NimoShake(又名DynamoShake)是阿里雲研發的資料同步工具,您可以藉助該工具將Amazon DynamoDB資料庫遷移至阿里雲。
前提條件
已經建立阿里雲MongoDB執行個體,詳情請參見棄置站台集執行個體或建立分區叢集執行個體。
背景資訊
NimoShake主要用於從DynamoDB進行遷移,目的端目前僅支援MongoDB。更多詳情請參見NimoShake介紹。
注意事項
在執行全量資料移轉時將佔用源庫和目標庫一定的資源,可能會導致資料庫伺服器負載上升。如果資料庫業務量較大或伺服器規格較低,可能會加重資料庫壓力。建議您在執行資料移轉前謹慎評估,在業務低峰期執行資料移轉。
阿里雲MongoDB執行個體的儲存空間須大於Amazon DynamoDB資料庫佔用的儲存空間。
名詞解釋
斷點續傳:斷點續傳是指將一個任務分成多個部分進行傳輸,當遇到網路故障或者其他原因造成的傳輸中斷,可以延續之前傳輸的部分繼續傳輸,而不用從頭開始。
說明全量同步不支援斷點續傳功能,增量同步處理支援斷點續傳,如果增量同步處理過程中串連斷開了,在一定時間內恢複串連是可以繼續進行增量同步處理的。但在某些情況下,比如斷開的時間過久,或者之前位點的丟失,都會導致重新觸發全量同步。
位點:增量的斷點續傳是根據位點來實現的,預設的位點是寫入到目的端MongoDB中,庫名是nimo-shake-checkpoint。每個表都會記錄一個checkpoint的表,同樣還會有一個status_table表記錄當前是全量同步還是增量同步處理。
NimoShake功能特性
NimoShake目前支援全量和增量分離的同步機制,即先同步全量資料,再同步增量資料。
全量同步:包含資料同步和索引同步兩個部分,基本架構如下:

資料同步:NimoShake使用多個並發線程拉取源端資料,如下圖所示。
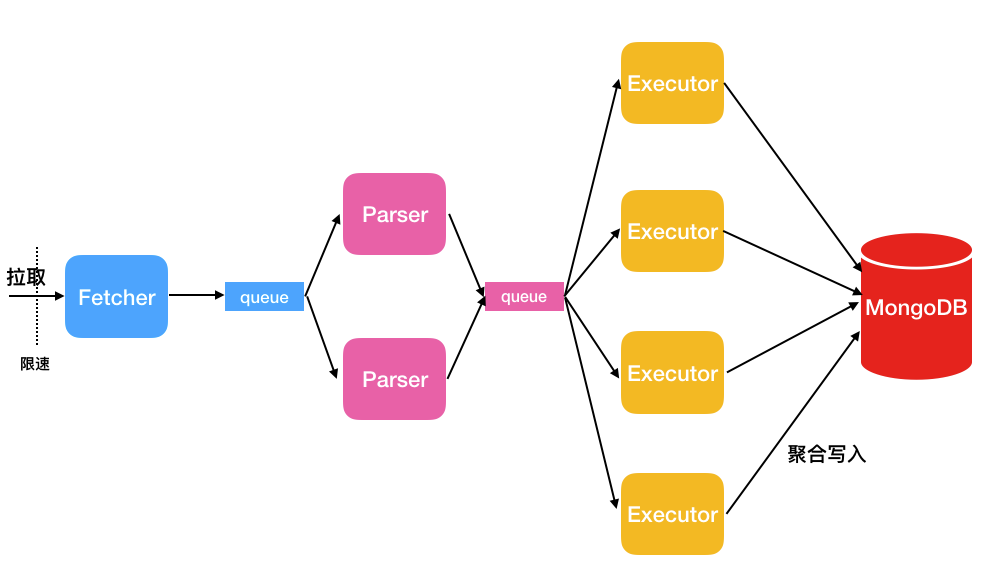
線程名稱
說明
Fetcher
調用Amazon提供的協議轉換驅動批量抓取源表的資料並放入隊列中,直至抓取完源表的所有資料。
說明目前只提供一個Fetcher線程。
Parser
從隊列中讀取資料,並解析成BSON結構。Parser解析完成後,將資料按條寫入Executor隊列。Parser線程可以啟動多個,預設為2個,您可以通過
FullDocumentParser參數調整Parser的個數。Executor
從隊列中拉取資料,並將資料進行彙總後寫入目的端MongoDB(彙總上限16MB,總條數1024)。Executor線程可以啟動多個,預設為4個,您可以通過
FullDocumentConcurrency參數調整Executor的個數。索引同步:NimoShake會在完成資料同步之後寫入索引。索引分為內建索引和使用者索引兩部分:
內建索引:如您有分區鍵(Partition key)和排序鍵(Sort key),NimoShake將會建立一個聯合唯一索引寫入MongoDB,除此之外,NimoShake還會針對分區鍵建立一個雜湊(Hash)索引同時寫入。如果您只有一個分區鍵,那麼最終寫入到MongoDB的將會是一個雜湊索引和一個唯一索引。
使用者索引:如果您有自建的索引,NimoShake將會根據主鍵(Primary key)建立一個雜湊索引寫入MongoDB。
增量同步處理:增量同步處理只同步資料,不同步增量同步處理過程中產生的索引。其基本架構如下:
