本文為您介紹如何通過Java語言編寫UDAF。
UDAF代碼結構
您可以通過IntelliJ IDEA(Maven)或MaxCompute Studio工具使用Java語言編寫UDAF代碼,代碼中需要包含如下資訊:
Java包(Package):可選。
您可以將定義的Java類打包,為後續尋找和使用類提供方便。
繼承UDAF類:必選。
必須攜帶的UDAF類為
com.aliyun.odps.udf.Aggregator和com.aliyun.odps.udf.annotation.Resolve(對應@Resolve註解)。com.aliyun.odps.udf.UDFException(可選,對應實現Java類初始化和結束的方法)。當您需要使用其他UDAF類或者需要用到複雜資料類型時,請根據MaxCompute UDF概述添加需要的類。@Resolve註解:必選。格式為
@Resolve(<signature>)。signature為函數簽名,用於定義函數的輸入參數和傳回值的資料類型。UDAF無法通過反射分析擷取函數簽名,只能通過@Resolve註解方式擷取函數簽名,例如@Resolve("smallint->varchar(10)")。更多@Resolve註解資訊,請參見@Resolve註解。自訂Java類:必選。
UDAF代碼的組織單位,定義了實現業務需求的變數及方法。
實現Java類的方法:必選。
實現Java類需要繼承
com.aliyun.odps.udf.Aggregator類並實現如下方法。import com.aliyun.odps.udf.ContextFunction; import com.aliyun.odps.udf.ExecutionContext; import com.aliyun.odps.udf.UDFException; public abstract class Aggregator implements ContextFunction { //初始化方法。 @Override public void setup(ExecutionContext ctx) throws UDFException { } //結束方法。 @Override public void close() throws UDFException { } //建立彙總Buffer。 abstract public Writable newBuffer(); //iterate方法。 //buffer為彙總buffer,是指一個階段性的摘要資料,即在不同的Map任務中,group by後得出的資料(可理解為一個集合),每行執行一次。 //Writable[]表示一行資料,在代碼中指代傳入的列。例如writable[0]表示第一列,writable[1]表示第二列。 //args為SQL中調用UDAF時指定的參數,不能為NULL,但是args裡面的元素可以為NULL,代表對應的輸入資料是NULL。 abstract public void iterate(Writable buffer, Writable[] args) throws UDFException; //terminate方法。 abstract public Writable terminate(Writable buffer) throws UDFException; //merge方法。 abstract public void merge(Writable buffer, Writable partial) throws UDFException; }其中:
