召回引擎版簡介
OpenSearch-召回引擎版是阿里巴巴自主研發的大規模分布式搜尋引擎,支援了淘寶、天貓、菜鳥、優酷乃至海外電商在內整個集團的搜尋業務,同時也支撐了阿里雲上的OpenSearch業務。OpenSearch-召回引擎版經過多年的發展,在滿足業務高可用、高時效性、低成本等需求的同時,也沉澱出一套自動化營運系統,使用它使用者可以根據自己的業務特點方便的構建自己的搜尋服務。
OpenSearch-召回引擎版架構
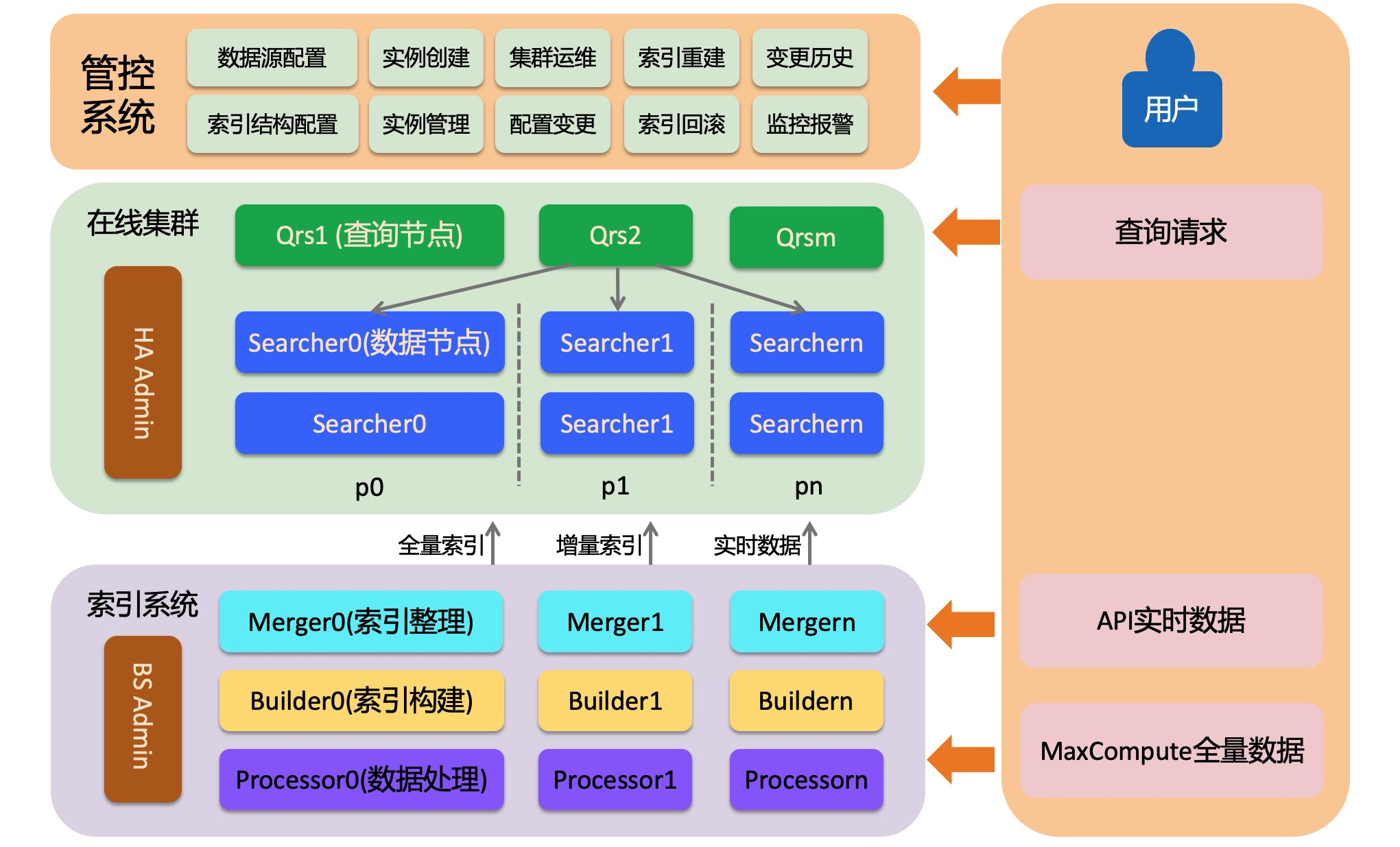
OpenSearch-召回引擎版主要有三部分構成,線上系統、離線索引構建系統、管控系統。線上系統載入索引,並提供檢索服務;離線索引構建系統將使用者的資料構建成索引,包括全量索引、批次增量索引、即時索引;管控系統為使用者提供自動化營運服務,方便使用者建立叢集並對叢集進行各種營運操作。
線上系統
線上系統是一個分布式檢索系統,由三個角色構成:admin、qrs和searcher,下面分別介紹:
HA Admin
HA Admin是線上系統的大腦,每個物理叢集都會有最少一個admin。HA admin負載接受管控系統的命令,並根據命令向Qrs和Searcher發送各種營運指令。另外admin還會即時監控Qrs和Searcher節點的運行情況,對於心跳異常的節點admin會自動替換。
Qrs(查詢節點)
Qrs也叫查詢節點或者查詢與結果處理節點,它對輸入的查詢請求進行解析、校正或者改寫,並將解析之後的請求轉寄給Searcher執行,收集併合並Searcher返回的結果,加工之後返回給使用者。查詢節點是一個計算型節點,不載入使用者的資料,一般不需要太多的記憶體,但是當返回的文檔個數較多或者統計產出的條目過多時才會消耗大量記憶體。如果查詢節點的處理能力達到瓶頸,可以擴充查詢節點的備份數或者擴查詢節點的規格。
Searcher(資料節點)
Searcher載入使用者的索引資料並根據查詢檢索文檔、對文檔進行過濾、統計、排序等操作。Searcher上的索引是可以分區的,分區的含義是對分區欄位雜湊到[0,65535]之間,將這個區間分成指定的片數(構建索引時指定)。這樣對於資料量較大或者對查詢效能有要求的叢集,就可以通過分區提高單次請求的處理效能。如果想提高整個叢集的處理能力(比如從支援1000 qps提升到10000 qps)可以通過擴備份的方式進行。擴備份不是只擴一個Searcher節點,而是擴承載所有資料的多個Searcher節點(多個分區要做成完整的[0,65535]區間)。
離線索引構建系統
OpenSearch-召回引擎版是一個讀寫分離的搜尋引擎,資料的寫入不影響線上檢索服務,所以能夠在支撐大批量資料即時寫入的同時,也能保證查詢服務足夠穩定。索引構建系統主要包括兩個流程(全量和增量),每個流程中都會有三個角色來處理資料、構建索引。
全量流程
