搜尋引擎對於檢索效能要求比較高,為此,系統開放了兩階段排序過程:基礎排序和業務排序,即粗排和精排。基礎排序即是海選,從檢索結果中快速找到品質高的文檔,取出TOP N個結果再按照精排進行精細算分,最終返回最優的結果給使用者。由此可見,基礎排序對效能影響比較大,業務排序對最終排序效果影響比較大。因此,基礎排序要求盡量簡單有效,只提取業務排序中的關鍵因子即可。其中,基礎排序與業務排序目前均通過排序運算式的方式進行配置。
排序運算式(Ranking Formula)允許使用者為應用自訂搜尋結果排序方式,通過在查詢請求中指定運算式來對結果排序。排序運算式支援基本運算(算術運算、關係運算、邏輯運算、位元運算、條件運算)、數學函數和業務排序函數等。Open Search對於幾種經典的應用(如論壇、資訊等)提供了相關性實戰,使用者可根據自己資料的特點,選擇合適的運算式模板,並以此為基礎進行修改,產生自己的運算式。
在進行相關性排序(業務排序)之前,首先要瞭解下系統排序策略:通過query等子句找到合格文檔後,會進入排序階段(具體參見sort子句),如果未指定sort子句或者sort子句中顯式指定了RANK,那麼都將進入到相關性算分階段。
