基於MaxCompute 2.0計算引擎,MaxCompute在UDF架構中引入了新的擴充機制UDJ(User Defined Join),來實現靈活的跨表、多表自訂動作,同時減少通過MapReduce等方式對分布式系統底層細節的操作。
背景資訊
MaxCompute內建了多種Join操作,包括Inner/Right Join、Outer/Left Join、Outer/Full Join、Outer/Semi/Anti-semi Join等。這些內建的Join操作功能強大,但由於其標準的Join實現,無法滿足很多跨表操作的需求情境。
通常,您可以通過UDF(User Defined Function)描述代碼架構,但現有的UDF/UDTF/UDAF介面主要是針對在單個資料表上的操作而設計。一旦涉及多表的自訂動作,經常還需要依賴於內建Join +各種UDF/UDTF,並配合比較複雜的SQL語句來完成。在多表操作的情境上,您不得不放棄SQL而使用自訂MapReduce,才能完成所需的計算。
無論是Join +各種UDF/UDTF+複雜SQL還是自訂MapReduce門檻都比較高,同時還會帶來一些問題:
使用Join +各種UDF/UDTF+複雜SQL:多個複雜的Join和散布在SQL語言各處的代碼揉合在一起,將帶來多處的邏輯黑盒,不利於產生最優的執行計畫。
使用MapReduce:不僅更大程度上限制了系統進行執行最佳化的可能性,而且在深度最佳化本地運行代碼時,由於MapReduce絕大部分代碼由Java完成,在執行效率上會遠低於MaxCompute基於LLVM的代碼產生器。
使用限制
目前版本不支援使用UDF/UDAF/UDTF讀取以下情境的表資料:
做過表結構修改(Schema Evolution)的表資料。
包含複雜資料類型的表資料。
包含JSON資料類型的表資料。
Transactional表的表資料。
UDJ的效能
通過一個真實的線上MapReduce作業進行測實驗證UDJ的效能,該MapReduce作業實現一套比較複雜的演算法。將兩個表合并在一起,用UDJ對該MapReduce進行改寫,並且驗證UDJ實現結果的正確性。在並發度相同的情況下,兩者效能對比如下。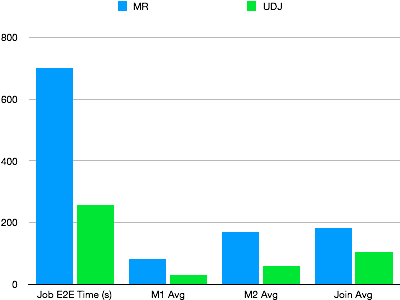
由上圖可見,UDJ介面的引入,一方面讓您能更方便地描述對多表資料進行操作的複雜邏輯,一方面大幅提升了效能。代碼只在UDJ內被調用,其上下遊的邏輯(例如該樣本中的整個Mapper邏輯)則完全通過MaxCompute高效的Native運行完成。在Java代碼中,由於MaxCompute UDJ運行引擎和Java介面之間的資料互動邏輯有深度的最佳化,通過UDJ實現的Join邏輯也比其對等的Reducer更高效。
UDJ跨表Join功能
通過如下範例為您詳細介紹MaxCompute UDJ跨表Join的使用方法。
假設存在兩個日誌表,分別是payment和user_client_log。
payment:表中儲存了使用者的支付記錄,每一筆支付記錄包含使用者ID、支付時間和支付內容。範例資料如下。
user_id
time
pay_info
2656199
2018-02-13 22:30:00
gZhvdySOQb
8881237
2018-02-13 08:30:00
pYvotuLDIT
8881237
2018-02-13 10:32:00
KBuMzRpsko
user_client_log:儲存了使用者的用戶端日誌,每一條日誌包含了使用者ID、日誌時間和日誌內容。範例資料如下。
user_id
time
content
8881237
2018-02-13 00:30:00
click MpkvilgWSmhUuPn
8881237
2018-02-13 06:14:00
click OkTYNUHMqZzlDyL
8881237
2018-02-13 10:30:00
click OkTYNUHMqZzlDyL
對於每一條用戶端日誌,找出該使用者在payment表裡時間最接近的一條支付記錄,將其中的支付內容和日誌內容合并輸出。達到如下效果。
user_id | time | content |
8881237 | 2018-02-13 00:30:00 | click MpkvilgWSmhUuPn, pay pYvotuLDIT |
8881237 | 2018-02-13 06:14:00 | click OkTYNUHMqZzlDyL, pay pYvotuLDIT |
8881237 | 2018-02-13 10:30:00 | click OkTYNUHMqZzlDyL, pay KBuMzRpsko |
面對此類需求通常有如下2種解決方案:
使用內建Join。SQL虛擬碼如下。
SELECT p.user_id, p.time, MERGE(p.pay_info, u.content) FROM payment p RIGHT OUTER JOIN user_client_log u ON p.user_id = u.user_id AND ABS(p.time - u.time) = MIN(ABS(p.time - u.time))關聯時需要知道相同user_id下的p.time與u.time差異最小的值,且彙總函式不能出現在關聯條件上。因此,這個看似簡單的需求,無法通過標準的關聯操作實現。
使用UDJ方法實現。
註冊UDJ函數。
配置新版本的SDK。
<dependency> <groupId>com.aliyun.odps</groupId> <artifactId>odps-sdk-udf</artifactId> <version>0.29.10-public</version> <scope>provided</scope> </dependency>編寫UDJ代碼,並將代碼打包為odps-udj-example.jar。
