本文為您介紹如何通過提交一個使用MaxCompute計算資源的超參數調優實驗,來運行PS-SMART二分類、預測和評估組件,以擷取PS-SMART組件演算法的較優超參數組合。
前提條件
首次使用AutoML功能時,需要完成AutoML相關許可權授權。具體操作,請參見雲產品依賴與授權:AutoML。
已建立工作空間並關聯了MaxCompute資源。具體操作,請參見建立工作空間。
步驟一:準備資料
本方案使用經過特徵工程處理過的銀行客戶認購產品預測資料集,參考以下操作步驟準備訓練資料集和測試資料集:
通過MaxCompute用戶端執行以下SQL命令,分別建立表bank_train_data和bank_test_data。關於MaxCompute用戶端的安裝和配置,請參見使用本地用戶端(odpscmd)串連。
create table bank_train_data( id bigint ,age double ,job double ,marital double ,education double ,default double ,housing double ,loan double ,contact double , month double ,day_of_week double ,duration double ,campaign double ,pdays double ,previous double ,poutcome double ,emp_var_rate double , cons_price_index double ,cons_conf_index double ,lending_rate3m double ,nr_employed double ,subscribe bigint ); create table bank_test_data( id bigint ,age double ,job double ,marital double ,education double ,default double ,housing double ,loan double ,contact double , month double ,day_of_week double ,duration double ,campaign double ,pdays double ,previous double ,poutcome double ,emp_var_rate double , cons_price_index double ,cons_conf_index double ,lending_rate3m double ,nr_employed double ,subscribe bigint );通過MaxCompute用戶端的Tunnel命令,分別將以下訓練資料集和測試資料集上傳到表bank_train_data和bank_test_data中。關於Tunnel命令的使用方法,請參見Tunnel命令。