如何設計基礎排序和業務排序的運算式要取決於實際搜尋情境的需求,最佳實務-功能篇有個《相關性實戰》的文章,較詳細介紹了在幾個典型情境下如何來思考和設計排序因子,大家可以參考。
排序運算式中一律使用數值或數值欄位類型參與基本運算操作,例如算數,關係,邏輯,條件等運算操作,大部分函數都不支援字串類型進行運算。
基本運算
運算 | 運算子 | 說明 |
一元運算 | - | 負號,功能為對某個運算式的值取負值,如-1, -max(width)。 |
算數運算 | +, -, *, / | 如width / 10 |
關係運算 | ==,!= ,>, <, >=, <= | 如width>=400 |
邏輯運算 | and ,or,! | 如width>=400 and height >= 300, !(a > 1 and b < 2) |
位元運算 | &, |,^ | 如 3 & (price ^ pubtime) + (price | pubtime) |
條件運算 | if(cond, thenValue, elseValue) | 如果cond的值非0,則該if運算式的實際值為thenValue,否則為elseValue。如if(2, 3, 5)的值為3,if(0, 3, 5)的值為5。(注意:不支援字串欄位類型,如literal或text類型都不支援;取值範圍為int32的取值範圍) |
in 運算 | i in [value1, value2, …, valuen] | 如果i的值在集合[value1, value2, …, valuen]中出現,則該運算式值為1,否則為0。例如: 2 in [2, 4, 6]的值為1,3 in [2, 4, 6]的值為0。 |
數學函數
函數 | 說明 |
max(a, b) | 取a和b的最大值。 |
min(a, b) | 取a和b的最小值。 |
ln(a) | 對a取自然對數。 |
log2(a) | 對a取以2為底的對數。 |
log10(a) | 對a取以10為底的對數。 |
sin(a) | 正弦函數。 |
cos(a) | 餘弦函數。 |
tan(a) | 正切函數。 |
asin(a) | 反正弦函數 |
acos(a) | 反餘弦函數 |
atan(a) | 反正切函數。 |
ceil(a) | 對a向上取整,如ceil(4.2)為5。 |
floor(a) | 對a向下取整,如floor(4.6)為4。 |
sqrt(a) | 對a開方,如sqrt(4)為2。 |
pow(a,b) | 返回a的b次冪,如pow(2, 3)為8。 |
now() | 返回目前時間,自Epoch (00:00:00 UTC, January 1, 1970)開始計算,單位是秒。 |
