MaxCompute支援您通過ETL工具Kettle實現MaxCompute作業調度。您可以通過拖拽控制項的方式,方便地定義資料轉送的拓撲結構。本文為您介紹如何通過MaxCompute JDBC驅動,串連Kettle和MaxCompute專案並調度作業。
背景資訊
Kettle是一款開源的ETL工具,純Java實現,可以運行於Windows、Unix、Linux作業系統,為您提供圖形化的操作介面。Kettle支援豐富的輸入輸出資料來源,資料庫支援Oracle、MySQL、DB2等,也支援各種開源的巨量資料系統,例如HDFS、HBase、Cassandra、MongoDB等。
您可以在Kettle中通過建立Job的方式串連MaxCompute專案,並按照ETL流程調度作業。
前提條件
在執行操作前,請確認您已滿足如下條件:
已建立MaxCompute專案。
更多建立MaxCompute專案操作,請參見建立MaxCompute專案。
已擷取可訪問MaxCompute專案的AccessKey ID和AccessKey Secret。
您可以進入AccessKey管理頁面擷取AccessKey ID和AccessKey Secret。
已下載包含完整依賴JAR包
jar-with-dependencies的MaxCompute JDBC驅動(v3.2.8及以上版本)。本文中的MaxCompute JDBC驅動樣本版本為v3.2.9。
已下載Kettle安裝包並解壓至本地路徑。
本文中的Kettle樣本版本為8.2.0.0-342。
操作流程
將MaxCompute JDBC驅動放置於Kettle的驅動目錄下,後續Kettle可通過該驅動訪問MaxCompute專案。
通過配置串連參數,串連Kettle及MaxCompute專案。
在Spoon介面建立作業調度流程並配置作業資訊。
基於建立好的作業調度流程運行作業。
通過SQL編譯器查看作業調度結果。
步驟一:放置MaxCompute JDBC驅動
將MaxCompute JDBC驅動JAR包(例如odps-jdbc-3.2.9-jar-with-dependencies.jar)放置於Kettle的安裝目錄data-integration/lib下。
步驟二:Kettle串連MaxCompute專案
在Kettle的安裝目錄
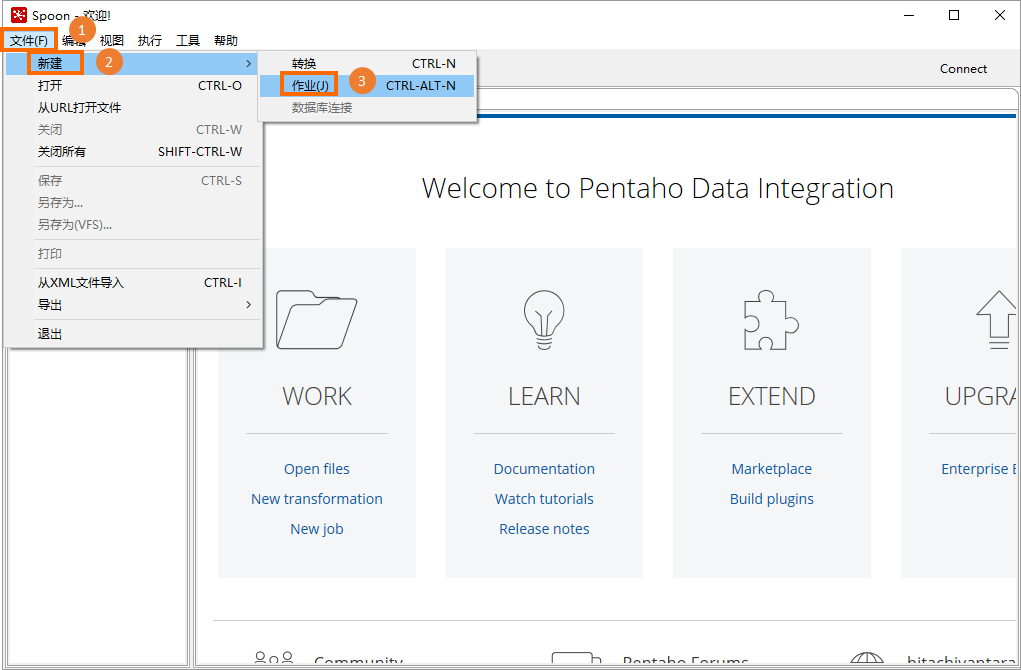
data-integration下,雙擊Spoon.bat(Windows系統)或者雙擊Spoon(macOS系統),即可啟動Spoon,進入Spoon介面。在頂部功能表列,選擇,建立Kettle作業,用於後續建立作業調度流程。
