Responsible AI對人工智慧模型(AI模型)開發人員和企業管理者十分重要,Responsible AI貫穿在AI模型的開發、訓練、微調、評估、部署等環節,是保障AI模型安全、穩定、公平、符合社會道德的重要方法。PAI已支援使用者在DSW中整合Responsible AI的相關工具對產出的AI模型進行公平性分析、錯誤分析及可解釋性分析。
原理介紹
公平性分析是Responsible AI的一部分,它專註於識別和糾正AI系統中的偏見,確保模型不會受到某一不合理因素的影響,從而保證AI系統對所有人都是公平的。公平性分析的核心原理如下:
避免偏見:識別和減少資料和演算法中的偏見,確保AI系統不會因性別、種族、年齡等個人特徵而導致不公平的決策。
代表性資料:使用代表性資料集練習AI模型,這樣模型就可以準確地代表和服務於所有使用者群體,同時確保少數群體不會被邊緣化。
透明度和解釋性:增加AI系統的透明度,通過可解釋的AI技術,讓終端使用者和決策者理解AI決策過程和輸出的原因。
持續監控和評估:定期監控和評估AI系統,以識別和糾正可能隨時間出現的任何不公平的偏差或做出的決策。
多樣性和包容性:在AI系統的設計和開發過程中納入多樣性和包容性的觀念,確保從多種背景和觀點出發考慮問題,包括團隊構成的多樣性。
合規性和道德原則:遵守相關的法律法規和道德標準,包括對人權的尊重,以及確保AI應用不會造成傷害或不公。
本文以“評估一個預測年度營收是否大於50K的模型在性別、種族因素的公平性”為例,介紹了如何在阿里雲PAI的DSW產品中使用responsible-ai-toolbox對模型進行公平性分析。
準備環境和資源
DSW執行個體:如果您還沒有DSW執行個體,請參見建立DSW執行個體。推薦配置如下:
推薦執行個體規格:ecs.gn6v-c8g1.2xlarge
鏡像選擇:建議使用Python3.9及以上版本。本文選擇的官方鏡像為:tensorflow-pytorch-develop:2.14-pytorch2.1-gpu-py311-cu118-ubuntu22.04
模型選擇:responsible-ai-toolbox支援Sklearn、PyTorch和TensorFlow架構的迴歸和二分類模型。
訓練資料集:推薦您使用自己的資料集;如果您需要使用樣本資料集,請按步驟三:準備資料集操作。
演算法模型:推薦您使用自己的演算法模型;如果您需要使用樣本演算法模型,請按步驟五:模型訓練操作。
步驟一:進入DSW Gallery
登入PAI控制台。
在頂部左上方根據實際情況選擇地區。
在左側導覽列選擇快速開始 > Notebook Gallery,搜尋Responsible AI-公平性分析,並單擊對應卡片上的在DSW中開啟。
選擇DSW執行個體,單擊開啟Notebook,系統會開啟Responsible AI-公平性分析Notebook案例。
步驟二:匯入依賴包
安裝responsible-ai-toolbox的依賴包(raiwidgets),用於後續的評估。
!pip install raiwidgets==0.34.1步驟三:準備資料集
您可以直接執行以下指令碼載入OpenML的1590資料集,以完成本文的樣本。
from raiutils.common.retries import retry_function
from sklearn.datasets import fetch_openml
class FetchOpenml(object):
def __init__(self):
pass
# 擷取 data_id = 1590的OpenML資料集
def fetch(self):
return fetch_openml(data_id=1590, as_frame=True)
fetcher = FetchOpenml()
action_name = "Dataset download"
err_msg = "Failed to download openml dataset"
max_retries = 5
retry_delay = 60
data = retry_function(fetcher.fetch, action_name, err_msg,
max_retries=max_retries,
