MaxCompute支援您通過Azkaban實現作業調度,協助您高效地完成高頻資料分析工作。本文以通過MaxCompute用戶端執行命令(Command)的方式為例為您介紹如何使用Azkaban調度SQL作業。
背景資訊
Azkaban是一套作業調度系統,可以調度Command、Hadoop MapReduce、Hive、Spark、Pig等類型作業,而且支援自訂Plugin,其中最簡單而且最常用的是Command類型。更多Azkaban資訊,請參見Azkaban。
您需要將待調度作業依賴的來源資料、建表及匯入資料指令碼、查詢資料指令碼等以檔案形式壓縮後上傳至Azkaban才可進一步實現調度操作。
本文中假設您需要在Azkaban上通過調度功能實現建立表、匯入資料、查詢資料這一套SQL處理邏輯。基於此情境,您可以設計作業、作業調度流程、各作業對應的作業檔案及指令檔如下。

前提條件
- 已下載並安裝MaxCompute用戶端。
更多安裝並配置MaxCompute用戶端操作,請參見安裝並配置MaxCompute用戶端。
- 已下載並安裝Azkaban。
更多下載並安裝Azkaban操作,請參見安裝Azkaban。
操作流程
- 步驟一:準備作業相關檔案並壓縮為ZIP包準備好調度作業依賴的來源資料、指令檔並壓縮為ZIP包。
- 步驟二:將ZIP壓縮包上傳至Azkaban通過Azkaban專案上傳壓縮包檔案,匯入作業調度流程。
- 步驟三:運行Flow View運行匯入的作業調度流程。
- 步驟四:查看Flow View運行結果查看作業調度流程運行結果。
步驟一:準備作業相關檔案並壓縮為ZIP包
- 準備作業相關資料、指令檔並儲存。基於上文的假設情境,您需要準備的檔案如下:
- 來源資料。儲存為TXT檔案。例如emp.txt,包含的資料如下:
7369,SMITH,CLERK,7902,1980-12-17 00:00:00,800,,20 7499,ALLEN,SALESMAN,7698,1981-02-20 00:00:00,1600,300,30 7521,WARD,SALESMAN,7698,1981-02-22 00:00:00,1250,500,30 7566,JONES,MANAGER,7839,1981-04-02 00:00:00,2975,,20 7654,MARTIN,SALESMAN,7698,1981-09-28 00:00:00,1250,1400,30 7698,BLAKE,MANAGER,7839,1981-05-01 00:00:00,2850,,30 7782,CLARK,MANAGER,7839,1981-06-09 00:00:00,2450,,10 7788,SCOTT,ANALYST,7566,1987-04-19 00:00:00,3000,,20 7839,KING,PRESIDENT,,1981-11-17 00:00:00,5000,,10 7844,TURNER,SALESMAN,7698,1981-09-08 00:00:00,1500,0,30 7876,ADAMS,CLERK,7788,1987-05-23 00:00:00,1100,,20 7900,JAMES,CLERK,7698,1981-12-03 00:00:00,950,,30 7902,FORD,ANALYST,7566,1981-12-03 00:00:00,3000,,20 7934,MILLER,CLERK,7782,1982-01-23 00:00:00,1300,,10 7948,JACCKA,CLERK,7782,1981-04-12 00:00:00,5000,,10 7956,WELAN,CLERK,7649,1982-07-20 00:00:00,2450,,10 7956,TEBAGE,CLERK,7748,1982-12-30 00:00:00,1300,,10 - 建表並上傳資料指令碼。儲存為.sql檔案。例如upload.sql,指令碼內容如下:
drop table if exists azkaban_emp; create table azkaban_emp (empno bigint, ename string, job string, mgr bigint, hiredate datetime, sal bigint, comm bigint, deptno bigint) lifecycle 1; tunnel upload emp.txt azkaban_emp; - 查詢資料指令碼。儲存為.sql檔案。例如cat_data.sql,指令碼內容如下:
select * from azkaban_emp; - 啟動作業。儲存為.job檔案。例如start.job,指令碼內容如下:
#start type=command command=echo 'job start' - 上傳資料作業。儲存為.job檔案。例如upload_data.job,指令碼內容如下:
#upload_data type=command dependencies=start command=D:/odpscmd_public/bin/odpscmd.bat -f 'upload.sql'command為MaxCompute用戶端的本地安裝路徑。此處以D:/odpscmd_public/bin/odpscmd.bat作為樣本。 - 查詢資料作業。儲存為.job檔案。例如mc.job,指令碼內容如下:
#mc.job type=command command=D:/odpscmd_public//bin/odpscmd -f 'cat_data.sql' dependencies=upload_datacommand為MaxCompute用戶端的本地安裝路徑。此處以D:/odpscmd_public/bin/odpscmd.bat作為樣本。
- 來源資料。儲存為TXT檔案。例如emp.txt,包含的資料如下:
- 將上述檔案整體壓縮為ZIP包。例如壓縮為demo1.zip,壓縮包內的檔案清單如下圖所示。

步驟二:將ZIP壓縮包上傳至Azkaban
- 登入Azkaban。更多登入操作,請參見登入Azkaban。
- 建立Azkaban專案。更多建立Azkaban專案操作,請參見Create Projects。
- 在新建立的Azkaban專案中上傳步驟一中產生的壓縮包。
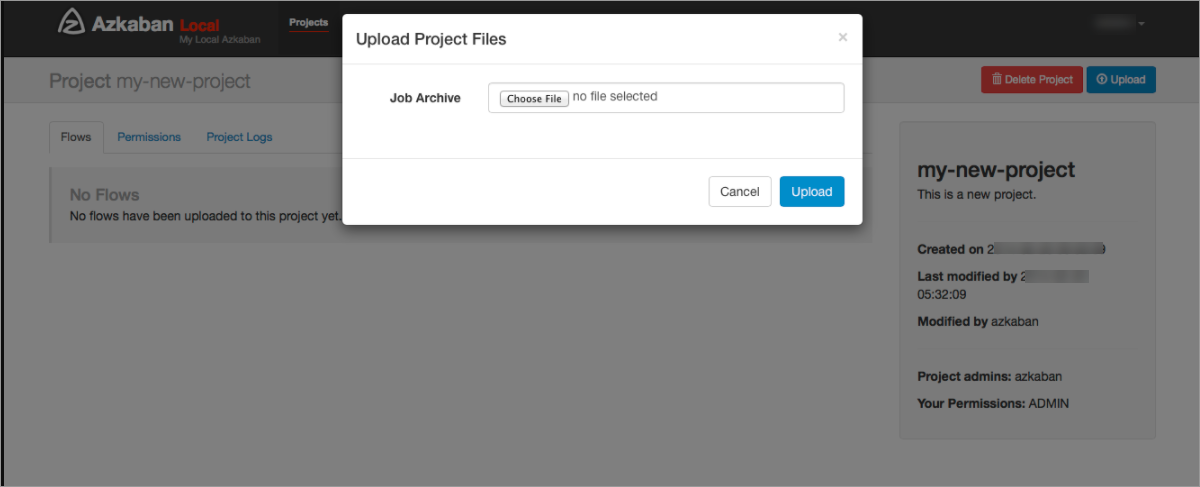 壓縮包上傳成功後,即可在Graph頁簽查看到匯入後的調度流程Flow View。更多查看Flow View操作,請參見
壓縮包上傳成功後,即可在Graph頁簽查看到匯入後的調度流程Flow View。更多查看Flow View操作,請參見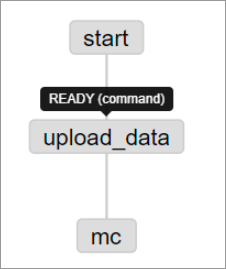
步驟三:運行Flow View
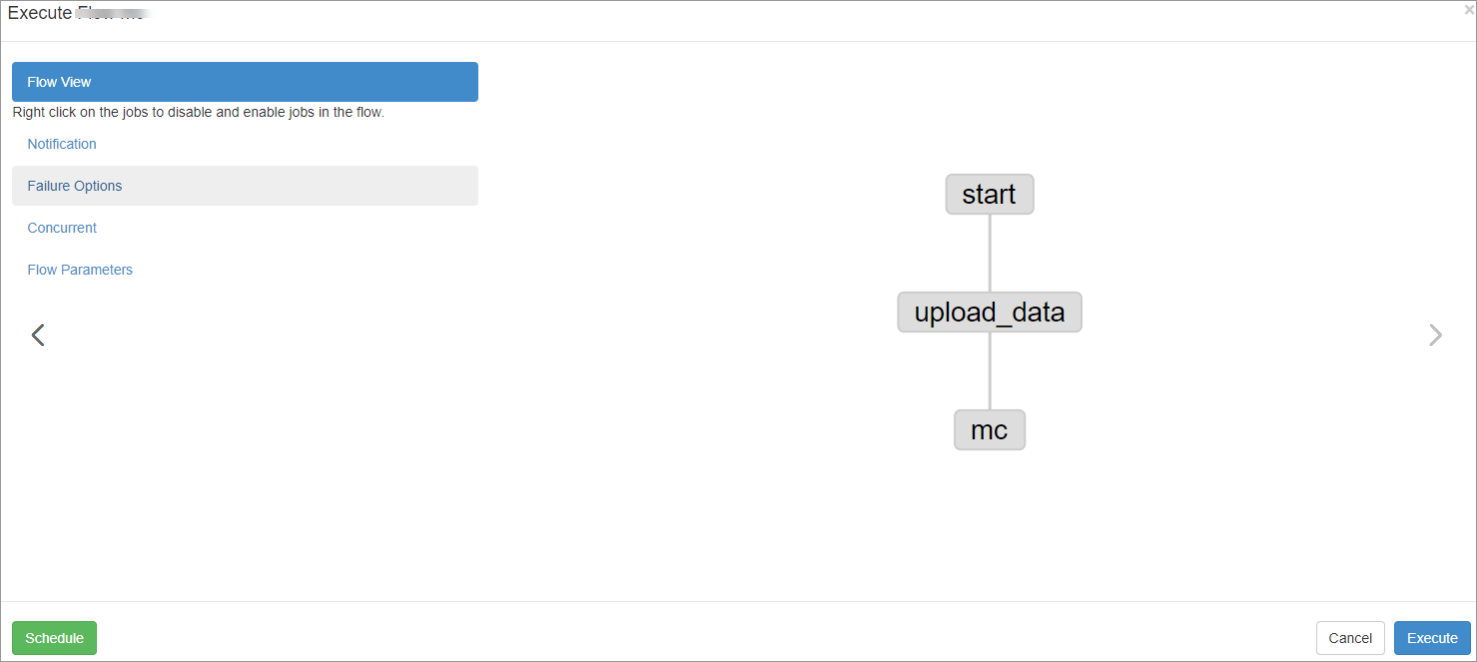
匯入調度流程後,您可以在介面右上方單擊Schedule/Execute Flow進入運行調度作業對話方塊,在Flow View頁簽,您可以單擊右下角的Execute啟動作業調度。
更多運行Flow View操作,請參見Executing Flow View。
步驟四:查看Flow View運行結果
運行結束後,您可以在Execution介面的Job List頁簽查看各個作業的運行結果,還可以單擊作業右側的Details查看詳細運行資訊。
更多查看作業運行結果操作,請參見Execution。
