MaxCompute使用的Python 2版本為2.7。本文為您介紹如何通過Python 2語言編寫UDAF。
UDAF代碼結構
- 編碼聲明:可選。
固定聲明格式為
#coding:utf-8或# -*- coding: utf-8 -*-,二者等效。當Python 2代碼中出現中文字元時,運行程式會報錯,您需要在代碼頭部增加編碼聲明。 - 匯入模組:必選。
至少要包含
from odps.udf import annotate和from odps.udf import BaseUDAF。from odps.udf import annotate用於匯入函數簽名模組,MaxCompute才可以識別後續代碼中定義的函數簽名。from odps.udf import BaseUDAF為Python UDAF的基類,您需要通過此類在衍生類別中實現iterate、merge、terminate等方法。當UDAF代碼中需要引用檔案資源或表資源時,需要包含
from odps.distcache import get_cache_file(檔案資源)或from odps.distcache import get_cache_table(表資源)。 - 函數簽名:必選。
格式為
@annotate(<signature>),signature用於定義函數的輸入參數和傳回值的資料類型。更多函數簽名資訊,請參見函數簽名及資料類型。 - 自訂Python類(衍生類別):必選。
UDAF代碼的組織單位,定義了實現業務需求的變數及方法。您還可以在代碼中引用MaxCompute內建的第三方庫或引用檔案、表資源。更多資訊,請參見第三方庫或引用資源。
- 實現Python類的方法:必選。
Python類實現包含如下4個方法,您可以根據實際需要進行選擇。
方法定義 描述 BaseUDAF.new_buffer()返回彙總函式的中間值的buffer。 buffer必須是Marshal對象(例如LIST、DICT),並且buffer的大小不應該隨資料量遞增。在極限情況下,buffer在執行對象序列化後的大小不應該超過2 MB。BaseUDAF.iterate(buffer[, args, ...])將 args彙總到中間值buffer中。BaseUDAF.merge(buffer, pbuffer)將中間值 buffer和pbuffer合并的結果存放在buffer中。BaseUDAF.terminate(buffer)將 buffer轉換為MaxCompute SQL的基本類型。
#coding:utf-8
#匯入函數簽名模組及基類。
from odps.udf import annotate
from odps.udf import BaseUDAF
#函數簽名。
@annotate('double->double')
#自訂Python類。
class Average(BaseUDAF):
#實現Python類的方法。
def new_buffer(self):
return [0, 0]
def iterate(self, buffer, number):
if number is not None:
buffer[0] += number
buffer[1] += 1
def merge(self, buffer, pbuffer):
buffer[0] += pbuffer[0]
buffer[1] += pbuffer[1]
def terminate(self, buffer):
if buffer[1] == 0:
return 0.0
return buffer[0] / buffer[1]avg的MaxCompute UDAF的實現邏輯及計算流程如下。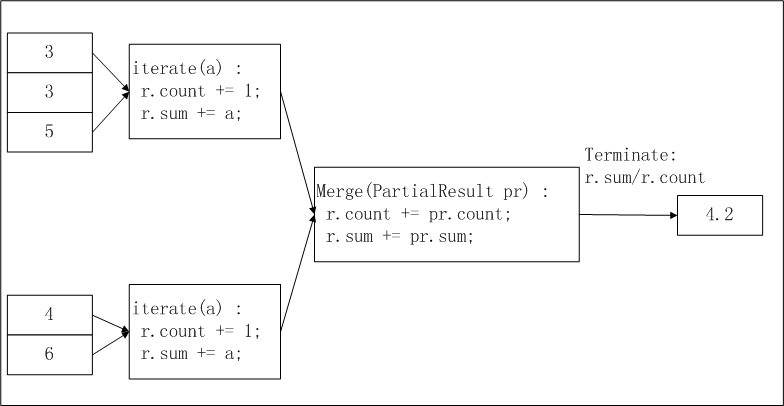
pbuffer相當於上圖中的pr,buffer相當於上圖中的r。使用限制
讀寫本地檔案。
啟動子進程。
啟動線程。
使用Socket通訊。
其他系統調用。
基於上述原因,您上傳的代碼都必須通過標準Python實現。Python標準庫中涉及到上述功能的模組或C擴充模組都會被禁止使用。具體標準庫的可用模組說明如下:
所有基於標準Python實現(不依賴擴充模組)的模組都可用。
C擴充模組中下列模組可用:
array、audioop
binascii、bisect
cmath、_codecs_cn、_codecs_hk、_codecs_iso2022、_codecs_jp、_codecs_kr、_codecs_tw、_collections、cStringIO
datetime
_functools、future_builtins、
_heapq、_hashlib
itertools
_json
_locale、_lsprof
math、_md5、_multibytecodec
operator
_random
_sha256、_sha512、_sha、_struct、strop
time
unicodedata
_weakref
cPickle
沙箱限制了您的代碼最多可向標準輸出和標準錯誤輸出寫入資料的大小為20 KB,即
sys.stdout/sys.stderr最多能寫入20 KB資料,多餘的字元會被忽略。
第三方庫