iterate、merge和terminate是最重要的三個方法,UDAF的主要邏輯依賴於這三個方法的實現。此外,還需要您實現自訂的Writable buffer。Writable buffer將記憶體中的對象轉換成位元組序列(或其他資料轉送協議)以便於儲存到磁碟(持久化)和網路傳輸。因為MaxCompute使用分散式運算的方式來處理彙總函式,因此需要知道如何序列化和還原序列化資料,以便於資料在不同的裝置之間進行傳輸。
編寫Java UDAF時可以使用Java Type或Java Writable Type,MaxCompute專案支援處理的資料類型與Java資料類型的詳細映射關係,請參見資料類型。
UDAF程式碼範例如下。
//將定義的Java類組織在org.alidata.odps.udaf.examples包中。
package org.alidata.odps.udaf.examples;
//繼承UDAF類。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import com.aliyun.odps.io.DoubleWritable;
import com.aliyun.odps.io.Writable;
import com.aliyun.odps.udf.Aggregator;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.annotation.Resolve;
//自訂Java類。
//@Resolve註解。
@Resolve("double->double")
public class AggrAvg extends Aggregator {
//實現Java類的方法。
private static class AvgBuffer implements Writable {
private double sum = 0;
private long count = 0;
@Override
public void write(DataOutput out) throws IOException {
out.writeDouble(sum);
out.writeLong(count);
}
@Override
public void readFields(DataInput in) throws IOException {
sum = in.readDouble();
count = in.readLong();
}
}
private DoubleWritable ret = new DoubleWritable();
@Override
public Writable newBuffer() {
return new AvgBuffer();
}
@Override
public void iterate(Writable buffer, Writable[] args) throws UDFException {
DoubleWritable arg = (DoubleWritable) args[0];
AvgBuffer buf = (AvgBuffer) buffer;
if (arg != null) {
buf.count += 1;
buf.sum += arg.get();
}
}
@Override
public Writable terminate(Writable buffer) throws UDFException {
AvgBuffer buf = (AvgBuffer) buffer;