retry_delay=retry_delay)您也可以載入自己的資料集,CSV格式的資料集對應的指令如下:
import pandas as pd
# 載入自己的資料集,csv 格式資料集
# 使用pandas讀取CSV檔案
data = pd.read_csv(filename)步驟四:資料預先處理
擷取特徵變數和目標變數
目標變數是指模型預測的真實結果,特徵變數是指每條執行個體資料中目標變數以外的變數。在本文樣本中,目標變數是“class”,特徵變數是“sex、race、age……”:
class:年度營收是否大於50K
sex:性別
race:種族
age:年齡
執行以下指令碼,讀取資料到X_raw,並查看一部分樣本資料:
# 擷取特徵變數,不包括目標變數。
X_raw = data.data
# 展示特徵變數的前5行資料,不包括目標變數。
X_raw.head(5)執行以下指令碼,設定目標變數的值,並查看一部分樣本資料。其中,“1”表示收入>50K,“0”表示收入≤50K。
from sklearn.preprocessing import LabelEncoder
# 轉換目標變數,轉換為二分類目標
# data.target 是目標變數是“class”
y_true = (data.target == '>50K') * 1
y_true = LabelEncoder().fit_transform(y_true)
import matplotlib.pyplot as plt
import numpy as np
# 查看目標變數的分布
counts = np.bincount(y_true)
classes = ['<=50K', '>50K']
plt.bar(classes, counts)擷取特徵敏感特徵
執行以下指令碼,將性別(sex)、種族(race)設定為敏感特徵,並查看一部分樣本資料。responsible-ai-toolbox會評估該模型的推理結果是否因為這兩個敏感特徵產生偏見。在實際使用時,您可以按業務需要設定敏感特徵。
# 定義“性別”和“種族”為敏感資訊
# 首先從資料集中選取敏感資訊相關的列,組成新的Dataframe `sensitive_features`
sensitive_features = X_raw[['sex','race']]
sensitive_features.head(5)執行以下指令碼,刪除X_raw中的敏感特徵及資料,並查看刪除後的樣本資料。
# 將特徵變數中的敏感特徵刪除
X = X_raw.drop(labels=['sex', 'race'],axis = 1)
X.head(5)特徵編碼和標準化
執行以下指令碼,對資料進行標準化處理,轉換為適合responsible-ai-toolbox使用的格式。
import pandas as pd
from sklearn.preprocessing import StandardScaler
# one-hot 編碼
X = pd.get_dummies(X)
# 對資料集X進行特徵標準化(scaling)
sc = StandardScaler()
X_scaled = sc.fit_transform(X)
X_scaled = pd.DataFrame(X_scaled, columns=X.columns)
X_scaled.head(5)劃分訓練和測試資料
執行以下指令碼,將20%的資料劃分為測試資料集,剩餘資料為訓練資料集。
from sklearn.model_selection import train_test_split
# 按照`test_size`比例,將特徵變數X和目標變數y劃分為訓練集和測試集
X_train, X_test, y_train, y_test = \
train_test_split(X_scaled, y_true, test_size=0.2, random_state=0, stratify=y_true)
# 使用相同的隨機種子,將敏感特徵劃分為訓練集和測試集,確保與上述劃分保持一致
sensitive_features_train, sensitive_features_test = \