package com.aliyun.odps.udf.example.udj; import com.aliyun.odps.Column; import com.aliyun.odps.OdpsType; import com.aliyun.odps.Yieldable; import com.aliyun.odps.data.ArrayRecord; import com.aliyun.odps.data.Record; import com.aliyun.odps.udf.DataAttributes; import com.aliyun.odps.udf.ExecutionContext; import com.aliyun.odps.udf.UDJ; import com.aliyun.odps.udf.annotation.Resolve; import java.util.ArrayList; import java.util.Iterator; /** 對於右表的每個記錄,找到最近的左表記錄 * 合并兩條記錄。 */ @Resolve("->string,bigint,string") public class PayUserLogMergeJoin extends UDJ { private Record outputRecord; /** 將在資料處理階段之前調用。 使用者可以實施這個方法做初始化工作。 */ @Override public void setup(ExecutionContext executionContext, DataAttributes dataAttributes) { // outputRecord = new ArrayRecord(new Column[]{ new Column("user_id", OdpsType.STRING), new Column("time", OdpsType.BIGINT), new Column("content", OdpsType.STRING) }); } /** Override this method to implement join logic. * @param key Current join key * @param left Group of records of left table corresponding to the current key * @param right Group of records of right table corresponding to the current key * @param output Used to output the result of UDJ */ @Override public void join(Record key, Iterator<Record> left, Iterator<Record> right, Yieldable<Record> output) { outputRecord.setString(0, key.getString(0)); if (!right.hasNext()) { // 空右組,什麼都不做。 return; } else if (!left.hasNext()) { // 空左組。 輸出右側組的所有記錄而不合并。 while (right.hasNext()) { Record logRecord = right.next(); outputRecord.setBigint(1, logRecord.getDatetime(0).getTime()); outputRecord.setString(2, logRecord.getString(1)); output.yield(outputRecord); } return; } ArrayList<Record> pays = new ArrayList<>(); // 左側記錄組將從開始到結束迭代。 // 對於右組的每個記錄,迭代器無法重設。 // 所以我們將左邊的每個記錄儲存到ArrayList。 left.forEachRemaining(pay -> pays.add(pay.clone())); while (right.hasNext()) { Record log = right.next(); long logTime = log.getDatetime(0).getTime(); long minDelta = Long.MAX_VALUE; Record nearestPay = null; // 迭代左邊的所有記錄,找到有的記錄時間上的微小差異。 for (Record pay: pays) { long delta = Math.abs(logTime - pay.getDatetime(0).getTime()); if (delta < minDelta) { minDelta = delta; nearestPay = pay; } } // 將日誌記錄與最近的支付記錄合并,並輸出到結果。 outputRecord.setBigint(1, log.getDatetime(0).getTime()); outputRecord.setString(2, mergeLog(nearestPay.getString(1), log.getString(1))); output.yield(outputRecord); } } String mergeLog(String payInfo, String logContent) { return logContent + ", pay " + payInfo; } @Override public void close() { } }在MaxCompute中添加Jar包資源。
ADD jar odps-udj-example.jar;在MaxCompute中註冊UDF函數pay_user_log_merge_join。
CREATE FUNCTION pay_user_log_merge_join AS 'com.aliyun.odps.udf.example.udj.PayUserLogMergeJoin' USING 'odps-udj-example.jar';
準備樣本資料。
建立樣本表payment和user_client_log。
CREATE TABLE payment(user_id STRING,time DATETIME,pay_info STRING); CREATE TABLE user_client_log(user_id STRING,time DATETIME,content STRING);為樣本表中插入資料。