random() | 返回[0, 1]間的一個隨機值。 |
內建特徵函數
OpenSearch提供了豐富的基礎排序函數,如LBS類、文本類、時效類等,可以用在排序運算式中,相互組合實現強大的相關性排序效果。
Cava外掛程式
Cava是OpenSearch引擎團隊基於llvm實現的一門高效的程式設計語言,它的文法和Java類似,效能與c++相當。Cava是一門物件導向的程式設計語言,支援即時編譯(jit),支援各種安全檢查保證程式更加健壯。使用cava和OpenSearch提供的cava庫,在OpenSearch中可以定製自己的排序外掛程式,相比於OpenSearch支援的運算式,使用cava實現排序外掛程式具有以下優點:
更強的定製能力:cava提供了較運算式更加豐富的文法功能,比如for迴圈,函數定義,類定義等,使用者可以實現自己的業務需求。
更易於維護:cava實現的排序外掛程式比運算式更具有可讀性,更易於維護。
更易於接受:cava的文法和Java類似,熟悉Java的同學很容易使用cava進行開發,學習成本較低。
溫馨提示:Cava外掛程式僅支援獨享型應用配置。
流程示範
這裡以文本相關性排序函數配置為例,示範基礎排序和業務排序如何配置:
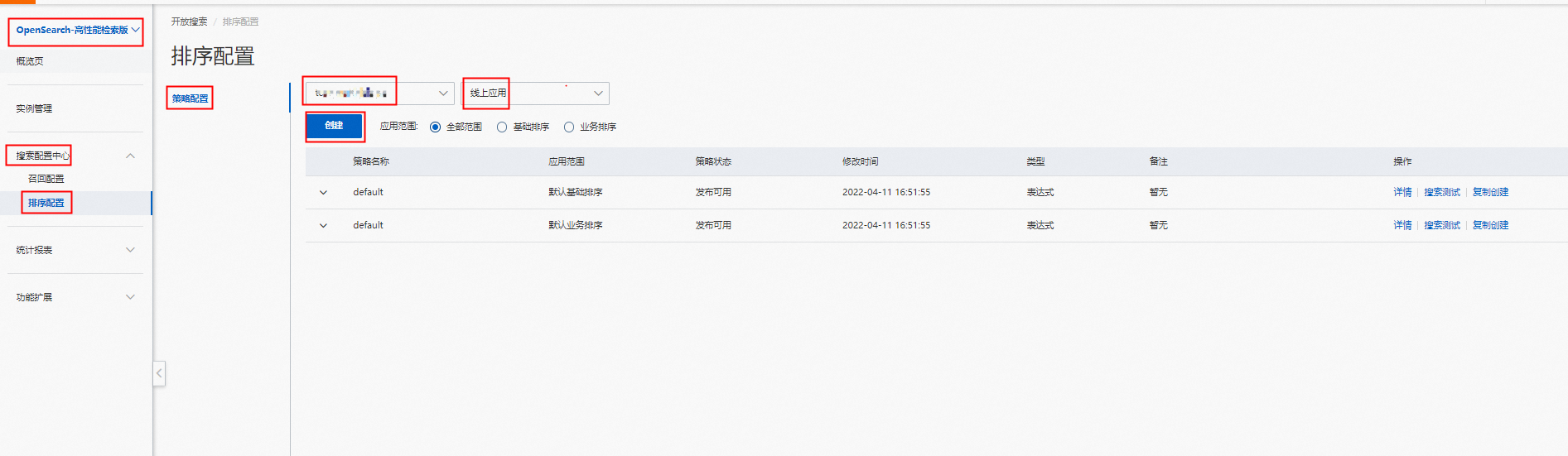
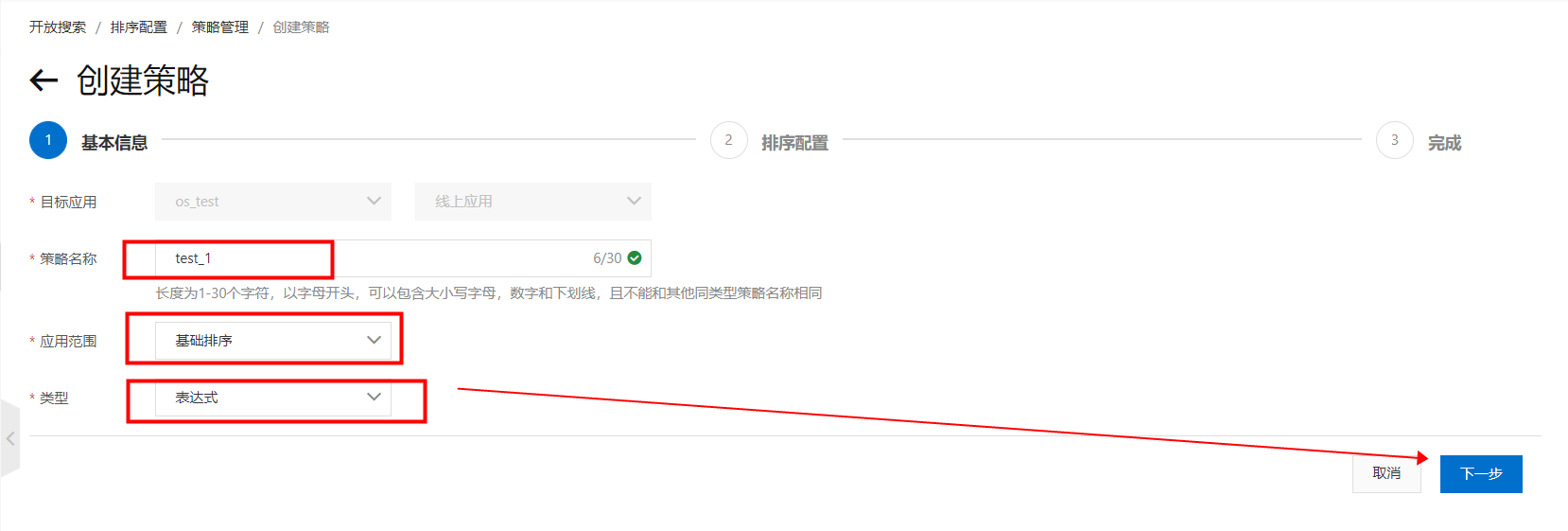
1.建立基礎排序策略,進入“OpenSearch控制台”,頁面左上方選擇“OpenSearch-高效能檢索版”,在“搜尋配置中心”—->“排序配置”—->“策略管理”,點擊“建立”: 填寫“策略名稱稱”,選擇應用範圍為“基礎排序”,選擇類型為“運算式”,點擊“下一步”:
 選擇算分特徵為“static_bm25”,設定權重為“10”(註:這裡權重為10,就代表該得分在計算的時候*10):
選擇算分特徵為“static_bm25”,設定權重為“10”(註:這裡權重為10,就代表該得分在計算的時候*10):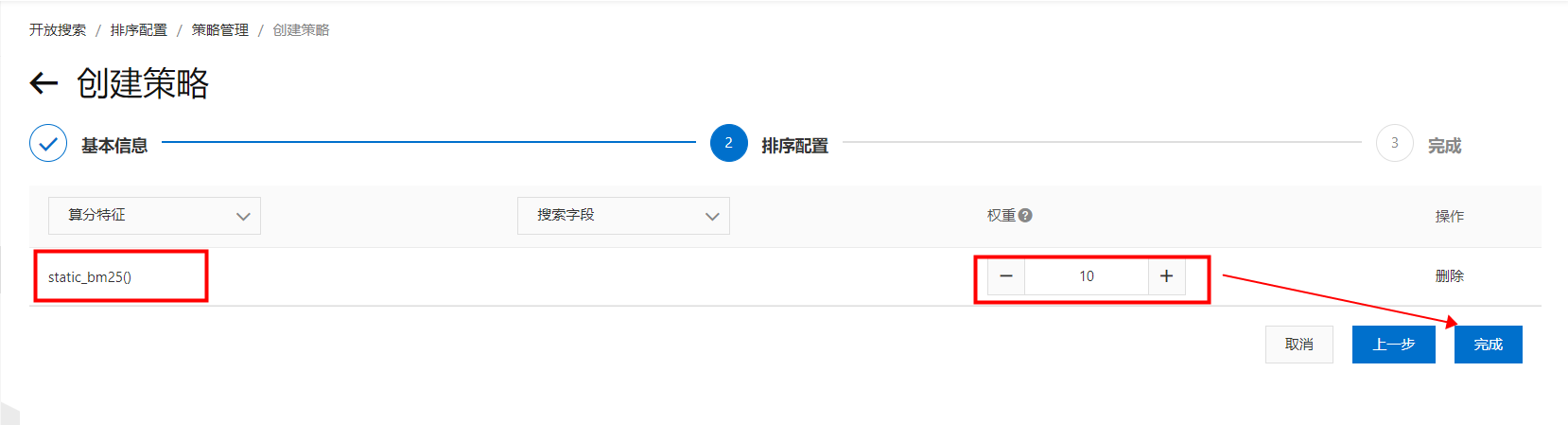 也可以選擇搜尋欄位(欄位必須是屬性欄位,並且只支援數實值型別的欄位,如:INT、DOUBLE、FLOAT類型),設定權重,則該欄位*權重的得分也會加在排序分裡:
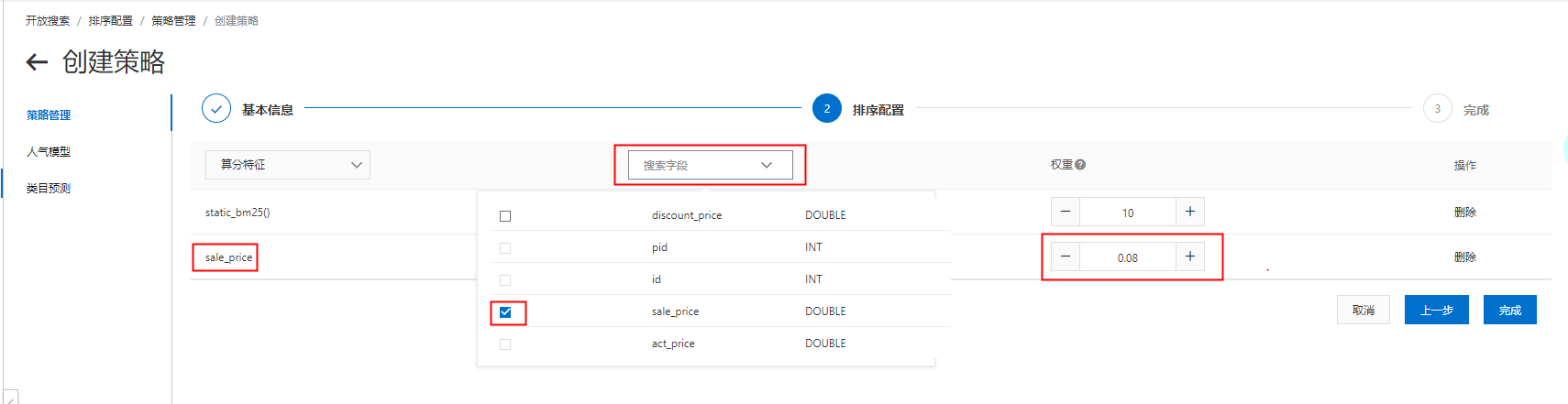
也可以選擇搜尋欄位(欄位必須是屬性欄位,並且只支援數實值型別的欄位,如:INT、DOUBLE、FLOAT類型),設定權重,則該欄位*權重的得分也會加在排序分裡:
配置完成,返回策略管理頁: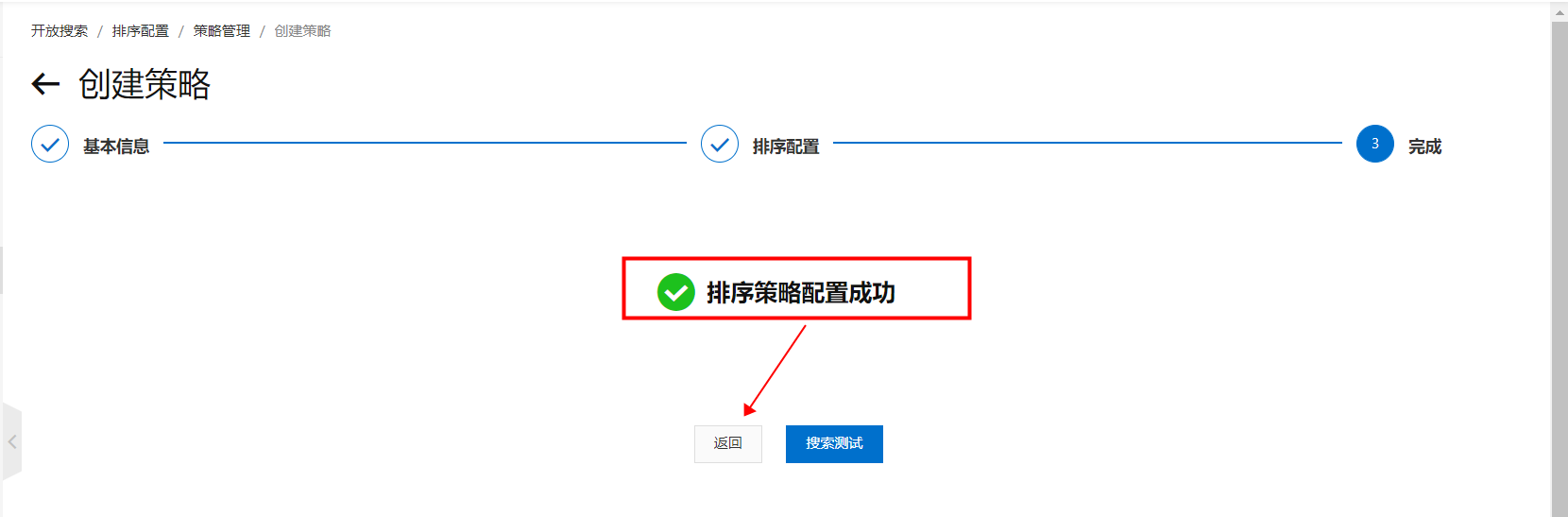
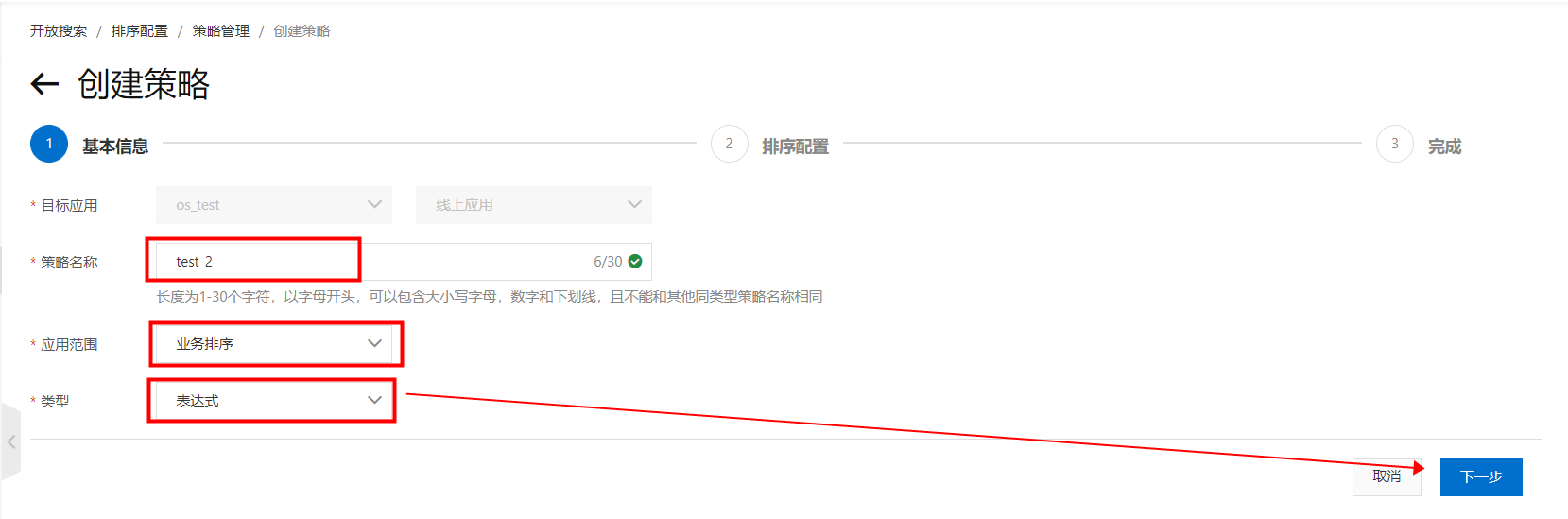
2.建立業務排序策略,進入“OpenSearch控制台”,頁面左上方選擇“OpenSearch-高效能檢索版”,在“搜尋配置中心”—->排序配置—->策略管理,點擊“建立”: 填寫“策略名稱稱”,選擇應用範圍為“業務排序”,選擇類型為“運算式”,點擊“下一步”:
 在內建函數裡選擇“text_relevance”,括弧內填入待查詢索引裡配置的欄位名,點擊“完成”:
在內建函數裡選擇“text_relevance”,括弧內填入待查詢索引裡配置的欄位名,點擊“完成”: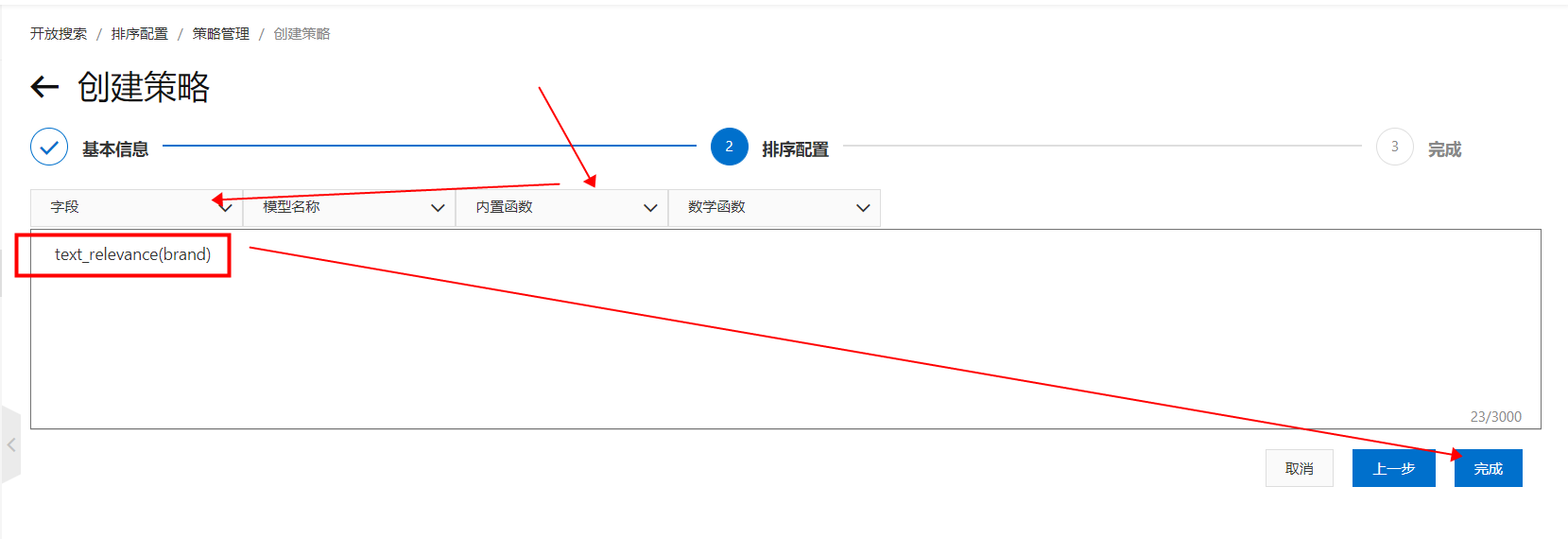 配置完成,返回策略管理頁:
配置完成,返回策略管理頁:
3.查看排序效果,在搜尋測試介面,配置基礎和業務排序參數,並開啟顯示排序明細: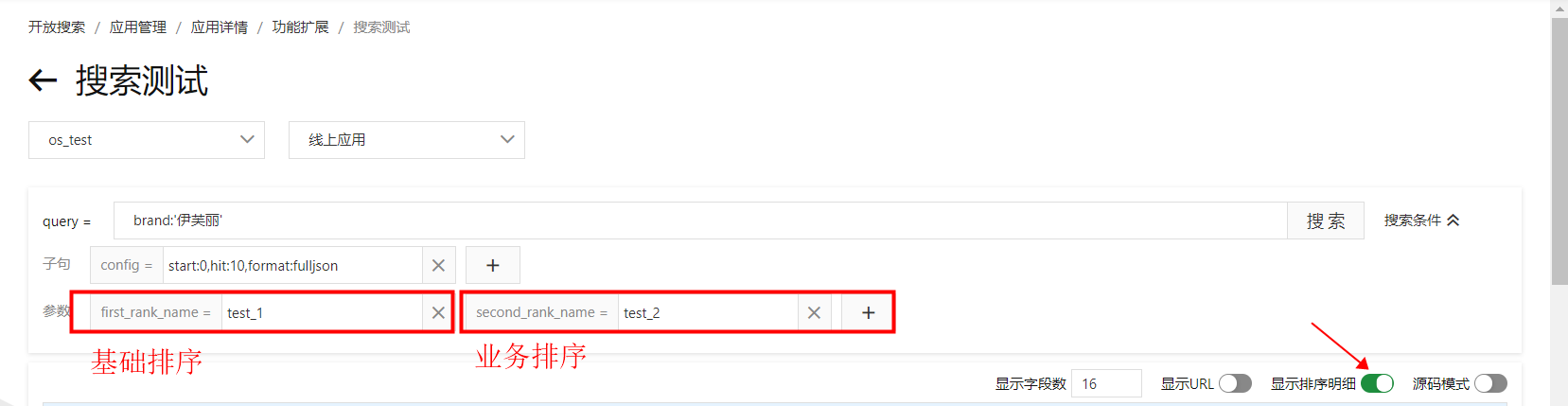 查看各函數算分結果:
查看各函數算分結果:
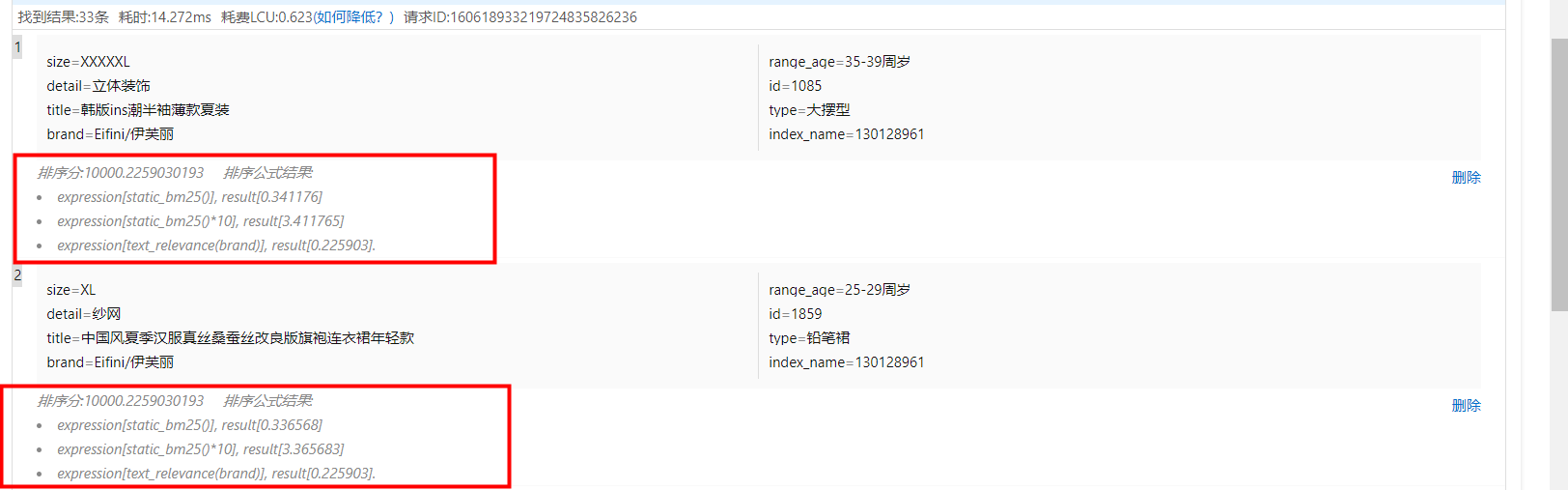