train_test_split(sensitive_features, test_size=0.2, random_state=0, stratify=y_true)分別查看訓練資料集、測試資料集的資料量。
print("訓練資料集的資料量:", len(X_train))
print("測試資料集的資料量:", len(X_test))分別重設訓練資料集、測試資料集的索引。
# 重設 DataFrame 的索引,避免索引錯誤問題
X_train = X_train.reset_index(drop=True)
sensitive_features_train = sensitive_features_train.reset_index(drop=True)
X_test = X_test.reset_index(drop=True)
sensitive_features_test = sensitive_features_test.reset_index(drop=True)步驟五:模型訓練
本文樣本中,基於Sklearn使用訓練資料訓練一個羅吉斯迴歸模型。
Sklearn
from sklearn.linear_model import LogisticRegression
# 建立羅吉斯迴歸模型
sk_model = LogisticRegression(solver='liblinear', fit_intercept=True)
# 模型訓練
sk_model.fit(X_train, y_train)PyTorch
import torch
import torch.nn as nn
import torch.optim as optim
# 定義羅吉斯迴歸模型
class LogisticRegression(nn.Module):
def __init__(self, input_size):
super(LogisticRegression, self).__init__()
self.linear = nn.Linear(input_size, 1)
def forward(self, x):
outputs = torch.sigmoid(self.linear(x))
return outputs
# 執行個體化模型
input_size = X_train.shape[1]
pt_model = LogisticRegression(input_size)
# 損失函數和最佳化器
criterion = nn.BCELoss()
optimizer = optim.SGD(pt_model.parameters(), lr=5e-5)
# 訓練模型
num_epochs = 1
X_train_pt = X_train
y_train_pt = y_train
for epoch in range(num_epochs):
# 前向傳播
# DataFrame 轉換為 Tensor
if isinstance(X_train_pt, pd.DataFrame):
X_train_pt = torch.tensor(X_train_pt.values)
X_train_pt = X_train_pt.float()
outputs = pt_model(X_train_pt)
outputs = outputs.squeeze()
# ndarray 轉換為 Tensor
if isinstance(y_train_pt, np.ndarray):
y_train_pt = torch.from_numpy(y_train_pt)
y_train_pt = y_train_pt.float()
loss = criterion(outputs, y_train_pt)
# 反向傳播和最佳化
optimizer.zero_grad()
loss.backward()
optimizer.step()TensorFlow
import tensorflow as tf
from tensorflow.keras import layers
# 定義羅吉斯迴歸模型
tf_model = tf.keras.Sequential([