--向payment表中插入資料。 INSERT OVERWRITE TABLE payment VALUES ('1335656', datetime '2018-02-13 19:54:00', 'PEqMSHyktn'), ('2656199', datetime '2018-02-13 12:21:00', 'pYvotuLDIT'), ('2656199', datetime '2018-02-13 20:50:00', 'PEqMSHyktn'), ('2656199', datetime '2018-02-13 22:30:00', 'gZhvdySOQb'), ('8881237', datetime '2018-02-13 08:30:00', 'pYvotuLDIT'), ('8881237', datetime '2018-02-13 10:32:00', 'KBuMzRpsko'), ('9890100', datetime '2018-02-13 16:01:00', 'gZhvdySOQb'), ('9890100', datetime '2018-02-13 16:26:00', 'MxONdLckwa') ; --向user_client_log表中插入資料。 INSERT OVERWRITE TABLE user_client_log VALUES ('1000235', datetime '2018-02-13 00:25:36', 'click FNOXAibRjkIaQPB'), ('1000235', datetime '2018-02-13 22:30:00', 'click GczrYaxvkiPultZ'), ('1335656', datetime '2018-02-13 18:30:00', 'click MxONdLckpAFUHRS'), ('1335656', datetime '2018-02-13 19:54:00', 'click mKRPGOciFDyzTgM'), ('2656199', datetime '2018-02-13 08:30:00', 'click CZwafHsbJOPNitL'), ('2656199', datetime '2018-02-13 09:14:00', 'click nYHJqIpjevkKToy'), ('2656199', datetime '2018-02-13 21:05:00', 'click gbAfPCwrGXvEjpI'), ('2656199', datetime '2018-02-13 21:08:00', 'click dhpZyWMuGjBOTJP'), ('2656199', datetime '2018-02-13 22:29:00', 'click bAsxnUdDhvfqaBr'), ('2656199', datetime '2018-02-13 22:30:00', 'click XIhZdLaOocQRmrY'), ('4356142', datetime '2018-02-13 18:30:00', 'click DYqShmGbIoWKier'), ('4356142', datetime '2018-02-13 19:54:00', 'click DYqShmGbIoWKier'), ('8881237', datetime '2018-02-13 00:30:00', 'click MpkvilgWSmhUuPn'), ('8881237', datetime '2018-02-13 06:14:00', 'click OkTYNUHMqZzlDyL'), ('8881237', datetime '2018-02-13 10:30:00', 'click OkTYNUHMqZzlDyL'), ('9890100', datetime '2018-02-13 16:01:00', 'click vOTQfBFjcgXisYU'), ('9890100', datetime '2018-02-13 16:20:00', 'click WxaLgOCcVEvhiFJ') ;
在SQL中使用UDJ。
SELECT r.user_id, FROM_UNIXTIME(CAST(time/1000 AS BIGINT)) AS time, content FROM ( SELECT user_id, time AS time, pay_info FROM payment ) p JOIN ( SELECT user_id, time AS time, content FROM user_client_log ) u ON p.user_id = u.user_id USING pay_user_log_merge_join(p.time, p.pay_info, u.time, u.content) r AS (user_id, time, content);USING子句中的參數說明:
pay_user_log_merge_join是註冊的UDJ在SQL中的函數名。(p.time, p.pay_info, u.time, u.content)是UDJ中用到的左右表的列。r是UDJ結果的別名,方便其他地方引用UDJ的結果。(user_id, time, content)是UDJ產生的結果的列名。
運行結果如下。
+---------+------------+---------+ | user_id | time | content | +---------+------------+---------+ | 1000235 | 2018-02-13 00:25:36 | click FNOXAibRjkIaQPB | | 1000235 | 2018-02-13 22:30:00 | click GczrYaxvkiPultZ | | 1335656 | 2018-02-13 18:30:00 | click MxONdLckpAFUHRS, pay PEqMSHyktn | | 1335656 | 2018-02-13 19:54:00 | click mKRPGOciFDyzTgM, pay PEqMSHyktn | | 2656199 | 2018-02-13 08:30:00 | click CZwafHsbJOPNitL, pay pYvotuLDIT | | 2656199 | 2018-02-13 09:14:00 | click nYHJqIpjevkKToy, pay pYvotuLDIT | | 2656199 | 2018-02-13 21:05:00 | click gbAfPCwrGXvEjpI, pay PEqMSHyktn | | 2656199 | 2018-02-13 21:08:00 | click dhpZyWMuGjBOTJP, pay PEqMSHyktn | | 2656199 | 2018-02-13 22:29:00 | click bAsxnUdDhvfqaBr, pay gZhvdySOQb | | 2656199 | 2018-02-13 22:30:00 | click XIhZdLaOocQRmrY, pay gZhvdySOQb | | 4356142 | 2018-02-13 18:30:00 | click DYqShmGbIoWKier | | 4356142 | 2018-02-13 19:54:00 | click DYqShmGbIoWKier | | 8881237 | 2018-02-13 00:30:00 | click MpkvilgWSmhUuPn, pay pYvotuLDIT | | 8881237 | 2018-02-13 06:14:00 | click OkTYNUHMqZzlDyL, pay pYvotuLDIT | | 8881237 | 2018-02-13 10:30:00 | click OkTYNUHMqZzlDyL, pay KBuMzRpsko | | 9890100 | 2018-02-13 16:01:00 | click vOTQfBFjcgXisYU, pay gZhvdySOQb | | 9890100 | 2018-02-13 16:20:00 | click WxaLgOCcVEvhiFJ, pay MxONdLckwa | +---------+------------+---------+
UDJ預排序功能
為了找到payment值相差最小的一條記錄,需要反覆對payment表的資料進行iterator遍曆。所以事先將相同user_id的payment記錄全部載入到了ArrayList,該方法適用於同一個使用者一天之內的支付行為較少的情境。在其他情境中,有時同組內的資料量可能非常大,以至於無法在記憶體中存放,此時,您可以通過SORT BY預排序解決。
當某個使用者的支付資料量非常大,導致無法將payment放在記憶體中時,如果組內所有資料已經按照時間排序,則只需要比較兩邊iterator最頂部的資料,即可實現該功能。
Java UDJ代碼如下。
@Override
public void join(Record key, Iterator<Record> left, Iterator<Record> right, Yieldable<Record> output) {
outputRecord.setString(0, key.getString(0));
if (!right.hasNext()) {
return;
} else if (!left.hasNext()) {
while (right.hasNext()) {
Record logRecord = right.next();
outputRecord.setBigint(1, logRecord.getDatetime(0).getTime());
outputRecord.setString(2, logRecord.getString(1));
output.yield(outputRecord);
}
return;
}
long prevDelta = Long.MAX_VALUE;
Record logRecord = right.next();
Record payRecord = left.next();
Record lastPayRecord = payRecord.clone();
while (true) {
long delta = logRecord.getDatetime(0).getTime() - payRecord.getDatetime(0).getTime();
if (left.hasNext() && delta > 0) {
//兩個記錄之間的時間差正在減少,我們仍然可以操作。
//探索左側組以嘗試獲得更小的增量。
lastPayRecord = payRecord.clone();
prevDelta = delta;
payRecord = left.next();
} else {
//到達最小delta點。 檢查最後的記錄,
//輸出合并結果並準備處理下一條記錄。
//右組。
Record nearestPay = Math.abs(delta) < prevDelta ? payRecord : lastPayRecord;
outputRecord.setBigint(1, logRecord.getDatetime(0).getTime());
String mergedString = mergeLog(nearestPay.getString(1), logRecord.getString(1));
outputRecord.setString(2, mergedString);
output.yield(outputRecord);
if (right.hasNext()) {
logRecord = right.next();
prevDelta = Math.abs(
logRecord.getDatetime(0).getTime() - lastPayRecord.getDatetime(0).getTime()
);
} else {
break;
}
}
}
}Java UDJ代碼修改後,需同步更新對應JAR包以確保邏輯生效。
在UDJ語句末尾添加 SORT BY 子句,指定UDJ組內左右表分別都按照各自的time欄位進行排序。SQL代碼如下。
SELECT r.user_id, from_unixtime(CAST(time/1000 AS BIGINT)) AS time, content FROM (
SELECT user_id, time AS time, pay_info FROM payment
) p JOIN (
SELECT user_id, time AS time, content FROM user_client_log
) u
ON p.user_id = u.user_id
USING pay_user_log_merge_join(p.time, p.pay_info, u.time, u.content)
r
AS (user_id, time, content)
SORT BY p.time, u.time;該運行結果與UDJ跨表Join功能樣本的運行結果一致。該方式主要是使用SORT BY子句對UDJ的資料進行預排序,在這個過程中,最多隻需要同時緩衝3條記錄,就可以實現和之前演算法相同的功能。