Python官方即將停止維護Python 2,MaxCompute已支援Python 3,對應版本為CPython-3.7.3。本文為您介紹如何通過Python 3語言編寫UDAF。
UDAF代碼結構
- 匯入模組:必選。
至少要包含
from odps.udf import annotate和from odps.udf import BaseUDAF。from odps.udf import annotate用於匯入函數簽名模組,MaxCompute才可以識別後續代碼中定義的函數簽名。from odps.udf import BaseUDAF為Python UDAF的基類,您需要通過此類在衍生類別中實現iterate、merge、terminate等方法。當UDAF代碼中需要引用檔案資源或表資源時,需要包含
from odps.distcache import get_cache_file(檔案資源)或from odps.distcache import get_cache_table(表資源)。 - 函數簽名:必選。
格式為
@annotate(<signature>),signature用於定義函數的輸入參數和傳回值的資料類型。更多函數簽名資訊,請參見函數簽名及資料類型。 - 自訂Python類(衍生類別):必選。
UDAF代碼的組織單位,定義了實現業務需求的變數及方法。您還可以在代碼中引用MaxCompute內建的第三方庫或引用檔案、表資源。更多資訊,請參見第三方庫或引用資源。
- 實現Python類的方法:必選。
Python類實現包含如下4個方法,您可以根據實際需要進行選擇。
方法定義 描述 BaseUDAF.new_buffer()返回彙總函式的中間值的buffer。 buffer必須是Marshal對象(例如LIST、DICT),並且buffer的大小不應該隨資料量遞增。在極限情況下,buffer在執行對象序列化後的大小不應該超過2 MB。BaseUDAF.iterate(buffer[, args, ...])將 args彙總到中間值buffer中。BaseUDAF.merge(buffer, pbuffer)將中間值 buffer和pbuffer合并的結果存放在buffer中。BaseUDAF.terminate(buffer)將 buffer轉換為MaxCompute SQL的基本類型。
#匯入函數簽名模組及基類。
from odps.udf import annotate
from odps.udf import BaseUDAF
#函數簽名。
@annotate('double->double')
#自訂Python類。
class Average(BaseUDAF):
#實現Python類的方法。
def new_buffer(self):
return [0, 0]
def iterate(self, buffer, number):
if number is not None:
buffer[0] += number
buffer[1] += 1
def merge(self, buffer, pbuffer):
buffer[0] += pbuffer[0]
buffer[1] += pbuffer[1]
def terminate(self, buffer):
if buffer[1] == 0:
return 0.0
return buffer[0] / buffer[1]avg的MaxCompute UDAF的實現邏輯及計算流程如下。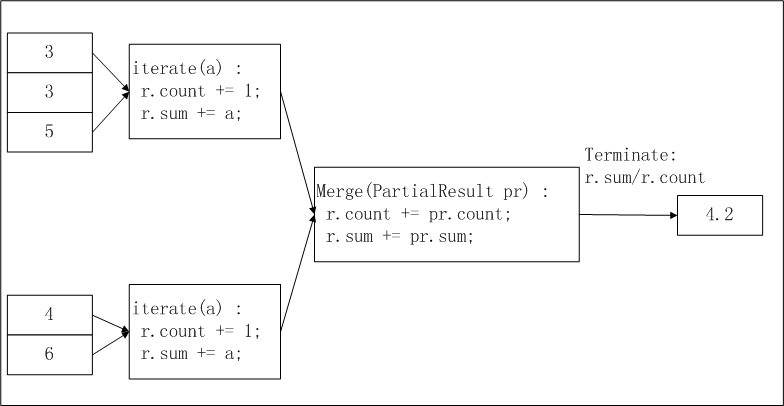
pbuffer相當於上圖中的pr,buffer相當於上圖中的r。注意事項
Python 3與Python 2不相容。在您使用Python 3之前,需要考慮相容性問題,在一個SQL中不允許同時使用Python 3和Python 2。
Python官方已於2020年初停止維護,建議您根據項目類型執行遷移操作:全新專案:新MaxCompute停止維護Python 2,
Python 2 UDAF遷移
- 全新專案:新MaxCompute專案,或第一次使用Python語言編寫UDAF的MaxCompute專案。建議所有的Python UDAF都直接使用Python 3語言編寫。
- 存量專案:建立了大量Python 2 UDAF的MaxCompute專案。請您謹慎開啟Python 3。如果您計劃逐步將所有Python 2 UDAF遷移為Python 3 UDAF,推薦方法如下:
- 新作業和新UDAF:使用Python 3語言編寫,在Session層級開啟Python 3。開啟Python 3方法,請參見開啟Python 3。
- Python 2 UDAF:改寫Python 2 UDAF,使其可以同時相容Python 2和Python 3。改寫方法請參見將Python 2代碼移植到Python 3。說明 如果您需要編寫公用UDAF,並為多個MaxCompute專案授權UDAF的操作許可權,建議UDAF同時相容Python 2和Python 3。
第三方庫
MaxCompute內建的Python 3運行環境中未安裝第三方庫Numpy。如果您需要使用Numpy的UDAF,請手動上傳Numpy的WHEEL包。從PyPI或鏡像下載Numpy包時,包的檔案名稱為numpy-<版本號碼>-cp37-cp37m-manylinux1_x86_64.whl。上傳包的操作請參見資源操作或UDF樣本:Python UDF使用第三方包。
函數簽名及資料類型
@annotate(<signature>)signature為字串,用於標識輸入參數和傳回值的資料類型。執行UDAF時,UDAF函數的輸入參數和傳回值類型要與函數簽名指定的類型一致。查詢語義解析階段會檢查不符合函數簽名定義的用法,檢查到類型不符時會報錯。具體格式如下。'arg_type_list -> type'arg_type_list:表示輸入參數的資料類型。輸入參數可以為多個,用英文逗號(,)分隔。支援的資料類型為BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、複雜資料類型(ARRAY、MAP、STRUCT)或複雜資料類型嵌套。arg_type_list還支援星號(*)或為空白(''):當