if (buf.count == 0) {
ret.set(0);
} else {
ret.set(buf.sum / buf.count);
}
return ret;
}
@Override
public void merge(Writable buffer, Writable partial) throws UDFException {
AvgBuffer buf = (AvgBuffer) buffer;
AvgBuffer p = (AvgBuffer) partial;
buf.sum += p.sum;
buf.count += p.count;
}
}上述UDAF程式碼範例中,iterate和merge方法裡的buffer為複用buffer,用於將輸入的各行資料通過使用者自訂實現的方式彙總到該buffer中。
使用限制
訪問外網
MaxCompute預設不支援通過自訂函數訪問外網。如果您需要通過自訂函數訪問外網,請根據業務情況填寫並提交網路連接申請表單,MaxCompute支援人員團隊會及時聯絡您完成網路開通操作。表單填寫指導,請參見網路開通流程。
訪問VPC網路
MaxCompute預設不支援通過UDF訪問VPC網路。如果您的UDF涉及訪問VPC網路中的資源時,需要先建立MaxCompute與目標VPC網路間的網路連接,才可以直接通過UDF訪問VPC網路中的資源,操作詳情請參見通過UDF訪問VPC網路資源。
讀取表資料
目前版本不支援使用UDF/UDAF/UDTF讀取以下情境的表資料:
做過表結構修改(Schema Evolution)的表資料。
包含複雜資料類型的表資料。
包含JSON資料類型的表資料。
Transactional表的表資料。
注意事項
在編寫Java UDAF時,您需要注意:
不同UDAF JAR包中不建議存在類名相同但實現邏輯不一樣的類。例如UDAF1、UDAF2分別對應資源JAR包udaf1.jar、udaf2.jar,兩個JAR包裡都包含名稱為
com.aliyun.UserFunction.class的類但實現邏輯不一樣,當同一條SQL語句中同時調用UDAF1和UDAF2時,MaxCompute會隨機載入其中一個類,此時會導致UDAF執行結果不符合預期甚至編譯失敗。Java UDAF中輸入或傳回值的資料類型是對象,資料類型首字母必須大寫,例如String。
SQL中的NULL值通過Java中的NULL表示。Java Primitive Type無法表示SQL中的NULL值,不允許使用。
@Resolve註解
@Resolve註解格式如下。
@Resolve(<signature>)signature為字串,用於標識輸入參數和傳回值的資料類型。執行UDAF時,UDAF函數的輸入參數和傳回值類型要與函數簽名指定的類型一致。查詢語義解析階段會檢查不符合函數簽名定義的用法,檢查到類型不符時會報錯。具體格式如下。
'arg_type_list -> type'其中:
arg_type_list:表示輸入參數的資料類型。輸入參數可以為多個,用英文逗號(,)分隔。支援的資料類型為BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、複雜資料類型(ARRAY、MAP、STRUCT)或複雜資料類型嵌套。arg_type_list還支援星號(*)或為空白(''):當
arg_type_list為星號(*)時,表示輸入參數為任意個數。當
arg_type_list為空白('')時,表示無輸入參數。