在主對象樹頁簽的DB串連處單擊右鍵選擇建立。
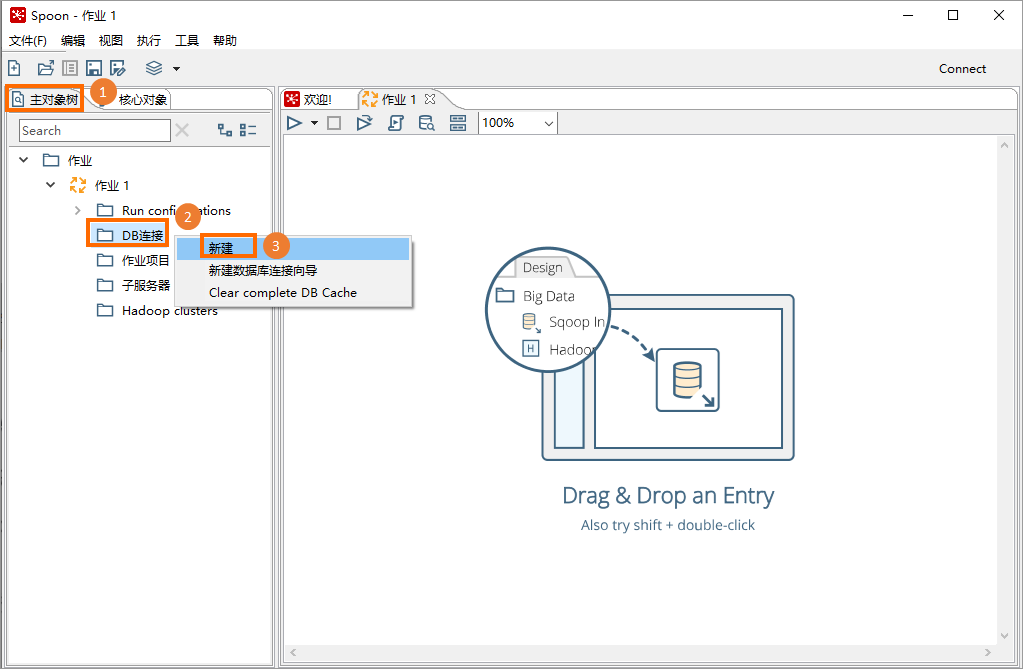
在資料連線對話方塊單擊一般,並配置下表所列參數資訊。
參數
說明
串連名稱
建立資料連線的名稱,用於在系統中區分不同資料庫的串連。例如MaxCompute。
連線類型
固定選擇Generic database。
串連方式
固定選擇Native (JDBC) 。
Dialect
固定選擇Hadoop Hive 2 。
自訂串連URL
串連MaxCompute專案的URL。格式為
jdbc:odps:<MaxCompute_endpoint>?project=<MaxCompute_project_name>。配置時刪除<>符號。參數說明如下:<MaxCompute_endpoint>:必填。MaxCompute專案所屬地區的Endpoint。
各地區的Endpoint資訊,請參見Endpoint。
<MaxCompute_project_name>:必填。待串連的目標MaxCompute專案名稱。