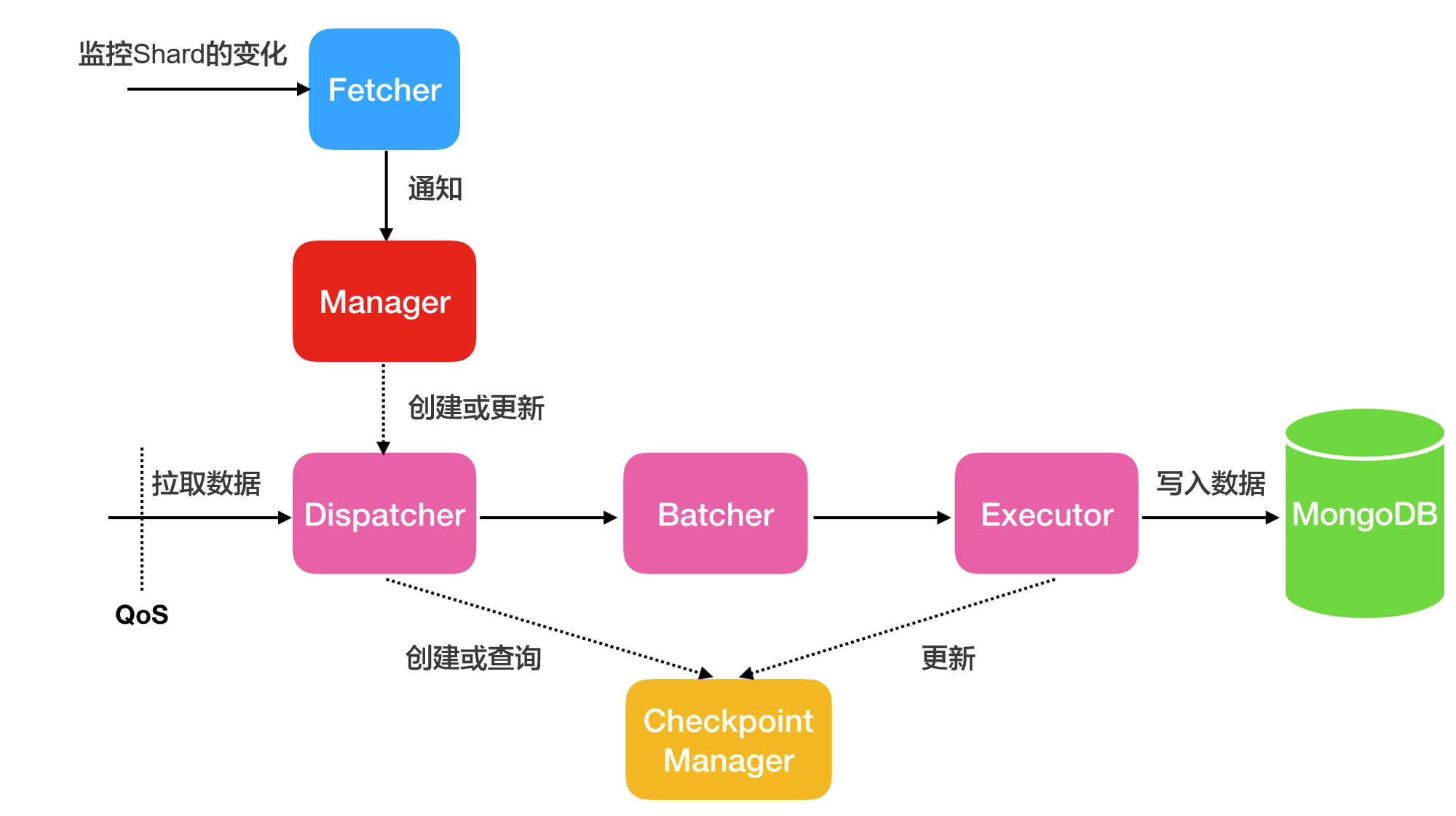
線程名稱
說明
Fetcher
感知流(Stream)中分區(shard)的變化。
Manager
進行訊息的通知,或者建立新的Dispatcher處理訊息,一個shard對應一個Dispatcher。
Dispatcher
從源端拉取增量資料。如果是斷點續傳,則會從上一次的Checkpoint位點開始拉取,而不是從頭拉取。
Batcher
對Dispatcher線程拉取的增量資料進行資料解析、打包與整合。
Executor
將整合後的資料寫入到MongoDB,同時更新checkpoint位點。
將Amazon DynamoDB遷移至阿里雲
本步驟以Ubuntu系統為例,介紹如何使用NimoShake將Amazon Dynamo資料庫遷移到阿里雲資料庫。
在系統中執行如下命令下載NimoShake包,等待下載完成。
wget https://github.com/alibaba/NimoShake/releases/download/release-v1.0.14-20250704/nimo-shake-v1.0.14.tar.gz說明建議下載最新版本的NimoShake包,下載地址請參見NimoShake。
執行如下命令解壓下載的NimoShake包。
tar zxvf nimo-shake-v1.0.14.tar.gz解壓完成後,輸入
cd nimo-shake-v1.0.14命令進入nimo檔案夾。輸入
vi nimo-shake.conf命令開啟NimoShake的設定檔。配置NimoShake,各配置項說明如下:
參數
說明
樣本值
id
遷移任務的ID,可自訂,用於輸出pid檔案等資訊,如本次任務的日誌名稱、斷點續傳(checkpoint)位點資訊儲存的資料庫名稱、同步到目的端的資料庫名稱。
id = nimo-shakelog.file
記錄檔路徑,不配置將列印到stdout。
log.file = nimo-shake.loglog.level
日誌的等級,取值:
none:不收集日誌。error:包含錯誤層級資訊的日誌。warn:包含警告層級資訊的日誌。info:反饋當前系統狀態的日誌。debug:包含調試資訊的日誌。
預設值:
info。log.level = infolog.buffer
是否啟用日誌緩衝區。取值:
true:啟用。啟用後能保證效能,但退出時可能會丟失最後幾條日誌。false:不啟用。不啟用將會降低效能但保證退出時每條日誌都被列印。
預設值:
true。log.buffer = truesystem_profile
PPROF連接埠,作調試用,列印堆棧協程資訊。
system_profile = 9330full_sync.http_port
全量階段的RESTful連接埠,可以通過
curl查看內部監控的統計情況,詳見wiki。full_sync.http_port = 9341incr_sync.http_port
增量階段的RESTful連接埠,可以通過
curl查看內部監控的統計情況,詳見wiki。incr_sync.http_port = 9340sync_mode
同步的類型,取值如下:
all:執行全量資料同步和增量資料同步。full:僅執行全量同步。
預設值:
all。說明源端為ApsaraDB for MongoDBDynamoDB協議相容版執行個體時,僅支援full模式。