MaxCompute的Python 2運行環境中安裝了除Python標準庫外比較常用的第三方庫,作為標準庫的補充,例如Numpy。
使用第三方庫存在限制,例如禁止本地訪問、網路I/O受限,因此第三方庫中涉及到相關功能的API也被禁止使用。
函數簽名及資料類型
@annotate(<signature>)signature為字串,用於標識輸入參數和傳回值的資料類型。執行UDAF時,UDAF函數的輸入參數和傳回值類型要與函數簽名指定的類型一致。查詢語義解析階段會檢查不符合函數簽名定義的用法,檢查到類型不符時會報錯。具體格式如下。'arg_type_list -> type'arg_type_list:表示輸入參數的資料類型。輸入參數可以為多個,用英文逗號(,)分隔。支援的資料類型為BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、複雜資料類型(ARRAY、MAP、STRUCT)或複雜資料類型嵌套。arg_type_list還支援星號(*)或為空白(''):當
arg_type_list為星號(*)時,表示輸入參數為任意個數。當
arg_type_list為空白('')時,表示無輸入參數。
type:表示傳回值的資料類型。UDAF只返回一列。支援的資料類型為:BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、複雜資料類型(ARRAY、MAP、STRUCT)或複雜資料類型嵌套。
合法函數簽名樣本如下。
| 函數簽名樣本 | 說明 |
@annotate('bigint,double->string') | 輸入參數類型為BIGINT、DOUBLE,傳回值類型為STRING。 |
@annotate('*->string') | 輸入任意個參數,傳回值類型為STRING。 |
@annotate('->double') | 無輸入參數,傳回值類型為DOUBLE。 |
@annotate('array<bigint>->struct<x:string, y:int>') | 輸入參數類型為ARRAY<BIGINT>,傳回值類型為STRUCT<x:STRING, y:INT>。 |
為確保編寫Python UDAF過程中使用的資料類型與MaxCompute支援的資料類型保持一致,您需要關注二者間的資料類型映射關係。具體映射關係如下。
MaxCompute SQL Type | Python 2 Type |
BIGINT | INT |
STRING | STR |
DOUBLE | FLOAT |
BOOLEAN | BOOL |
DATETIME | INT |
FLOAT | FLOAT |
CHAR | STR |
VARCHAR | STR |
BINARY | BYTEARRAY |
DATE | INT |
DECIMAL | DECIMAL.DECIMAL |
ARRAY | LIST |
MAP | DICT |
STRUCT | COLLECTIONS.NAMEDTUPLE |
DATETIME類型對應的Python類型是INT,值為Epoch UTC Time起至今的毫秒數。您可以通過Python標準庫中的DATETIME模組處理日期時間類型。
odps.udf.int(value,[silent=True])增加了參數silent。當silent為True時,如果value無法轉為INT,則會返回None(不會返回異常)。NULL值對應Python的None。
引用資源
Python UDAF可以通過odps.distcache模組引用資源,支援引用檔案資源和表資源。
odps.distcache.get_cache_file(resource_name):返回指定檔案資源的內容。resource_name為STRING類型,對應當前MaxCompute專案中已存在的檔案資源名。如果檔案資源名非法或者沒有相應的檔案資源,會返回異常。說明 使用UDAF訪問資源,在建立UDAF時需要聲明引用的資源,否則會報錯。- 傳回值為File-like對象。在使用完此對象後,您需要調用
close方法釋放開啟的資源檔。
odps.distcache.get_cache_table(resource_name):返回指定表資源的內容。resource_name支援STRING類型,對應當前MaxCompute專案中已存在的表資源名。如果表資源名非法或者沒有相應的表資源,會返回異常。- 傳回值為GENERATOR類型,調用者以遍曆方式擷取表的內容,每次遍曆可得到以數組形式存在的表中的一條記錄。
具體使用方法請參見引用資源(Python UDF 2)和引用資源(Python UDTF 2)。
使用說明
在歸屬MaxCompute專案中使用自訂函數:使用方法與內建函數類似,您可以參照內建函數的使用方法使用自訂函數。
跨專案使用自訂函數:即在專案A中使用專案B的自訂函數,跨專案分享語句樣本:
select B:udf_in_other_project(arg0, arg1) as res from table_t;。更多跨專案分享資訊,請參見基於Package跨專案訪問資源。
使用MaxCompute Studio完整開發及調用Python 2 UDAF的操作,請參見開發Python UDF。