此處為MaxCompute專案名稱,非工作空間名稱。您可以登入MaxCompute控制台,左上方切換地區後,即可在專案管理頁面查看到具體的MaxCompute專案名稱。
自訂驅動類名稱
用於串連MaxCompute專案的驅動程式。固定取值為com.aliyun.odps.jdbc.OdpsDriver。
使用者名稱
具備目標MaxCompute專案存取權限的AccessKey ID。
您可以進入AccessKey管理頁面擷取AccessKey ID。
密碼
AccessKey ID對應的AccessKey Secret。
單擊測試,串連成功後依次單擊確定、確認,完成Kettle和MaxCompute串連。
步驟三:建立作業調度流程
您可以在Spoon介面的核心對象頁簽通過建立、關聯核心對象(作業)的方式構造作業調度流程。
此處以通過LOAD命令從OSS載入資料,並寫入MaxCompute內部表的ETL過程為例為您介紹操作流程,對應樣本資料請參見通過內建Extractor(StorageHandler)匯入資料。該ETL過程涉及的作業可根據核心物件類型拆解如下。
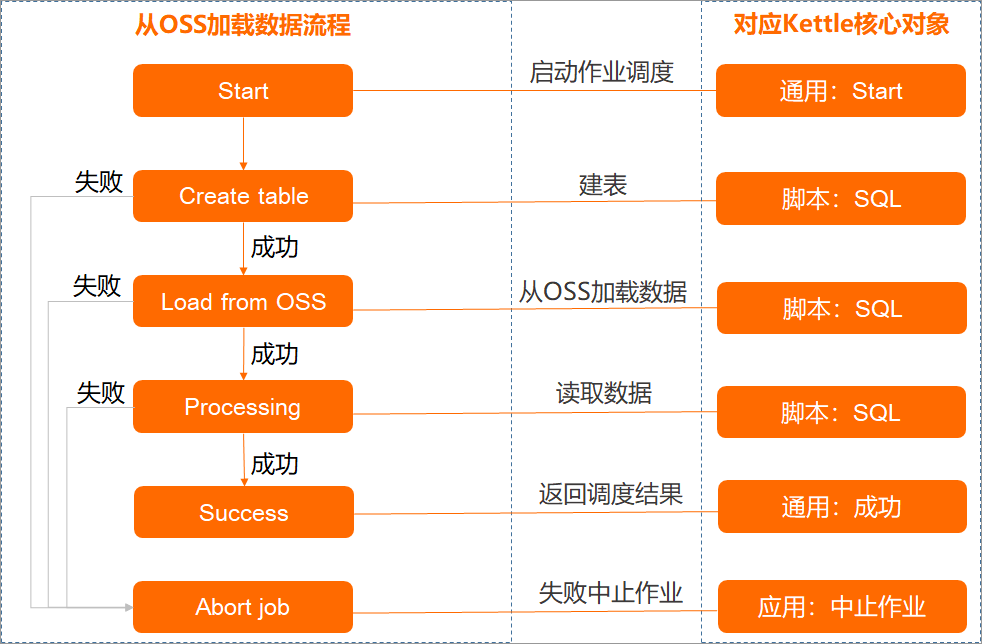
在Spoon介面,單擊核心對象頁簽。
基於上圖拆解的核心對象,從左側導覽列中依次拖拽核心對象組件至右側作業地區中,並按照下圖所示結構串連各核心對象。
