本文通過分析北京一年的真實天氣資料,構建霧霾天氣預測模型,從而挖掘對霧霾天氣(指PM 2.5)影響最大的汙染物。
資料集
本實驗為2016年全年(以小時為單位)的北京空氣指標資料,具體欄位如下。
欄位名 | 類型 | 描述 |
time | STRING | 日期,精確到天。 |
hour | STRING | 第幾小時的資料。 |
pm2 | STRING | PM 2.5指標。 |
pm10 | STRING | PM 10指標。 |
so2 | STRING | 二氧化硫指標。 |
co | STRING | 一氧化碳指標。 |
no2 | STRING | 二氧化氮指標。 |
霧霾天氣預測
進入Designer頁面。
登入PAI控制台。
在左側導覽列單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應的工作空間。
在工作空間頁面的左側導覽列選擇,進入Designer頁面。
構建工作流程。
在Designer頁面,單擊預置模板頁簽。
在模板列表的霧霾天氣預測地區,單擊建立。
在建立工作流程對話方塊,配置參數(可以全部使用預設參數)。
其中:工作流程資料存放區配置為OSS Bucket路徑,用於儲存工作流程運行中產出的臨時資料和模型。
單擊確定。
您需要等待大約十秒鐘,工作流程可以建立成功。
在工作流程列表,雙擊霧霾天氣預測工作流程,進入工作流程。
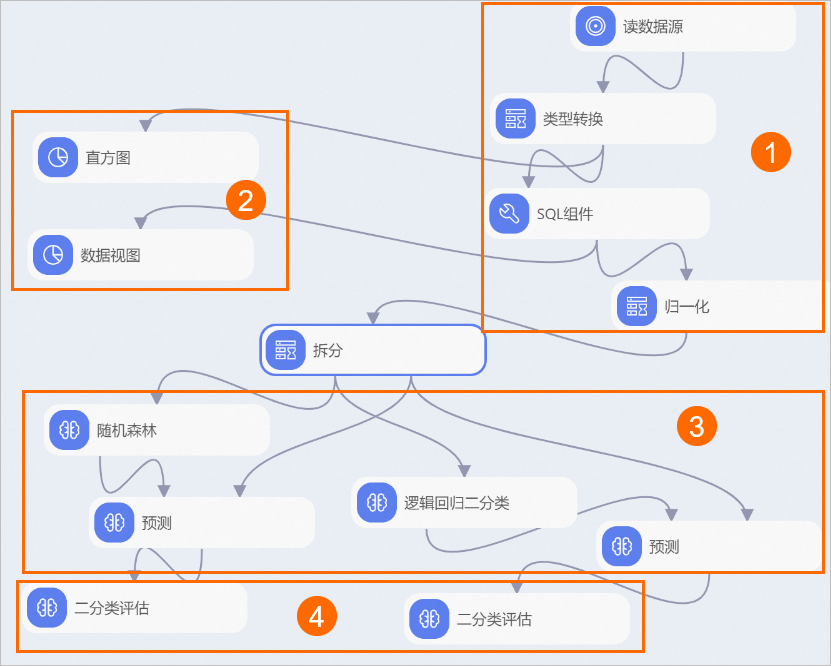
系統根據預置的模板,自動構建工作流程,如下圖所示。
地區
描述
①
資料匯入及預先處理:
通過讀資料表組件,匯入資料來源。
通過類型轉換組件,將STRING類型的資料轉換為DOUBLE類型。
通過SQL指令碼組件,將目標列轉換為0和1的二實值型別。本實驗中,pm2列為目標列。數值大於200的作為重度霧霾天氣,將其標記為1,反之標記為0。SQL語句如下。