sync_mode = allincr_sync_parallel
是否執行並行增量同步處理。取值:
true:開啟,開啟後NimoShake會消耗更多記憶體。false:不開啟。
預設值:
false。incr_sync_parallel = falsesource.access_key_id
DynamoDB端的AccessKey ID。
source.access_key_id = xxxxxxxxxxxsource.secret_access_key
DynamoDB端的AccessKey。
source.secret_access_key = xxxxxxxxxxsource.session_token
DynamoDB端的臨時密鑰,如沒有可以不配置。
source.session_token = xxxxxxxxxxsource.region
DynamoDB所屬的地區,如沒有可以不配置。
source.region = us-east-2source.endpoint_url
源端如果是endpoint類型,可以配置該參數。
重要啟用該參數後,上述source相關參數失效。
source.endpoint_url = "http://192.168.0.1:1010"source.session.max_retries
會話失敗後的最大重試次數。
source.session.max_retries = 3source.session.timeout
會話逾時時間,0為不啟用。單位:毫秒。
source.session.timeout = 3000filter.collection.white
資料同步的白名單,設定允許通過的表名。如
filter.collection.white = c1;c2表示允許C1和C2表通過,剩下的表全部過濾。filter.collection.white = c1;c2filter.collection.black
資料同步的黑名單,設定需要過濾的表名。如
filter.collection.black = c1;c2表示過濾掉C1和C2表,剩下的表全部通過。重要不能同時指定filter.collection.white和filter.collection.black參數,否則表示全部表通過。
filter.collection.black = c1;c2qps.full
全量同步階段,限制
Scan命令對錶執行的頻率,表示每秒鐘最多調用多少次Scan。預設值:1000。
qps.full = 1000qps.full.batch_num
全量同步階段,每秒拉取多少條資料。
預設值:128。
qps.full.batch_num = 128qps.incr
增量同步處理階段,限制
GetRecords命令對錶執行的頻率,表示每秒鐘最多調用多少次GetRecords。預設值:1000。
qps.incr = 1000qps.incr.batch_num
增量同步處理階段,每秒拉取多少條資料。
預設值:128。
qps.incr.batch_num = 128target.type
目的端資料庫類型,取值:
mongodb:目的端為MongoDB資料庫。aliyun_dynamo_proxy:目的端為相容DynamoDB協議的MongoDB資料庫。
target.type = mongodbtarget.address
目的端資料庫的串連地址,支援MongoDB的串連串地址和DynamoDB相容串連地址。