-- 將訓練資料集上傳到表bank_train_data中。其中xx/train_data.csv需要替換為train_data.csv所在的路徑。 tunnel upload xx/train_data.csv bank_train_data; -- 將測試資料集上傳到表bank_test_data中。其中xx/test_data.csv需要替換為test_data.csv所在的路徑。 tunnel upload xx/test_data.csv bank_test_data;
步驟二:建立實驗
進入建立實驗頁面,並按照以下操作步驟配置關鍵參數,其他參數配置詳情,請參見建立實驗。參數配置完成後,單擊提交。
設定執行配置。
參數
描述
任務類型
選擇MaxCompute。
命令
配置以下五個命令,按照順序依次排列,後續會按順序執行命令。
cmd1:使用準備好的測試資料,運行PS-SMART二分類訓練,構建二分類模型。各個參數的配置說明,請參見PS-SMART二分類訓練。
PAI -name ps_smart -project algo_public -DinputTableName='bank_train_data' -DmodelName='bi_ps_${exp_id}_${trial_id}' -DoutputTableName='bi_model_output_${exp_id}_${trial_id}' -DoutputImportanceTableName='bi_imp_${exp_id}_${trial_id}' -DlabelColName='subscribe' -DfeatureColNames='age,job,marital,education,default,housing,loan,contact,month,day_of_week,duration,campaign,pdays,previous,poutcome,emp_var_rate,cons_price_index,cons_conf_index,lending_rate3m,nr_employed' -DenableSparse='false' -Dobjective='binary:logistic' -Dmetric='error' -DfeatureImportanceType='gain' -DtreeCount='${tree_count}' -DmaxDepth='${max_depth}' -Dshrinkage="0.3" -Dl2="1.0" -Dl1="0" -Dlifecycle="3" -DsketchEps="0.03" -DsampleRatio="1.0" -DfeatureRatio="1.0" -DbaseScore="0.5" -DminSplitLoss="0"cmd2:刪除預測結果表。
drop table if exists bi_output_${exp_id}_${trial_id};cmd3:基於cmd1產生的分類模型,運行預測組件,來預測輸入資料。各個參數的配置說明,請參見預測。