串連核心對象的方式為:選中核心對象後,按住Shift同時單擊核心對象,即可出現連接線,串連至目標核心對象即可。
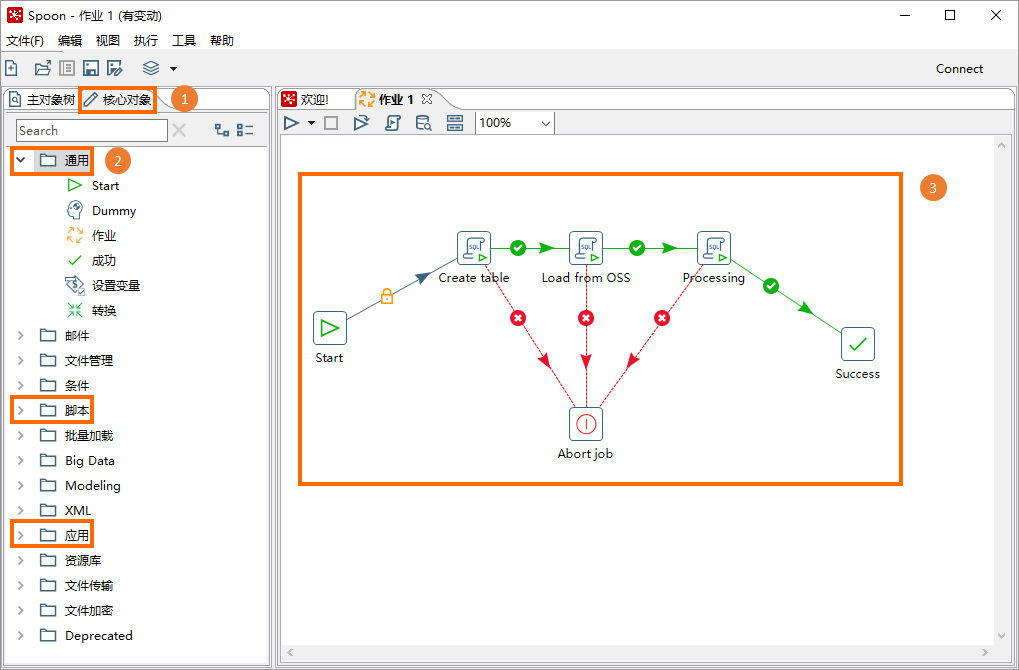
在指令碼類型的核心對象上單擊右鍵,選擇編輯作業入口,在SQL對話方塊配置下表所列參數資訊後,單擊確定。依次完成所有指令碼類型核心對象配置。
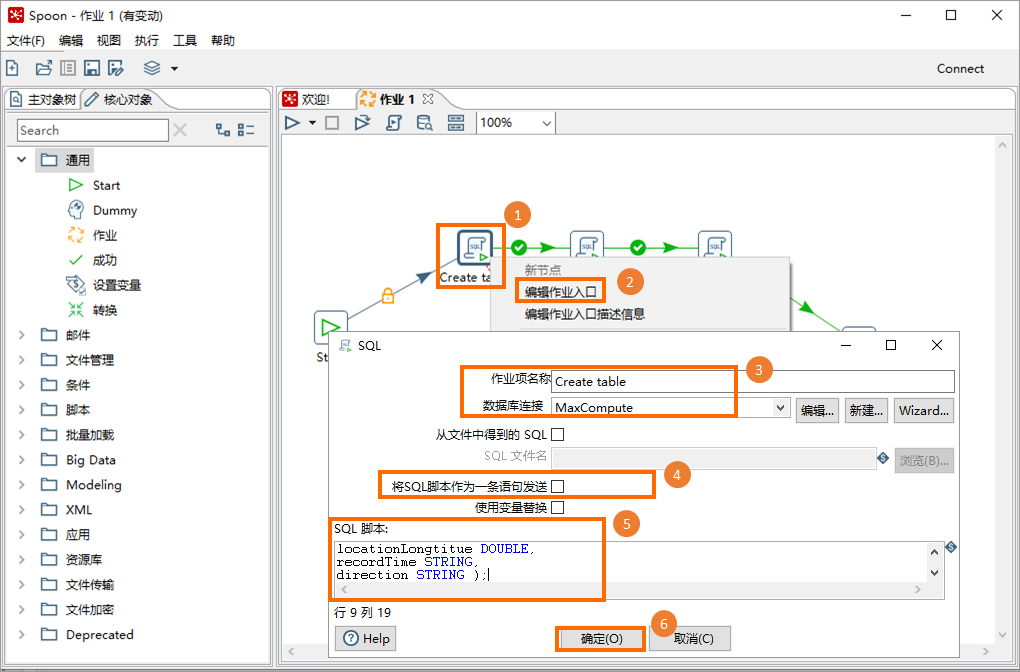
參數
說明
作業項名稱
調度作業的名稱。例如Create table、Load from OSS、Processing。
資料庫連接
訪問的資料連線名稱。即步驟二中建立的資料連線。例如MaxCompute。
將SQL指令碼作為一條語句發送
不選中。
SQL指令碼
調度作業對應的SQL指令碼。樣本中指令碼類型核心對象對應的SQL指令碼如下:
Create table
CREATE TABLE ambulance_data_csv_load ( vehicleId INT, recordId INT, patientId INT, calls INT, locationLatitute DOUBLE, locationLongtitue DOUBLE, recordTime STRING, direction STRING);Load from OSS