layers.Dense(units=1, input_shape=(X_train.shape[-1],), activation='sigmoid')
])
# 編譯模型,使用二元交叉熵損失和隨機梯度下降最佳化器
tf_model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])
# 訓練模型
tf_model.fit(X_train, y_train, epochs=1, batch_size=32, verbose=0)步驟六:模型評估
引入FairnessDashboard,使用responsible-ai-toolbox載入測試資料集進行結果預測,產生公平性評估報告。
FairnessDashboard按照敏感變數分類預測結果和真實結果,並通過對比分析預測結果和真實結果,得到在不同敏感變數情況下的模型預測情況。
以敏感特徵值“sex”為例,FairnessDashboard按照“sex”將對應的預測結果(y_pred)和真實結果(y_test)進行分類,在“sex”分類中分別計算“Male”和“Female”的選擇率、精確度等資訊並進行對比。
本文樣本中,基於Sklearn對模型進行評估:
Sklearn
from raiwidgets import FairnessDashboard
import os
from urllib.parse import urlparse
# 根據測試資料集進行預測結果
y_pred_sk = sk_model.predict(X_test)
# 使用 responsible-ai-toolbox 計算每個敏感群體的資料資訊
metric_frame_sk = FairnessDashboard(sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_sk, locale = 'zh-Hans')
# 設定URL跳轉連結
metric_frame_sk.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_sk.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_sk.config['baseUrl'])PyTorch
from raiwidgets import FairnessDashboard
import torch
import os
from urllib.parse import urlparse
# 測試模型並評估公平性
pt_model.eval() # 設定模型為評估模式
X_test_pt = X_test
with torch.no_grad():
X_test_pt = torch.tensor(X_test_pt.values)
X_test_pt = X_test_pt.float()
y_pred_pt = pt_model(X_test_pt).numpy()
# 使用 responsible-ai-toolbox 計算每個敏感群體的資料資訊
metric_frame_pt = FairnessDashboard(sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_pt.flatten().round(),locale='zh-Hans')
# 設定URL跳轉連結
metric_frame_pt.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_pt.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_pt.config['baseUrl'])TensorFlow
from raiwidgets import FairnessDashboard
import os
from urllib.parse import urlparse
# 測試模型並評估公平性
y_pred_tf = tf_model.predict(X_test).flatten()
# 使用 responsible-ai-toolbox 計算每個敏感群體的資料資訊
metric_frame_tf = FairnessDashboard(