PAI -name prediction -project algo_public -DinputTableName='bank_test_data' -DmodelName='bi_ps_${exp_id}_${trial_id}' -DoutputTableName='bi_output_${exp_id}_${trial_id}' -DfeatureColNames='age,job,marital,education,default,housing,loan,contact,month,day_of_week,duration,campaign,pdays,previous,poutcome,emp_var_rate,cons_price_index,cons_conf_index,lending_rate3m,nr_employed' -DappendColNames='subscribe,age,job,marital,education,default,housing,loan,contact,month,day_of_week,duration,campaign,pdays,previous,poutcome,emp_var_rate,cons_price_index,cons_conf_index,lending_rate3m,nr_employed' -DenableSparse='false' -Dlifecycle='3';cmd4:基於cmd3產生的預測結果,運行二分類評估組件,來評估二分類模型的優劣性。各個參數的配置說明,請參見二分類評估。
PAI -name evaluate -project algo_public -DoutputDetailTableName='bi_0804_${exp_id}_${trial_id}_outputDetailTable' -DoutputMetricTableName='bi_0804_${exp_id}_${trial_id}_outputMetricTable' -DlabelColName='subscribe' -DscoreColName='prediction_score' -DpositiveLabel='1' -DbinCount='1000' -DdetailColName='prediction_detail' -DlabelMatch='true' -DinputTableName='bi_output_${exp_id}_${trial_id}';cmd5:從cmd4的評估結果表裡,擷取評估指標。
INSERT OVERWRITE TABLE ps_smart_classification_metrics PARTITION(pt='${exp_id}_${trial_id}') SELECT /*+MAPJOIN(b,c,d)*/ REGEXP_EXTRACT(a.data_range, '\\\((.