MaxCompute不提供Graph開發外掛程式,您可以基於Eclipse開發MaxCompute Graph程式。
開發流程如下:
- 編寫Graph代碼,使用本地調試進行基本的測試。
- 進行叢集調試,驗證結果。
開發樣本
本節以SSSP演算法為例,為您介紹如何使用Eclipse開發和調試Graph程式。
操作步驟:
- 建立Java工程,工程名為graph_examples。
- 將MaxCompute用戶端lib目錄下的Jar包加到Eclipse工程的Java Build Path中。
- 開發MaxCompute Graph程式。
實際開發過程中,通常會先複製一個例子(例如單源最短距離),然後進行修改。在本樣本中,僅修改了Package的路徑為package com.aliyun.odps.graph.example。
- 編譯打包。
在Eclipse環境中,按右鍵原始碼目錄(圖中的src目錄),產生Jar包,選擇目標Jar包的儲存路徑,例如D:\\odps\\clt\\odps-graph-example-sssp.jar。
- 使用MaxCompute用戶端運行SSSP,詳情請參見運行Graph。
本地調試
MaxCompute Graph支援本地偵錯模式,您可以使用Eclipse進行斷點調試。
操作步驟:
- 下載一個odps-graph-local的Maven包。
- 選擇Eclipse工程,按右鍵Graph作業主程式(包含
main函數)檔案,配置其運行參數()。 - 在Arguments頁簽中,設定Program arguments參數為1 sssp_in sssp_out,作為主程式的輸入參數。
- 在Arguments頁簽中,設定VM arguments參數如下。
-Dodps.runner.mode=local -Dodps.project.name=<project.name> -Dodps.end.point=<end.point> -Dodps.access.id=<access.id> -Dodps.access.key=<access.key>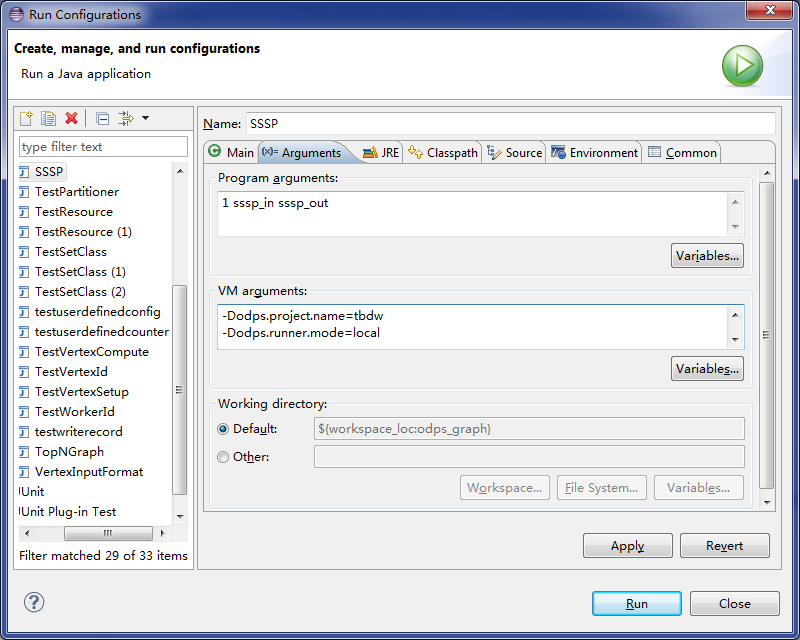
- 對於本地模式(即不指定odps.end.point參數),需要在warehouse建立sssp_in、sssp_out表,為輸入表sssp_in添加資料,輸入資料如下所示。
1,"2:2,3:1,4:4" 2,"1:2,3:2,4:1" 3,"1:1,2:2,5:1" 4,"1:4,2:1,5:1" 5,"3:1,4:1"關於warehouse的介紹請參見本地運行。
- 單擊Run,即可本地跑SSSP。
說明 參數設定可參見MaxCompute用戶端中conf/odps_config.ini的設定,上述為幾個常用參數,其他參數說明如下:
- odps.runner.mode:取值為local,本地調試功能必須指定。
- odps.project.name:指定當前Project,必須指定。
- odps.end.point:指定當前MaxCompute服務的地址,可以不指定。如果不指定,只從warehouse讀取表或資源的meta和資料,不存在則拋異常。如果指定,會先從warehouse讀取,不存在時會遠端連線MaxCompute讀取。
- odps.access.id:串連MaxCompute服務的AccessKey ID,只在指定odps.end.point時有效。
- odps.access.key:串連MaxCompute服務的AccessKey Secret,只在指定odps.end.point時有效。
- odps.cache.resources:指定使用的資源清單,效果與Jar命令的
-resources相同。 - odps.local.warehouse:本地warehouse路徑,不指定時預設為./warehouse。
在Eclipse中本地運行SSSP的調試輸出資訊,如下所示。Counters: 3 com.aliyun.odps.graph.local.COUNTER TASK_INPUT_BYTE=211 TASK_INPUT_RECORD=5 TASK_OUTPUT_BYTE=161 TASK_OUTPUT_RECORD=5 graph task finish
本地作業臨時目錄
每運行一次本地調試,都會在Eclipse工程目錄下建立一個臨時目錄。
本地啟動並執行Graph作業,臨時目錄包括以下幾個目錄和檔案:
- counters:存放作業啟動並執行一些計數資訊。
- inputs:存放作業的輸入資料,優先取自本地的warehouse,如果本地沒有,會通過MaxCompute SDK從服務端讀取(如果設定了odps.end.point),預設一個input唯讀10條資料,可以通過
-Dodps.mapred.local.record.limit參數進行修改,但是也不能超過1萬條記錄。 - outputs:存放作業的輸出資料,如果本地warehouse中存在輸出表,outputs中的結果資料在作業執行完後會覆蓋本地warehouse中對應的表。
- resources:存放作業使用的資源,與輸入類似,優先取自本地的warehouse,如果本地沒有,會通過MaxCompute SDK從服務端讀取(如果設定了odps.end.point)。
- job.xml:作業配置。
- superstep:存放每一輪迭代的持久化資訊。