OpenSearch-召回引擎版的索引是支援多版本的,每個索引版本都會基於一份未經處理資料來構建(API資料來源預設為空白資料),在第一次構建時啟動的就是全量流程。全量流程是一個非常駐任務,資料處理完成,產出一份全量索引,全量流程結束。產出的全量索引通過全量切換,切換到線上叢集提供檢索服務,後續的增量資料更新都是更新到新產出的全量版本中。目前全量任務僅支援從MaxCompute資料來源或者HDFS資料來源中讀取全量資料。
多索引版本的支援可以保證資料變更的穩定性,當索引結構變化或者資料結構發生變化時,通過全量產出新的索引是和老版本的索引完全隔離的,如果變更有問題可以及時復原。
全量索引的產出需要經過資料處理,索引構建,索引合并等流程,在各個階段可以通過設定索引處理的並發度提高全量索引的產出速度。
增量流程
全量索引產出之後,後續資料的更新都需要通過API推送完成。API推送的資料有兩條處理鏈路:經過Processor處理之後直接推送到資料節點在記憶體中構建即時索引;處理之後的資料經過Builder和Merger構建出增量索引,通過增量切換的形式切換到資料節點。增量切換時會清理記憶體中的即時索引,將增量中已經包含的資料從即時記憶體中刪除,減輕資料節點記憶體壓力。
增量流程是一個常駐任務,每一個索引表都會對應一個增量流程,可以通過控制增量流程各個節點的並發度來提高即時資料的處理能力。
Processor
Processor處理原始文檔,主要包括分詞或者根據商務邏輯對欄位內容進行改寫。Processor在增量流程中是一個常駐的分布式服務,可以通過配置調節Processor的並發度來提高資料處理能力。Processor中支援配置多個資料處理外掛程式,目前還未對外開放,如果有需求可以聯絡我們。
Builder
Builder將處理之後的文檔構建成索引。Builder不是一個常駐任務,它和Merger交替執行,每次Build完一次資料就會啟動依賴Merger任務對索引進行整理,整理之後的索引才會切換到資料節點。
Merger
Merger將Builder產出的索引資料作合并整理,使產出的索引更加的整齊緊湊。隨著資料更新,老的索引中必然會有很多被標記刪除的資料,Merger會按照指定的索引合并策略將這些資料進行清理合并。
召回引擎版索引結構
|-- generation_0
|-- partition_0_32767
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- partition_32768_65535
|-- index_format_version
|-- index_partition_meta
|-- schema.json
|-- version.0
|-- segment_0
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary
|-- segment_1
|-- segment_info