type:表示傳回值的資料類型。UDAF只返回一列。支援的資料類型為:BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、複雜資料類型(ARRAY、MAP、STRUCT)或複雜資料類型嵌套。
在編寫UDAF代碼過程中,您可以根據MaxCompute專案的資料類型版本選取合適的資料類型,更多資料類型版本及各版本支援的資料類型資訊,請參見資料類型版本說明。
合法@Resolve註解樣本如下。
@Resolve註解樣本 | 說明 |
| 輸入參數類型為BIGINT、DOUBLE,傳回值類型為STRING。 |
| 輸入任意個參數,傳回值類型為STRING。 |
| 無輸入參數,傳回值類型為DOUBLE。 |
| 輸入參數類型為ARRAY<BIGINT>,傳回值類型為STRUCT<x:STRING, y:INT>。 |
資料類型
在MaxCompute中不同資料類型版本支援的資料類型不同。從MaxCompute 2.0版本開始,擴充了更多的新資料類型,同時還支援ARRAY、MAP、STRUCT等複雜類型。更多MaxCompute資料類型版本資訊,請參見資料類型版本說明。
為確保編寫Java UDAF過程中使用的資料類型與MaxCompute支援的資料類型保持一致,您需要關注二者間的資料類型映射關係。具體映射關係如下。
MaxCompute Type | Java Type | Java Writable Type |
TINYINT | java.lang.Byte | ByteWritable |
SMALLINT | java.lang.Short | ShortWritable |
INT | java.lang.Integer | IntWritable |
BIGINT | java.lang.Long | LongWritable |
FLOAT | java.lang.Float | FloatWritable |
DOUBLE | java.lang.Double | DoubleWritable |
DECIMAL | java.math.BigDecimal | BigDecimalWritable |
BOOLEAN | java.lang.Boolean | BooleanWritable |
STRING | java.lang.String | Text |
VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
BINARY | com.aliyun.odps.data.Binary | BytesWritable |
DATE | java.sql.Date | DateWritable |
DATETIME | java.util.Date | DatetimeWritable |
TIMESTAMP | java.sql.Timestamp | TimestampWritable |
INTERVAL_YEAR_MONTH | 不涉及 | IntervalYearMonthWritable |
INTERVAL_DAY_TIME | 不涉及 | IntervalDayTimeWritable |
ARRAY | java.util.List | 不涉及 |
MAP | java.util.Map | 不涉及 |
STRUCT | com.aliyun.odps.data.Struct | 不涉及 |
當MaxCompute專案採用MaxCompute 2.0資料類型版本時,UDAF的輸入或傳回值才可以使用Java Writable Type。
使用說明