arg_type_list為星號(*)時,表示輸入參數為任意個數。當
arg_type_list為空白('')時,表示無輸入參數。
type:表示傳回值的資料類型。UDAF只返回一列。支援的資料類型為:BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、複雜資料類型(ARRAY、MAP、STRUCT)或複雜資料類型嵌套。
合法函數簽名樣本如下。
| 函數簽名樣本 | 說明 |
@annotate('bigint,double->string') | 輸入參數類型為BIGINT、DOUBLE,傳回值類型為STRING。 |
@annotate('*->string') | 輸入任意個參數,傳回值類型為STRING。 |
@annotate('->double') | 無輸入參數,傳回值類型為DOUBLE。 |
@annotate('array<bigint>->struct<x:string, y:int>') | 輸入參數類型為ARRAY<BIGINT>,傳回值類型為STRUCT<x:STRING, y:INT>。 |
為確保編寫Python UDAF過程中使用的資料類型與MaxCompute支援的資料類型保持一致,您需要關注二者間的資料類型映射關係。具體映射關係如下。
MaxCompute SQL Type | Python 3 Type |
BIGINT | INT |
STRING | UNICODE |
DOUBLE | FLOAT |
BOOLEAN | BOOL |
DATETIME | DATETIME.DATETIME |
FLOAT | FLOAT |
CHAR | UNICODE |
VARCHAR | UNICODE |
BINARY | BYTES |
DATE | DATETIME.DATE |
DECIMAL | DECIMAL.DECIMAL |
ARRAY | LIST |
MAP | DICT |
STRUCT | COLLECTIONS.NAMEDTUPLE |
引用資源
Python UDAF可以通過odps.distcache模組引用資源,支援引用檔案資源和表資源。
odps.distcache.get_cache_file(resource_name):返回指定檔案資源的內容。resource_name為STRING類型,對應當前MaxCompute專案中已存在的檔案資源名。如果檔案資源名非法或者沒有相應的檔案資源,會返回異常。說明 使用UDAF訪問資源,在建立UDAF時需要聲明引用的資源,否則會報錯。- 傳回值為File-like對象。在使用完此對象後,您需要調用
close方法釋放開啟的資源檔。
odps.distcache.get_cache_table(resource_name):返回指定表資源的內容。resource_name支援STRING類型,對應當前MaxCompute專案中已存在的表資源名。如果表資源名非法或者沒有相應的表資源,會返回異常。- 傳回值為GENERATOR類型,調用者以遍曆方式擷取表的內容,每次遍曆可得到以數組形式存在的表中的一條記錄。
具體使用方法請參見引用資源(Python UDF 3)和引用資源(Python UDTF 3)。
使用說明
在歸屬MaxCompute專案中使用自訂函數:使用方法與內建函數類似,您可以參照內建函數的使用方法使用自訂函數。
跨專案使用自訂函數:即在專案A中使用專案B的自訂函數,跨專案分享語句樣本:
select B:udf_in_other_project(arg0, arg1) as res from table_t;。更多跨專案分享資訊,請參見基於Package跨專案訪問資源。
使用MaxCompute Studio完整開發及調用Python 3 UDAF的操作,請參見開發Python UDF。
UDAF的動態參數說明
函數簽名
- 您可以在參數列表中使用
*,表示接受任意長度、任意類型的輸入參數。例如@annotate('double,*->string')表示接受第一個參數是DOUBLE類型,後接任意長度、任意類型的參數列表。此時,您需要自己編寫代碼判斷輸入的個數和參數類型,然後對它們進行相應的操作(您可以對比C語言裡面的printf函數來理解此操作)。說明*用在傳回值列表中時,表示的是不同的含義。 - UDAF的傳回值可以使用
*,表示返回任意個STRING類型。傳回值的個數與調用函數時設定的別名個數有關。例如@annotate("bigint,string->double,*"),調用方式是UDTF(x, y) as (a, b, c),此處as後面設定了三個別名,即a、b、c。編輯器會認定a為DOUBLE類型(Annotation中傳回值第一列的類型是給定的),b和c為STRING類型。因為這裡給出了三個傳回值,所以UDTF在調用forward時,forward必須是長度為3的數組,否則會出現運行時報錯。說明 這種錯誤無法在編譯時間報出,因此UDTF的調用者在SQL中設定alias個數時,必須遵循該UDAF定義的規則。由於彙總函式的傳回值個數固定是1,所以這個功能對UDAF來說並無意義。
UDAF樣本
from odps.udf import annotate
from odps.udf import BaseUDAF
@annotate('bigint,*->string')
class MultiColSum(BaseUDAF):
def new_buffer(self):
return [0]
def iterate(self, buffer, *args):
for arg in args:
buffer[0] += int(arg)
def merge(self, buffer, pbuffer):
buffer[0] += pbuffer[0]
def terminate(self, buffer):
return str(buffer[0])-- 根據輸入多個參數求和
SELECT my_multi_col_sum(a,b,c,d,e) from values (1,"2","3","4","5"), (6,"7","8","9","10") t(a,b,c,d,e);
-- 傳回值為 55