select time,hour,(case when pm2>200 then 1 else 0 end),pm10,so2,co,no2 from ${t1};通過歸一化組件,去除量綱,即將不同指標汙染物的單位統一。
②
統計分析:
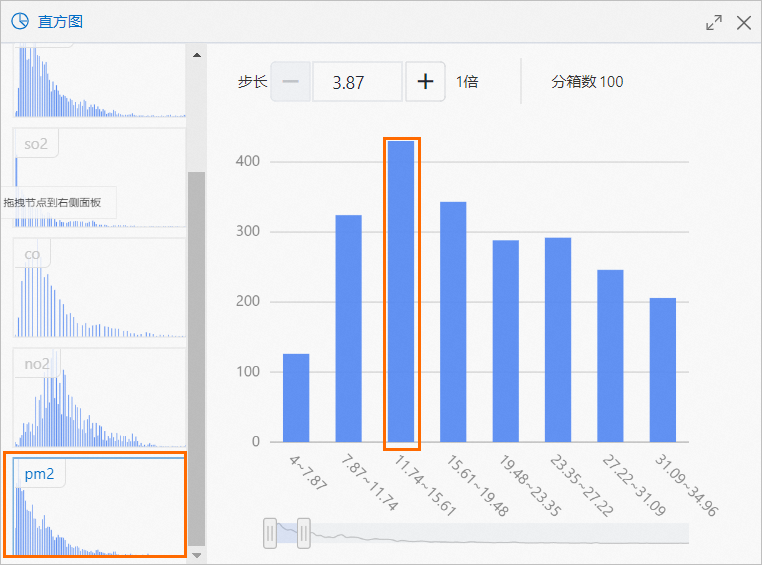
通過長條圖組件以可視化的方式查看每種汙染物的分布情況。
以PM2.5為例,數值出現最多的區間為11.74~15.61,共430次,如下圖所示。
通過資料檢視組件以可視化的方式查看每種汙染物不同區間對於結果的影響。
以no2為例,在112.33~113.9區間產生了7個目標列為0的目標和9個目標列為1的目標(如下圖所示)。因此,no2在112.33~113.9區間時,出現重度霧霾天氣的機率較高。Entropy和Gini表示該特徵區間對於目標值的影響(資訊量層面的影響),數值越大影響越大。

③
模型訓練及預測,本實驗分別使用隨機森林和羅吉斯迴歸二分類組件進行模型訓練。
④
模型評估。
運行工作流程並查看模型效果。
單擊畫布上方的運行按鈕
 。
。工作流程運行結束後,按右鍵畫布中隨機森林下遊的二分類評估,在捷徑功能表,單擊可視化分析。
在二分類評估對話方塊,單擊評估圖表頁簽,即可查看隨機森林訓練模型的預測效果。
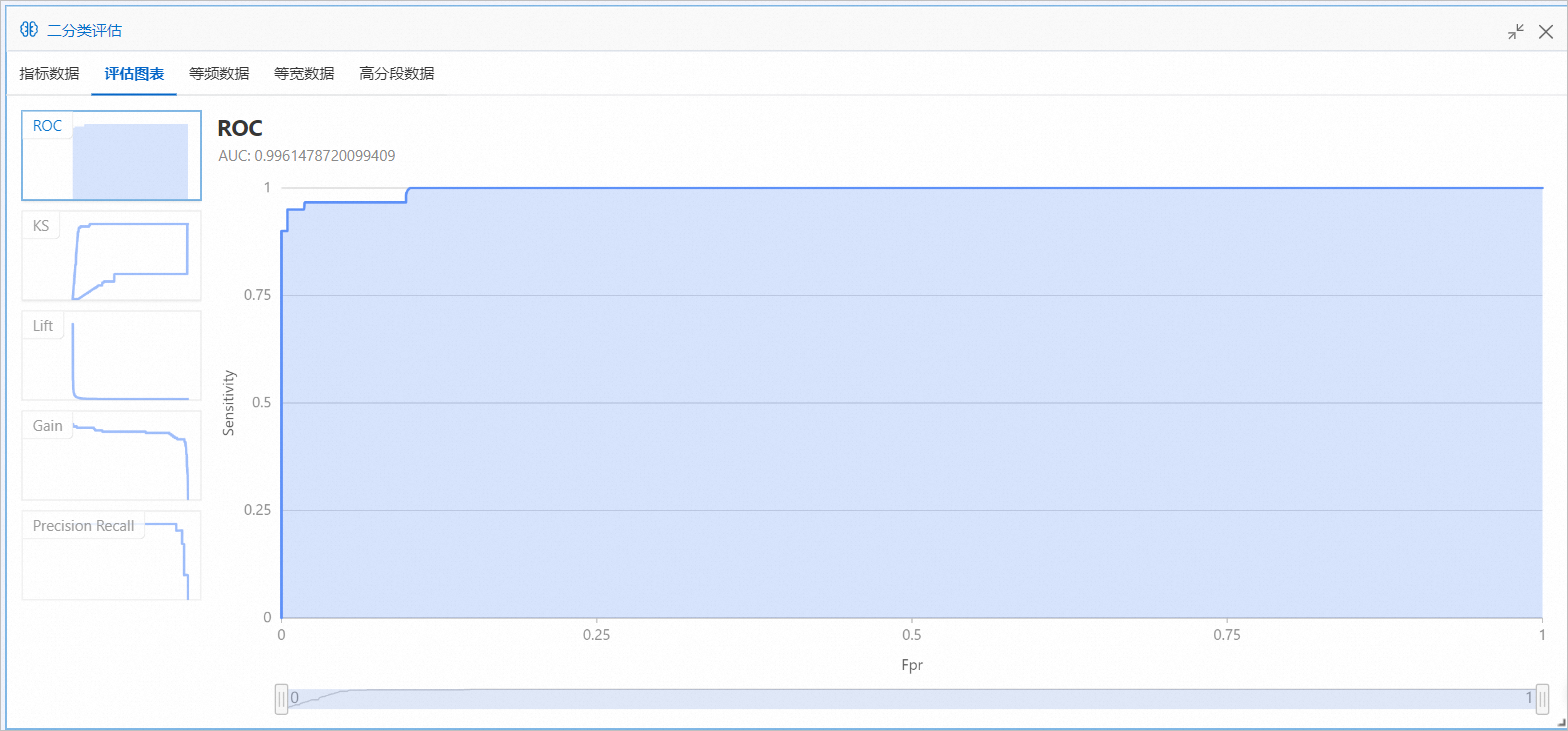 AUC的取值表示隨機森林組件訓練的霧霾天氣預測模型的準確率達到了99%以上。
AUC的取值表示隨機森林組件訓練的霧霾天氣預測模型的準確率達到了99%以上。按右鍵畫布中的羅吉斯迴歸二分類下遊的二分類評估,在捷徑功能表,單擊可視化分析。
在二分類評估對話方塊,單擊評估圖表頁簽,即可查看羅吉斯迴歸二分類訓練模型的預測效果。
 AUC的取值表示羅吉斯迴歸二分類組件訓練的霧霾天氣預測模型的準確率達到了98%以上。
AUC的取值表示羅吉斯迴歸二分類組件訓練的霧霾天氣預測模型的準確率達到了98%以上。