sensitive_features=sensitive_features_test,
y_true=y_test,
y_pred=y_pred_tf.round(),locale='zh-Hans')
# 設定URL跳轉連結
metric_frame_tf.config['baseUrl'] = 'https://{}-proxy-{}.dsw-gateway-{}.data.aliyun.com'.format(
os.environ.get('JUPYTER_NAME').replace("dsw-",""),
urlparse(metric_frame_tf.config['baseUrl']).port,
os.environ.get('dsw_region') )
print(metric_frame_tf.config['baseUrl'])關鍵參數說明:
sensitive_features:敏感屬性。
y_true:訓練資料集提供的真實結果。
y_pred:模型預測的結果。
locale(可選):評估面板顯示語言類型,支援簡體中文(“zh-Hans”)和繁體中文(“zh-Hant”),預設為英語(“en”)。
步驟七:查看評估報告
評估完成後,單擊URL,查看完整的評估報告。

在公平性儀表板頁面單擊開始使用,按照以下參數依次設定敏感特徵、效能指標、公平性指標,查看模型針對敏感特徵“sex”或“race”的指標資料差異。
敏感特徵為“sex”
敏感特徵:sex
效能指標:Accuracy
公平性指標:Demographic parity difference
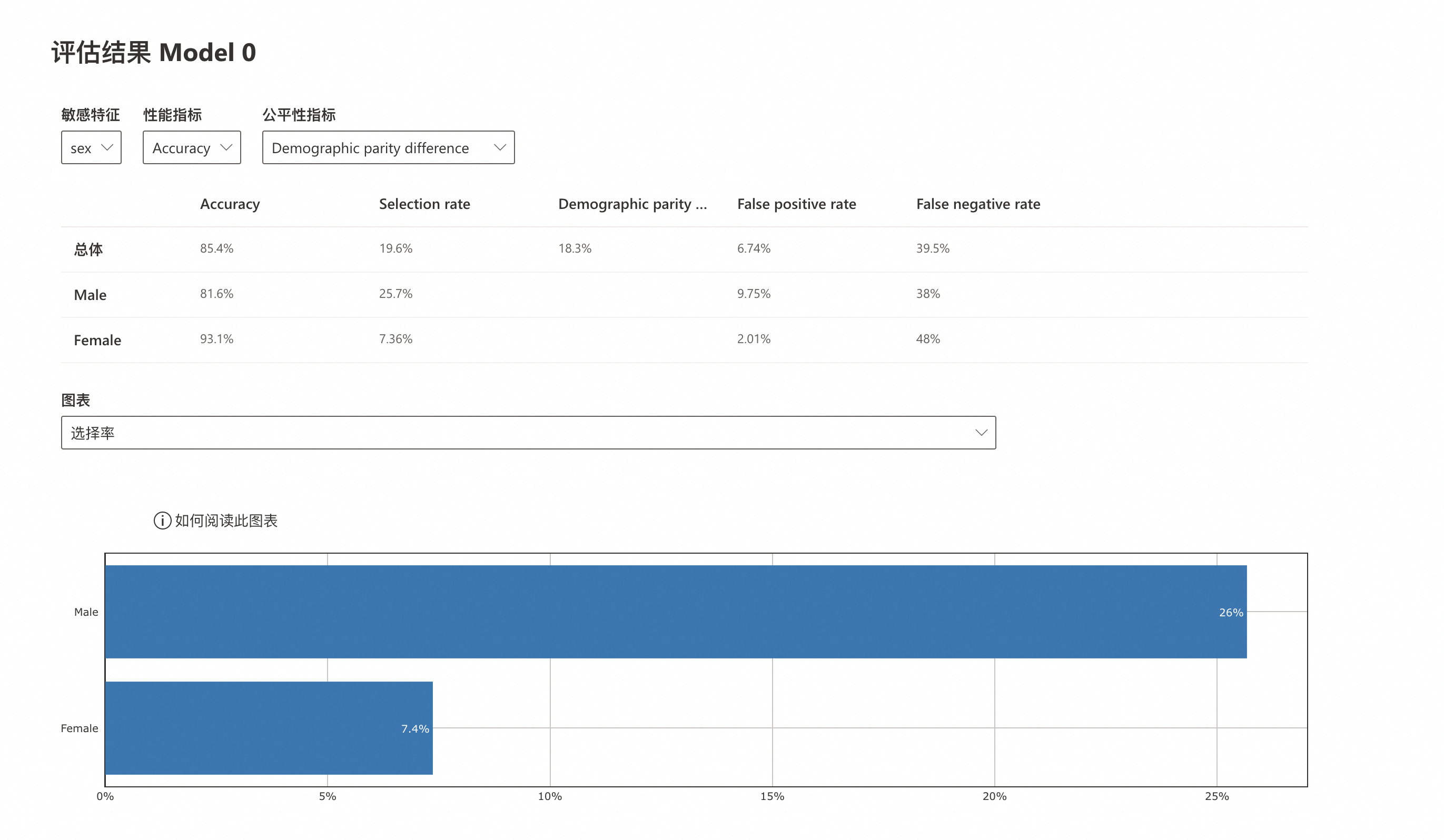
Accuracy:精確度,是指模型正確預測的樣本數佔總樣本數的比例。模型輸出男性個人年度營收的準確度(81.6%)低於女性個人年度營收的準確度(93.1%),但是兩者的準確度與模型總體準確度(85.4%)都比較接近。
Selection rate:選擇率,是指模型輸出“好”的目標變數的機率,這裡“好”的目標變數是個人年度營收>50K。模型輸出男性個人年度營收>50K的機率(25.7%)大於女性個人年度營收>50K的機率(7.36%),並且模型輸出女性個人年度營收>50K的機率(7.36%)遠低於個人年度營收>50K的總體機率(19.6%)。
Demographic parity difference:人口統計公平性差異,是指不同受保護群體之間,在指定的敏感屬性下獲得積極預測結果的機率差異。這個值越接近0,意味著群體間的偏差越小。模型總體的人口統計公平性差異為18.3%。
敏感特徵為“race”
敏感特徵:race
效能指標:Accuracy
公平性指標:Demographic parity difference

Accuracy:精確度,是指模型正確預測的樣本數佔總樣本數的比例。模型輸出“White”和“Asian-Pac-Islander”個人年度營收的準確度(84.9%和79.1%)低於“Black”、“Other”和“Amer-Indian-Eskimo”個人年度營收的準確度(90.9%、90.8%和91.9%),但是所有敏感特徵人群的準確度與模型總體準確度(85.4%)都比較接近。
Selection rate:選擇率,是指模型輸出“好”的目標變數的機率,這裡“好”的目標變數是個人年度營收>50K。模型輸出“White”和“Asian-Pac-Islander”個人年度營收>50K的選擇率(21%和23.9%)大於“Black”、“Other”和“Amer-Indian-Eskimo”個人年度營收>50K的選擇率 (8.34%、10.3%和8.14%),並且“Black”、“Other”和“Amer-Indian-Eskimo”個人年度營收>50K的選擇率(8.34%、10.3%和8.14%)遠低於個人年度營收>50K的總體選擇率(19.6%)。
Demographic parity difference:人口統計公平性差異,是指不同受保護群體之間,在指定的敏感屬性下獲得積極預測結果的機率差異。這個值越接近0,意味著群體間的偏差越小。模型總體的人口統計公平性差異為15.8%。