對於文檔得分的排序分為兩個階段:基礎排序和業務排序,通過query召回並通過filter過濾後的文檔,首先進入基礎排序,根據基礎排序運算式海選出文檔得分較高的文檔,然後取出TOP N個結果再按照業務排序運算式進行精細算分,最終返回最優的結果給使用者。算分邏輯如下:
若只配置了基礎排序,則文檔得分為(10000+基礎排序運算式計算的結果),總分最大為20000,超過20000結果仍為20000。
若只配置了業務排序,則文檔得分為(10000+業務排序運算式計算的結果),總分無上限。
若同時配置了基礎排序和業務排序,那麼進入業務排序的文檔最終得分為(10000+業務排序運算式計算的結果),其餘文檔最終得分為(10000+基礎排序運算式計算的結果,總分最大為20000,超過20000結果仍為20000)。
可以建立多個基礎排序和業務定序,但是查詢請求時僅支援同時使用1個基礎排序和一個業務定序。
first_rank_name僅支援填寫一個排序運算式名稱,不支援多個基礎排序運算式同時使用;
second_rank_name僅支援填寫一個排序運算式名稱,不支援多個業務排序運算式同時使用。
SDK 配置示範
Java SDK 示範:
// 設定粗精排運算式,此處設定為預設
Rank rank =newRank();
rank.setFirstRankName("default");//基礎排序策略名稱稱
rank.setSecondRankName("default");//業務排序策略名稱稱
rank.setReRankSize(5);//設定參與精排文檔個數PHP SDK 示範:
//指定粗排運算式
$params->setFirstRankName('default');
//指定精排運算式
$params->setSecondRankName('default');注意:
如果在控制台中設定了預設的基礎排序和業務排序,而在代碼中又重新指定基礎排序和業務排序,那麼在程式運行時,查詢介面以代碼中配置的基礎排序和業務排序為準。
代碼中查看排序明細:
方法:在config子句中添加參數:format:fulljson;
在返回結果中sortExprValues 就是文檔得分:
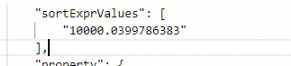
sortExprValues 是個數組,表示sort子句中排序欄位的值,例:
sort=-price;-RANK那麼sortExprValues 就是[price,文檔得分]
如果不設定sort,預設就是文檔得分