*?),') as threshold, a.recall, a.precision, a.f1_score, c.value as auc, d.value as ks FROM (SELECT recall, precision, f1_score, data_range, 'AUC' auc, 'KS' ks from bi_0804_${exp_id}_${trial_id}_outputDetailTable) a JOIN bi_0804_${exp_id}_${trial_id}_outputMetricTable b on b.name='F1 Score' AND a.f1_score=b.value JOIN bi_0804_${exp_id}_${trial_id}_outputMetricTable c ON c.name=a.auc JOIN bi_0804_${exp_id}_${trial_id}_outputMetricTable d ON d.name=a.ks;
超參數
每個超參數對應的約束類型和搜尋空間配置如下:
tree_count:
約束類型:choice。
搜尋空間:單擊
 ,增加3個枚舉值,分別為50、100和150。
,增加3個枚舉值,分別為50、100和150。
max_depth:
約束類型:choice。
搜尋空間:單擊
 ,增加3個枚舉值,分別為6、8和10。
,增加3個枚舉值,分別為6、8和10。
使用上述配置可以產生9種超參數組合,後續實驗會分別為每種超參數組合建立一個Trial,在每個Trial中使用一組超參數組合來運行PS-SMART二分類組件和二分類評估組件。
設定Trial配置。
參數
描述
指標類型
選擇table。
計算方式
選擇best。
指標權重
配置以下指標權重:
key:recall、value:0.5
key:precision、value:0.25
key:auc、value:0.25
指標來源
配置為
select * from ps_smart_classification_metrics where pt='${exp_id}_${trial_id}';。最佳化方向
選擇越大越好。
模型名稱
配置為bi_ps_${exp_id}_${trial_id}。
設定搜尋配置。
參數
描述
搜尋演算法
選擇TPE。
最大搜尋次數
配置為5。
最大並發量
配置為2。
步驟三:查看實驗詳情和運行結果
在實驗列表頁面,單擊實驗名稱,進入實驗詳情頁面。
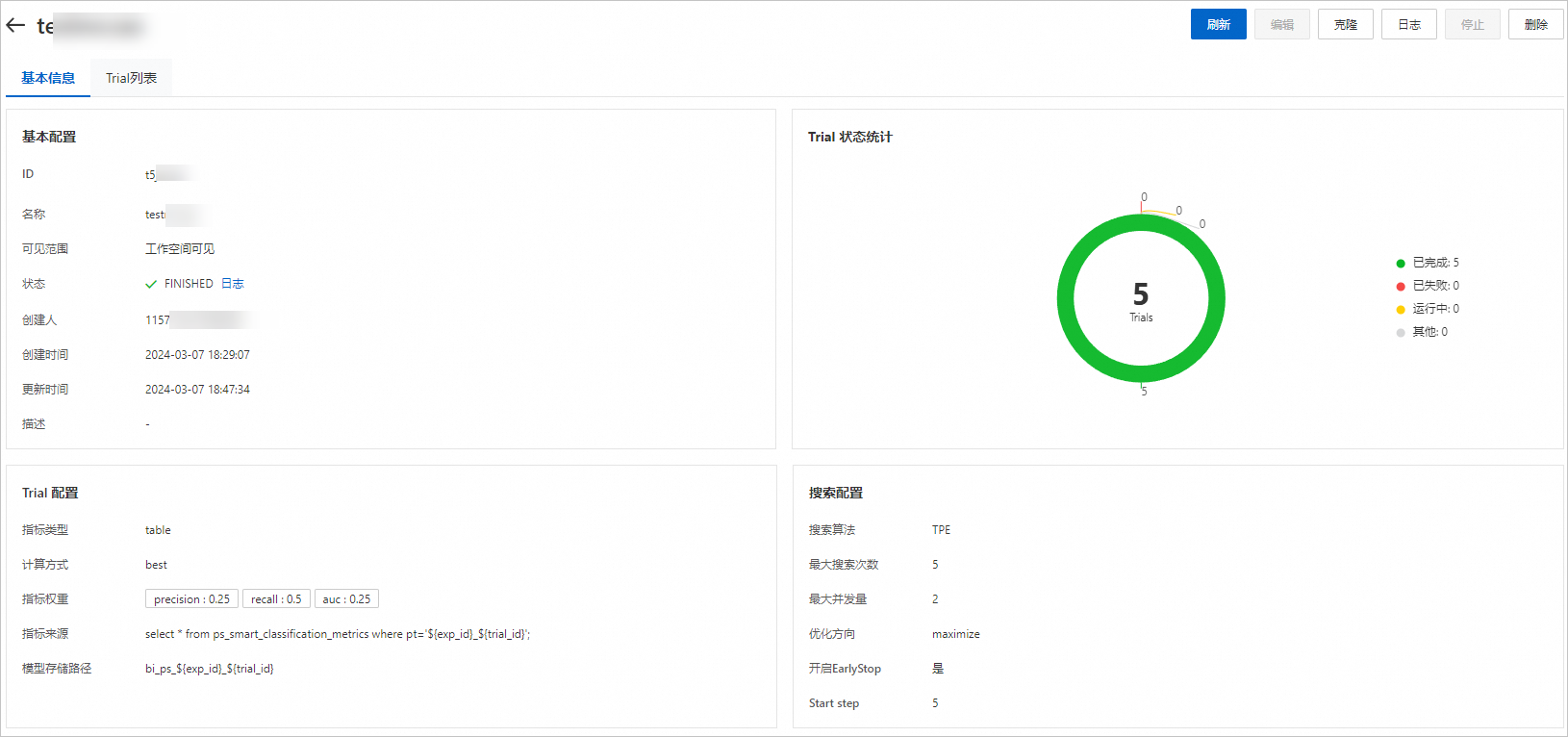 在該頁面,您可以查看Trial的執行進度和狀態統計,實驗根據配置的搜尋演算法和最大搜尋次數自動建立5個Trial。
在該頁面,您可以查看Trial的執行進度和狀態統計,實驗根據配置的搜尋演算法和最大搜尋次數自動建立5個Trial。單擊Trial列表,您可以在該頁面查看該實驗自動產生的所有Trial列表,以及每個Trial的執行狀態、最終指標和超參數組合。
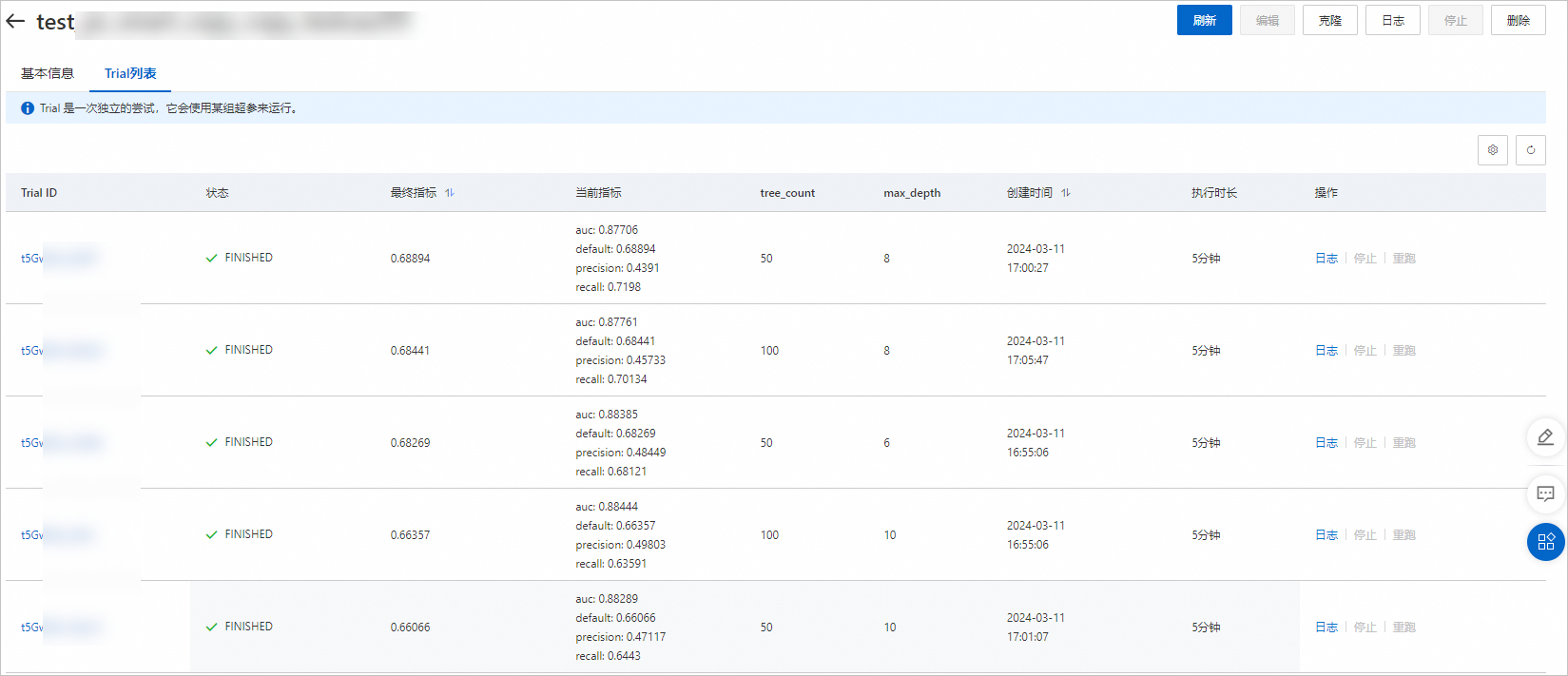 根據配置的最佳化方向(越大越好),從上圖可以看出,最終指標為0.688894對應的超參組合(tree_count:50;max_depth:8)較優。
根據配置的最佳化方向(越大越好),從上圖可以看出,最終指標為0.688894對應的超參組合(tree_count:50;max_depth:8)較優。