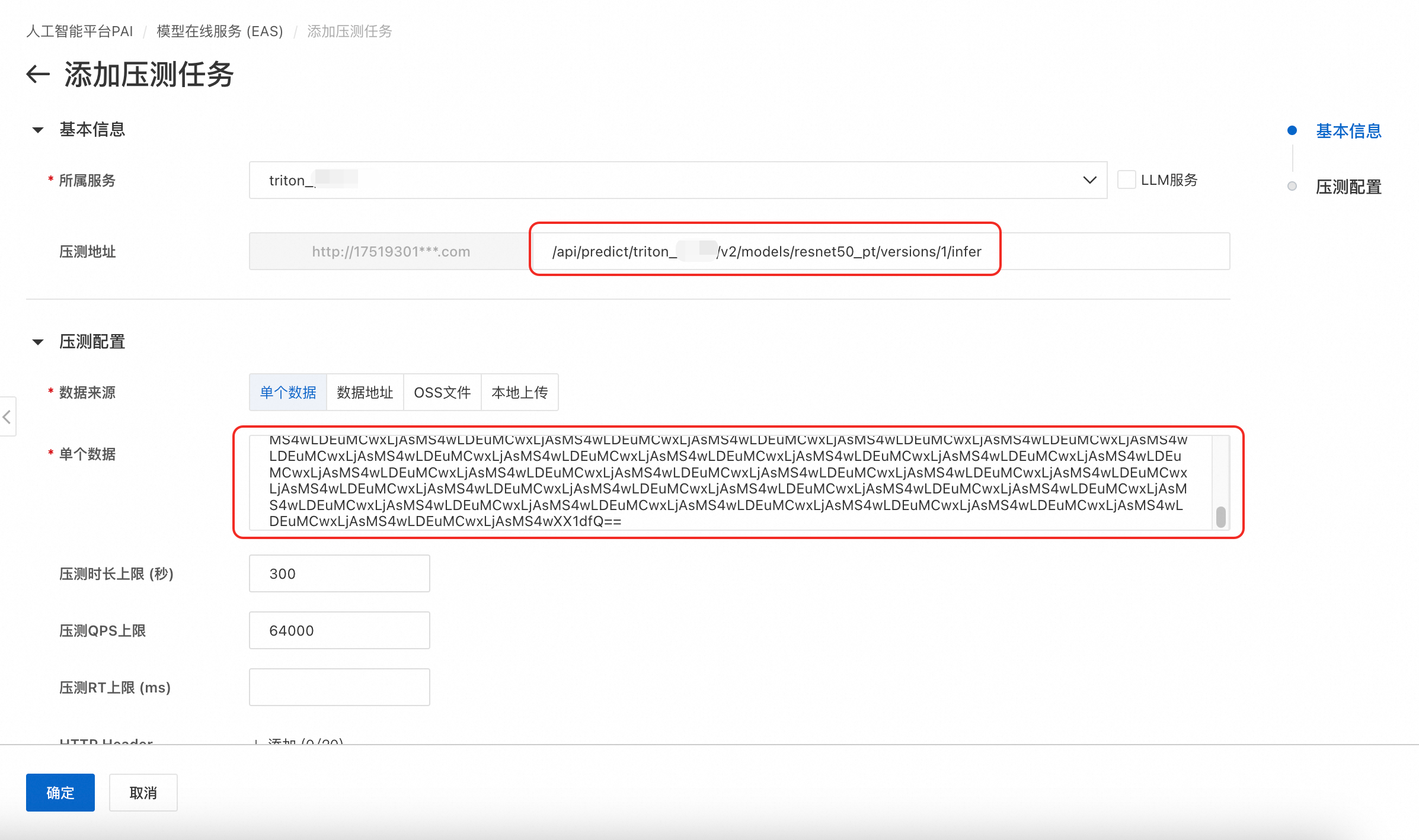
常見問題
Q:出現報錯:CUDA error: no kernel image is available for execution on the device,怎麼辦?
出現該報錯的原因是鏡像版本與GPU的相容性問題,您可以嘗試更換其他GPU型號的規格,如:A10、T4。
Q:使用HTTP調用報錯:tritonclient.utils.InferenceServerException: url should not include the scheme,怎麼解決?
出現該報錯的原因是服務的url填寫錯誤。擷取服務端點的格式為:http://17519301*******.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/wen*****(注意,其與gRPC的訪問地址不同),請去掉開頭的http://。
Q:使用gRPC調用報錯:DNS resolution failed for wenyu****.175193***43.cn-hangzhou.pai-eas.aliyuncs.com/:80,怎麼解決?
出現該報錯的原因是服務的host填寫錯誤。擷取服務端點的格式為:http://we*****.1751930*****.cn-hangzhou.pai-eas.aliyuncs.com/(注意,其與HTTP的訪問地址不同),請去掉開頭的http:// 以及末尾的/,然後在末尾補:80,最終變成:we*****.1751930*****.cn-hangzhou.pai-eas.aliyuncs.com:80。
相關文檔
如何基於TensorFlow Serving推理服務引擎部署EAS服務,請參見TensorFlow Serving鏡像部署。
您也可以開發自訂鏡像,使用自訂鏡像部署EAS服務。具體操作,請參見自訂鏡像。
更多NVIDIA Triton資訊,請參見Triton官方文檔。