|-- attribute
|-- deletionmap
|-- index
|-- summary結構名稱 | 說明 |
generation | generation_x是引擎區分不同版本全量索引的標識。 |
partition | partition是searcher載入索引的基本單位。如果一個partition中資料過多,會導致searcher效能降低。線上資料一般通過劃分多個partition的方式來保證每個searcher的檢索效率。 |
schema.json | 索引設定檔。主要記錄fields,index, attribute 和summary等資訊。引擎通過該檔案來載入索引。 |
version.0 | version檔案。主要記錄當前partition中引擎需要載入的segment和最新doc的時間戳記。在即時build中,引擎會根據增量version的時間戳記過濾舊的原始文檔。 |
segment | segment是索引組成的基本單位。segment中包含了文檔的倒排和正排結構。index builder每次dump都會產生一個segment。多個segment可以通過merge策略進行合并。一個partition中可用的segment在version檔案中指明。 |
segment_info | segment資訊摘要。記錄了當前segment中文檔數目,當前segment是否merge過,locator資訊和最新doc時間戳記資訊。 |
index | 倒排索引目錄。 |
attribute | 正排索引目錄。 |
deletionmap | 刪除的doc記錄。 |
summary | 摘要索引目錄。 |
管控系統
管控系統是一個OpenSearch-召回引擎版執行個體的營運平台,這個平台大大節省了我們的營運成本,關於這個營運平台的介紹請參考召回引擎版產品文檔。
召回引擎版特性
穩定
召回引擎版底層採用c++實現,經過十多年的發展,支撐了多個核心業務,非常穩定,非常適用於對穩定性要求較高的核心搜尋情境。
高效
OpenSearch-召回引擎版是一個分布式搜尋引擎,可以高效的支援海量資料的檢索,同時也支援資料的即時更新(秒級生效),非常適用於對查詢耗時敏感、時效性要求高的搜尋情境。
低成本
OpenSearch-召回引擎版支援多種索引壓縮策略,同時支援多值索引載入測試,能夠以較低的成本滿足使用者的查詢需求。
功能豐富
OpenSearch-召回引擎版支援多種分析器類型、多種索引類型、強大的查詢文法,能夠很好的滿足使用者的檢索需求。同時我們還提供外掛程式機制,方便使用者定製自己的業務處理邏輯。
SQL查詢
OpenSearch-召回引擎版支援SQL查詢文法,支援多表線上join,提供豐富的內建UDF函數和UDF函數定製機制,以滿足不同使用者的檢索需求。在營運系統中我們即將整合SQL studio,方便使用者進行SQL開發與測試。