說明 如果需要本地調試時輸出詳細日誌,需要在src目錄下放一個log4j的設定檔log4j.properties_odps_graph_cluster_debug。
叢集調試
通過本地的調試後,您即可提交作業到叢集進行測試。
操作步驟如下:
- 配置MaxCompute用戶端。
- 使用
add jar /path/work.jar -f;命令更新Jar包。 - 使用Jar命令運行作業,查看作業記錄和結果資料。
說明 叢集運行Graph的詳細介紹請參見編寫Graph。
效能調優
對效能有所影響的Graph Job配置項如下:
setSplitSize(long):輸入表切分大小,單位MB,大於0,預設64。setNumWorkers(int):設定作業Worker數量,範圍為[1,1000],預設值為1。Worker數由作業輸入位元組數和splitSize決定。setWorkerCPU(int):Map CPU資源,100為1CPU核,[50,800]之間,預設值為200。setWorkerMemory(int):Map記憶體資源,單位MB,範圍為[256,12288],預設值為4096。setMaxIteration(int):設定最大迭代次數,預設為-1,小於或等於0時表示最大迭代次數不作為作業終止條件。setJobPriority(int):設定作業優先順序,範圍為[0,9],預設值為9,數值越大優先順序越小。
通常情況下的調優建議:
- 可以考慮使用
setNumWorkers方法增加Worker數目。 - 可以考慮使用
setSplitSize方法減少切分大小,提高作業載入資料速度。 - 加大Worker的CPU或記憶體。
- 設定最大迭代次數,如果有些應用結果精度要求不高,可以考慮減少迭代次數,儘快結束。
介面
setNumWorkers與setSplitSize配合使用,可以提高資料的載入速度。假設setNumWorkers為workerNum,setSplitSize為splitSize,總輸入位元組數為inputSize,則輸入被切分後的塊數splitNum=inputSize/splitSize。workerNum和splitNum之間的關係如下:
- 情況一:
splitNum=workerNum,每個Worker負責載入1個Split。 - 情況二:
splitNum>workerNum,每個Worker負責載入1個或多個Split。 - 情況三:
splitNum<workerNum,每個Worker負責載入0個或1一個Split。
因此,應調節workerNum和splitSize,在滿足前兩種情況時,資料載入比較快。迭代階段只需調節workerNum。如果設定runtime partitioning為False,則建議直接使用setSplitSize控制Worker數量,或者保證滿足前兩種情況。當出現第三種情況時,部分Worker上的切片會為0,可以在Jar命令前使用set odps.graph.split.size=<m>; set odps.graph.worker.num=<n>; 與setNumWorkers,和setSplitSize等效。
另外一種常見的效能問題為資料扭曲,反應到Counters就是某些Worker處理的點或邊數量遠超過其他Worker。資料扭曲的原因通常是某些Key對應的點、邊,或者訊息的數量遠超過其他Key,這些Key被分到少量的Worker處理,導致這些Worker已耗用時間較長。解決方案:
- 嘗試Combiner,將這些Key對應點的訊息進行本地彙總,減少訊息發生。
開發人員可定義Combiner以減少儲存訊息的記憶體和網路資料流量,縮短作業的執行時間。
- 改進商務邏輯。
資料量大時,讀取磁碟中的資料可能耗費一部分處理時間。減少需要讀取的資料位元組數可以提高總體的輸送量,提高作業效能。您可通過以下方法進行改進:
- 減少輸入資料量:對某些決策性質的應用,處理資料採樣後子集所得到的結果只可能影響結果的精度,而並不會影響整體的準確性,因此可以考慮先對資料進行特定採樣後再匯入輸入表中進行處理。
- 避免讀取用不到的欄位:MaxCompute Graph架構的TableInfo類支援讀取指定的列(以列名數組方式傳入),而非整個表或表分區,這樣也可以減少輸入的資料量,提高作業效能。
內建Jar包
以下Jar包會預設載入到運行Graph程式的JVM中,您不必上傳這些資源,也不必在命令列的
-libjars帶上這些Jar包。
- commons-codec-1.3.jar
- commons-io-2.0.1.jar
- commons-lang-2.5.jar
- commons-logging-1.0.4.jar
- commons-logging-api-1.0.4.jar
- guava-14.0.jar
- json.jar
- log4j-1.2.15.jar
- slf4j-api-1.4.3.jar
- slf4j-log4j12-1.4.3.jar
- xmlenc-0.52.jar
說明 在JVM的Classpath中,上述內建Jar包會位於您的Jar包之前,可能產生版本衝突。例如您的程式中使用了commons-codec-1.5.jar某個類的函數,但是這個函數不在commons-codec-1.3.jar中,這時如果1.3版本無法實現您的需求,則只能等待MaxCompute升級新版本。