LOAD OVERWRITE TABLE ambulance_data_csv_load FROM LOCATION 'oss://oss-cn-hangzhou-internal.aliyuncs.com/mc-test/data_location/' STORED BY 'com.aliyun.odps.CsvStorageHandler' WITH serdeproperties ( 'odps.properties.rolearn'='acs:ram::xxxxx:role/aliyunodpsdefaultrole', --AliyunODPSDefaultRole的ARN資訊,可通過RAM角色管理頁面擷取。 'odps.text.option.delimiter'=',' );Processing
INSERT OVERWRITE TABLE ambulance_data_csv SELECT * FROM ambulance_data_csv_load;
步驟四:運行作業調度流程
在建立的作業調度流程介面,單擊左上方的
 表徵圖後,在執行作業對話方塊右下角單擊執行。
表徵圖後,在執行作業對話方塊右下角單擊執行。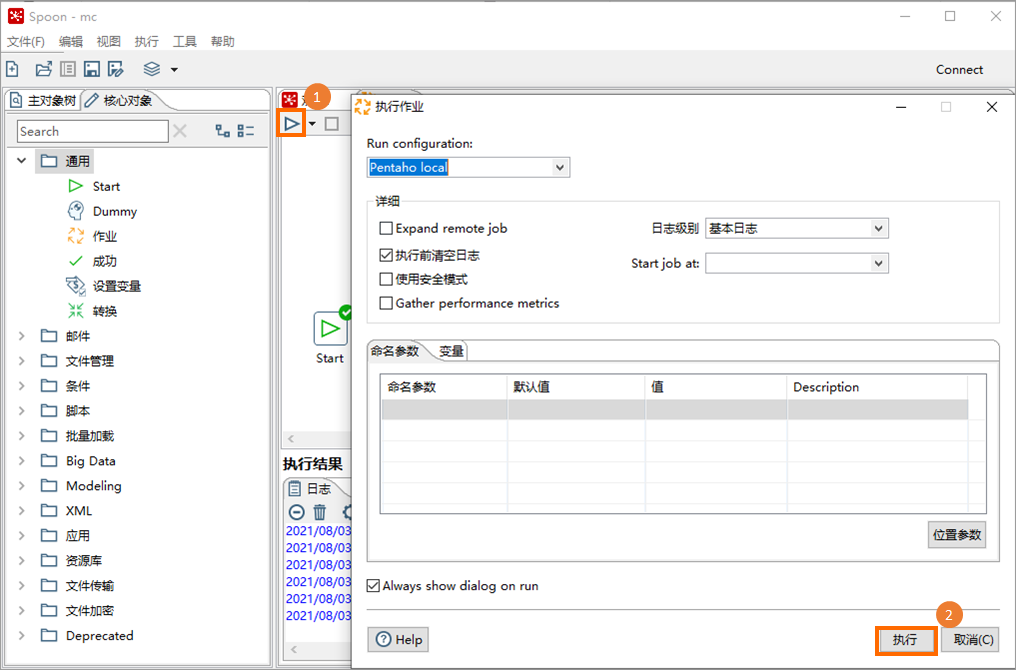
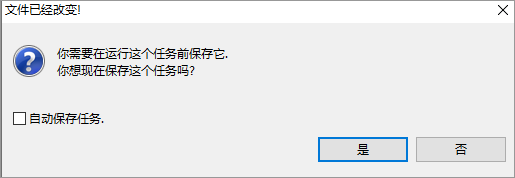
可選:如果彈出如下對話方塊,單擊是,儲存建立的作業調度流程,並按照提示指引命名。例如mc。
通過調度流程介面的DAG圖或執行結果地區查看運行狀態,當呈現下圖所示狀態時,表明作業調度流程運行結束。
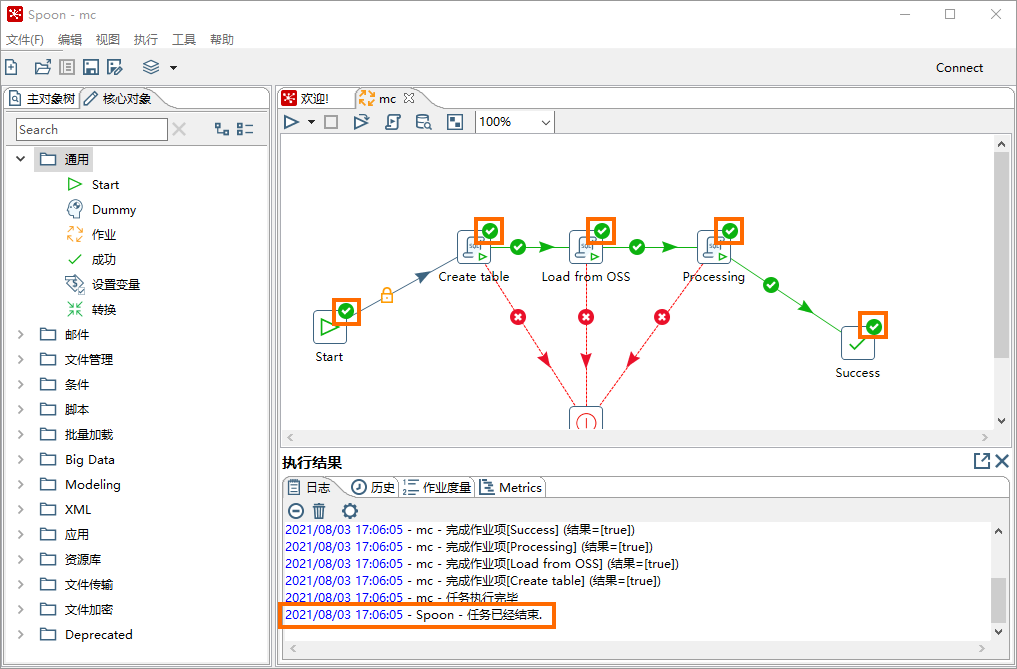
步驟五:查看作業調度結果
作業調度流程運行完成後,通過簡單SQL指令碼查看資料是否成功寫入目標表中。
在Spoon介面單擊主對象樹頁簽,在建立的Kettle作業(例如mc)下單擊DB串連。
在建立的資料連線(例如MaxCompute)上單擊右鍵,選擇SQL編輯器。
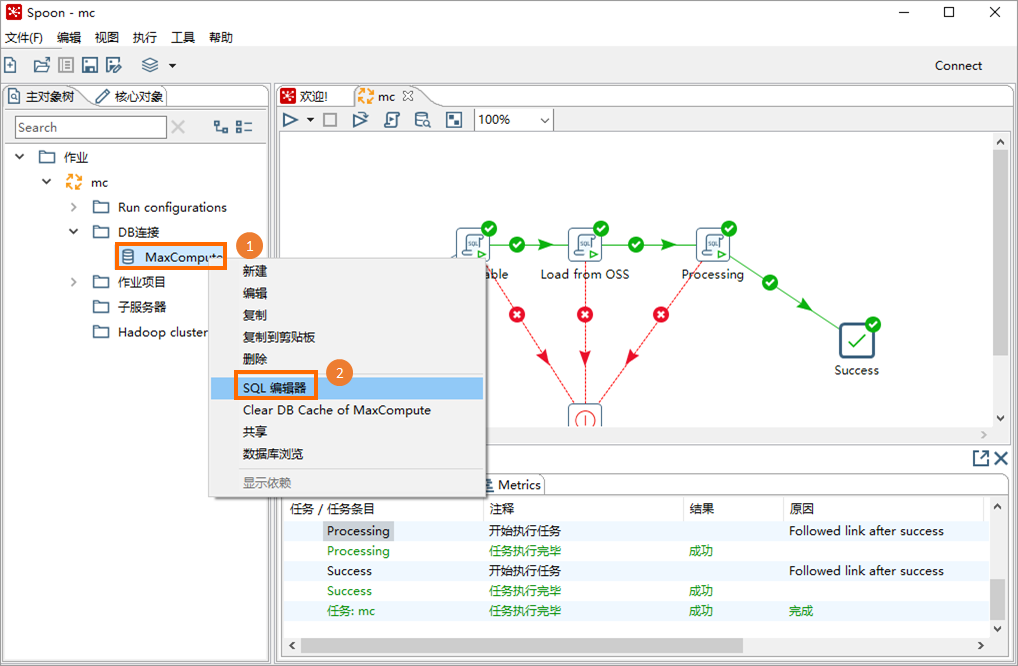
在簡單SQL編輯器對話方塊,輸入SQL指令碼並單擊執行,即可在預覽資料對話方塊查看到查詢結果。
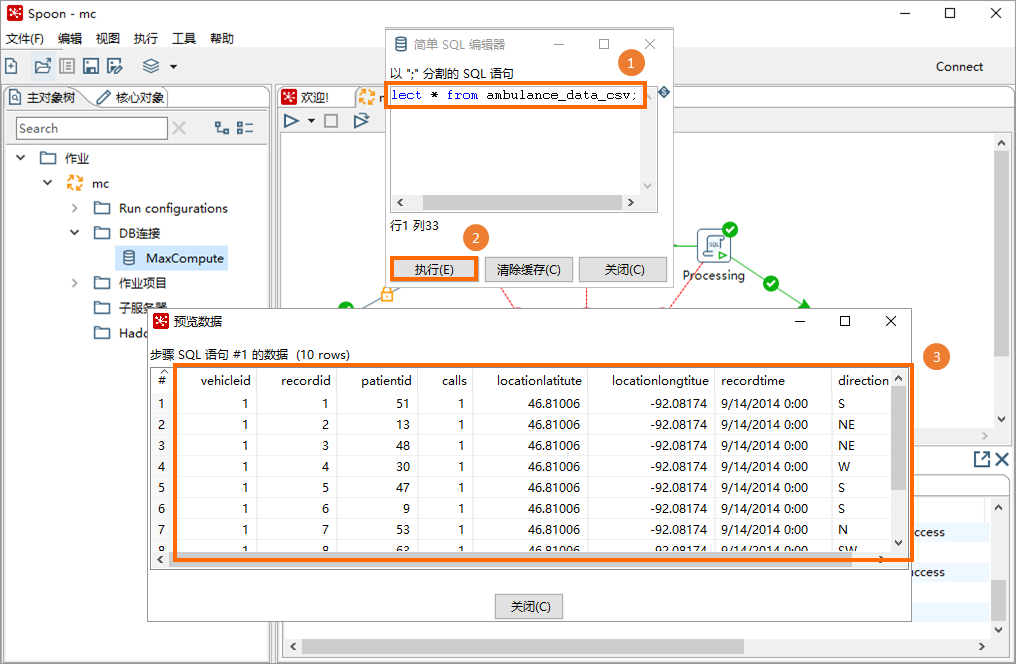 SQL指令碼如下:
SQL指令碼如下:SELECT * FROM ambulance_data_csv;