擷取MongoDB的地址資訊,請參見複本集執行個體串連說明或分區叢集執行個體串連說明。
target.address = mongodb://username:password@s-*****-pub.mongodb.rds.aliyuncs.com:3717target.mongodb.type
目的端MongoDB資料庫的類型,取值:
replica:複本集。sharding:分區叢集。
target.mongodb.type = shardingtarget.db.exist
目的端重名表的處理方式,取值:
rename:對目的端已存在的重名表進行重新命名,新增時間戳記尾碼,比如c1變為c1.2019-07-01Z12:10:11。警告此操作會修改目的端的表名稱,可能會對業務產生影響,請務必提前做好遷移的準備工作。
drop:刪除目的端的重名表。
如不配置則不做處理,此時如果目的端中有重名表會報錯退出,遷移終止。
target.db.exist = dropsync_schema_only
是否僅同步表的結構。取值:
true:是,僅同步表結構。false:否。
預設值:
false。sync_schema_only = falsefull.concurrency
全量同步階段的表層級並發度,表示一次最多同步多少個表。
預設值:4。
full.concurrency = 4full.read.concurrency
全量階段表內文檔層級並發度,表示1個表最多有幾個線程同時並發讀取源端,對應Scan介面的TotalSegments。
full.read.concurrency = 1full.document.concurrency
全量同步階段參數。表內document的並發度,表示使用多少個線程並發將一個表內的內容寫入目的端。
預設值:4。
full.document.concurrency = 4full.document.write.batch
一次彙總寫入多少條資料,如果目的端是DynamoDB協議最大配置25。
full.document.write.batch = 25full.document.parser
全量同步階段參數。表內解析線程個數,表示使用多少個線程並發將Dynamo協議轉換到目的端對應協議。
預設值:2。
full.document.parser = 2full.enable_index.user
全量同步階段參數。是否同步處理的使用者自建的索引。取值:
true:是。false:否。
預設值:
true。full.enable_index.user = truefull.executor.insert_on_dup_update
全量同步階段參數。在目的端碰到相同key的情況下,是否將
INSERT操作改為UPDATE。取值:true:是。false:否。
預設值:
true。full.executor.insert_on_dup_update = trueincrease.concurrency
增量同步處理階段參數。一次最多並發抓取多少個分區(shard)。
預設值:16。
increase.concurrency = 16increase.executor.insert_on_dup_update
增量同步處理階段參數。在目的端碰到相同key的情況下,是否將
INSERT操作改為UPDATE。取值:true:是。false:否。
預設值:
true。increase.executor.insert_on_dup_update = trueincrease.executor.upsert
增量同步處理階段參數。如果目的端不存在key的情況下,是否將
UPDATE操作改為UPSERT。取值:true:是false:否
說明UPSERT操作會判斷目標key是否存在,如果存在則執行UPDATE操作,如果不存在則執行INSERT操作。
increase.executor.upsert = truecheckpoint.type
用於斷點續傳的位點資訊(Checkpoint)儲存類型。取值:
mongodb:斷點續傳位點資訊(Checkpoint)儲存於MongoDB資料庫中,僅在target.type參數為mongodb時可用。file:斷點續傳位點資訊(Checkpoint)儲存於本機電腦中。
checkpoint.type = mongodbcheckpoint.address
儲存斷點續傳位點資訊(Checkpoint)的地址。
checkpoint.type參數為mongodb:輸入MongoDB資料庫的串連地址。如不配置則預設儲存到目的端的MongoDB庫中。查看MongoDB的地址資訊,請參見複本集執行個體串連說明或分區叢集執行個體串連說明。checkpoint.type參數為file:輸入以nimo-shake運行檔案所在路徑為基準的相對路徑,如:checkpoint。如不配置則預設儲存到checkpoint檔案夾。
checkpoint.address = mongodb://username:password@s-*****-pub.mongodb.rds.aliyuncs.com:3717checkpoint.db
儲存斷點續傳位點資訊(Checkpoint)的MongoDB資料庫名,如不配置則資料庫名的格式預設為
<id>-checkpoint樣本:
nimo-shake-checkpoint。checkpoint.db = nimo-shake-checkpointconvert._id
給DynamoDB中的
_id欄位增加首碼,不和MongoDB的_id衝突。convert._id = prefull.read.filter_expression
全量階段中用於過濾的DynamoDB運算式。
:begin和:end,這兩個冒號開頭的是變數,實際的值在filter_attributevalues中。full.read.filter_expression = create_time > :begin AND create_time < :endfull.read.filter_attributevalues
全量階段中用於過濾的DynamoDB運算式值,對應
filter_expression中指定的變數具體值。N為 Number,S為 String。full.read.filter_attributevalues = begin```N```1646724207280~~~end```N```1646724207283執行如下命令使用配置好的nimo-shake.conf檔案啟動遷移。
./nimo-shake.linux -conf=nimo-shake.conf說明全量同步完成後,螢幕上會列印出
full sync done!。如果中途出錯導致同步終止,程式會自動關閉並在螢幕上列印對應的錯誤資訊,便於您定位錯誤原因。