按照開發流程,完成Java UDAF開發後,您即可通過MaxCompute SQL調用Java UDAF。調用方法如下:
在歸屬MaxCompute專案中使用自訂函數:使用方法與內建函數類似,您可以參照內建函數的使用方法使用自訂函數。
跨專案使用自訂函數:即在專案A中使用專案B的自訂函數,跨專案分享語句樣本:
select B:udf_in_other_project(arg0, arg1) as res from table_t;。更多跨專案分享資訊,請參見基於Package跨專案訪問資源。
使用MaxCompute Studio完整開發及調用Java UDAF的操作,請參見使用樣本。
使用樣本
以通過MaxCompute Studio開發計算平均值的UDAF函數AggrAvg為例,實現邏輯如下。
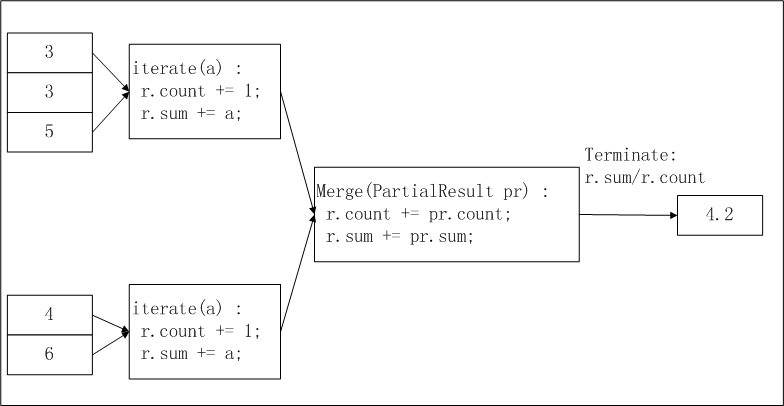
輸入資料分區:MaxCompute會按照MapReduce處理流程對輸入資料按照一定的大小進行分區,每片的大小適合一個Worker在適當的時間內完成。
分區大小需要您通過
odps.stage.mapper.split.size參數進行配置。分區邏輯請參見MapReduce流程說明。計算平均值第一階段:每個Worker統計分區內資料的個數及匯總值。您可以將每個分區內的資料個數及匯總值視為一個中間結果。
計算平均值第二階段:匯總第一階段中每個分區內的資訊。
最終輸出:
r.sum/r.count即是所有輸入資料的平均值。
開發並調用Java UDAF的操作步驟如下:
準備工作。
使用MaxCompute Studio開發調試UDF時,您需要先安裝MaxCompute Studio並串連MaxCompute專案,做好UDF開發前準備工作。操作詳情請參見:
編寫UDAF代碼。
在Project地區,按右鍵Module的源碼目錄(即),選擇。
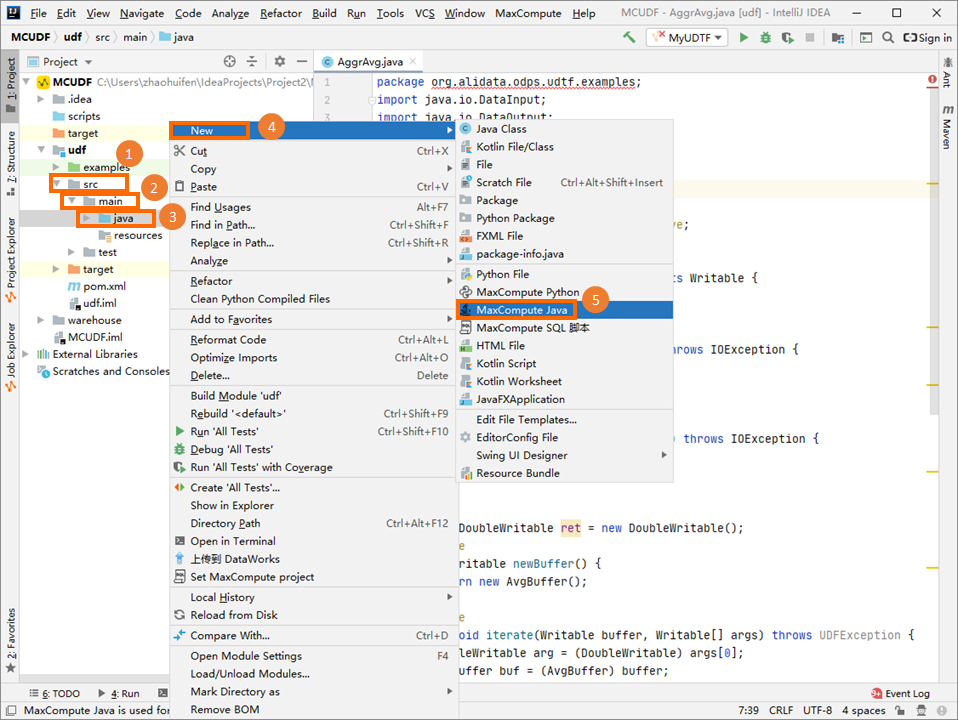
在Create new MaxCompute java class對話方塊,單擊UDAF並填寫Name後,按Enter鍵。例如Java Class名稱為AggrAvg。
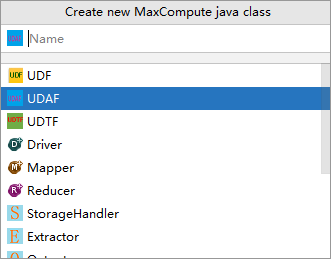
Name為建立的MaxCompute Java Class名稱。如果還沒有建立Package,在此處填寫packagename.classname,會自動產生Package。
在代碼編寫地區寫入如下代碼。
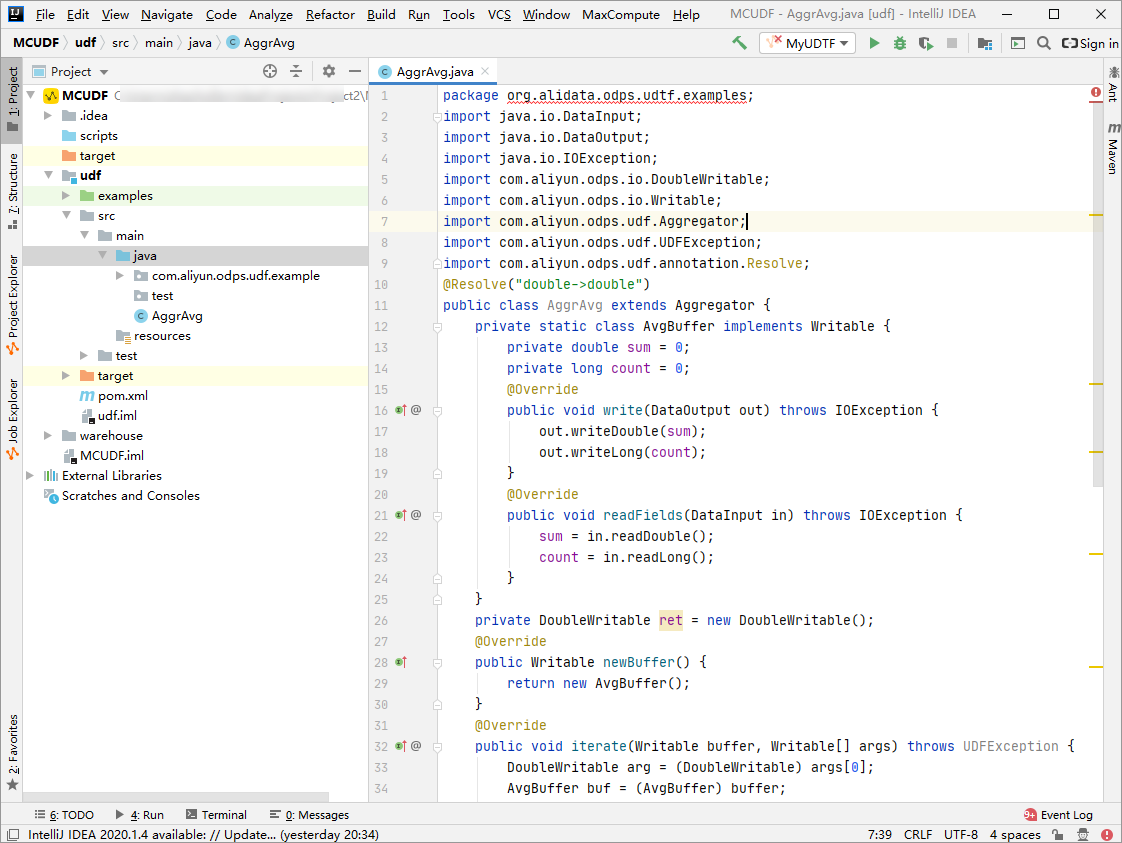 UDAF程式碼範例如下。
UDAF程式碼範例如下。import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import com.aliyun.odps.io.DoubleWritable; import com.aliyun.odps.io.Writable; import com.aliyun.odps.udf.Aggregator; import com.aliyun.odps.udf.UDFException; import com.aliyun.odps.udf.annotation.Resolve; @Resolve("double->double") public class AggrAvg extends Aggregator { private static class AvgBuffer implements Writable { private double sum = 0; private long count = 0; @Override public void write(DataOutput out) throws IOException { out.writeDouble(sum); out.writeLong(count); } @Override public void readFields(DataInput in) throws IOException { sum = in.readDouble(); count = in.readLong(); } } private DoubleWritable ret = new DoubleWritable(); @Override public Writable newBuffer() { return new AvgBuffer(); } @Override public void iterate(Writable buffer, Writable[] args) throws UDFException { DoubleWritable arg = (DoubleWritable) args[0]; AvgBuffer buf = (AvgBuffer) buffer; if (arg != null) { buf.count += 1; buf.sum += arg.get(); } } @Override public Writable terminate(Writable buffer) throws UDFException { AvgBuffer buf = (AvgBuffer) buffer; if (buf.count == 0) { ret.set(0); } else { ret.set(buf.sum / buf.count); } return ret; } @Override public void merge(Writable buffer, Writable partial) throws UDFException { AvgBuffer buf = (AvgBuffer) buffer; AvgBuffer p = (AvgBuffer) partial; buf.sum += p.sum; buf.count += p.count; } }
在本地運行調試UDAF,確保代碼可以運行成功。
更多調試操作,請參見通過本地運行調試UDF。
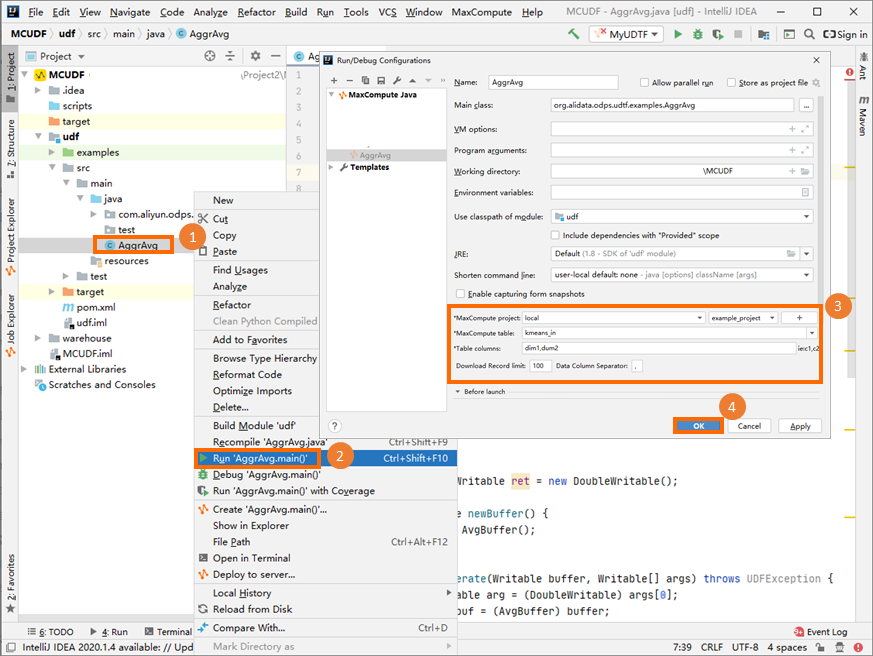 說明
說明運行參數可參照圖示資料填寫。
將建立的UDAF打包為JAR包,上傳至MaxCompute專案並註冊函數。例如函數名稱為
user_udaf。更多打包操作,請參見操作步驟。
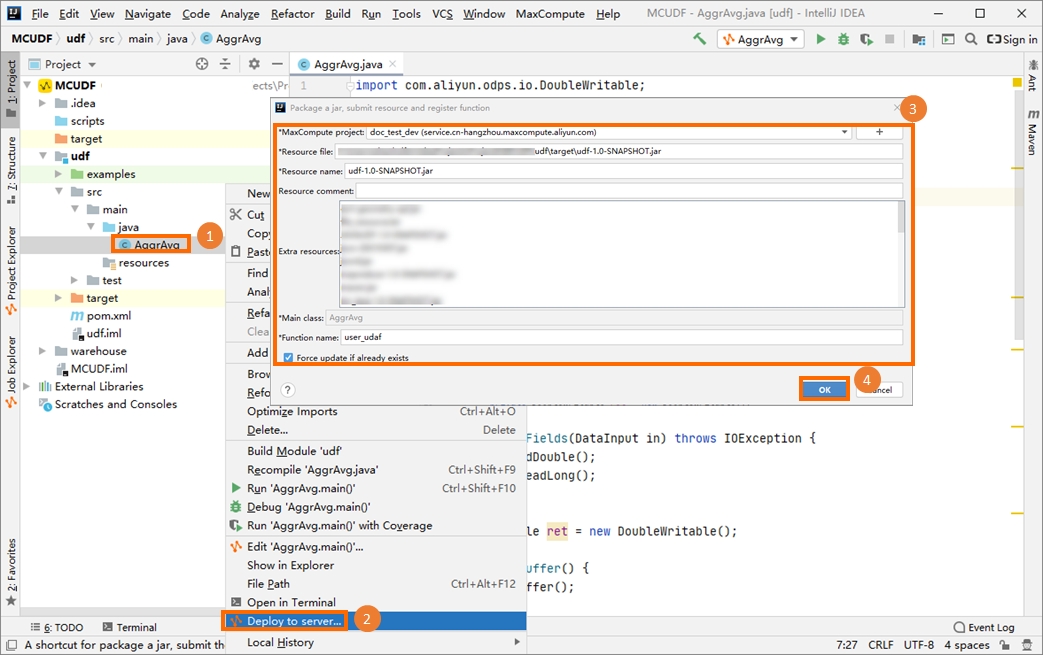
在MaxCompute Studio的左側導覽列,單擊Project Explorer,在目標MaxCompute專案上單擊右鍵,啟動MaxCompute用戶端,並執行SQL命令調用新建立的UDAF。
假設待查詢目標表my_table的資料結構如下。
+------------+------------+ | col0 | col1 | +------------+------------+ | 1.2 | 2.0 | | 1.6 | 2.1 | +------------+------------+執行如下SQL命令調用UDAF。
select user_udaf(col0) as c0 from my_table;返回結果如下。
+----+ | c0 | +----+ | 1.4| +----+