基於滿足物化視圖情境的資料建立物化視圖,支援分區和聚簇情境。
背景資訊
視圖是一種虛擬表,任何對視圖的查詢,都會轉換為視圖SQL語句的查詢。而物化視圖是一種特殊的物理表,物化視圖會儲存實際的資料,佔用儲存資源。更多物化視圖計費資訊,請參見計費規則。
物化視圖適用於如下情境:
模式固定、且執行頻次高的查詢。
查詢包含非常耗時的操作,比如彙總、串連操作等。
查詢僅涉及表中的很小部分資料。
物化視圖與傳統查詢的對比如下。
對比項 | 傳統查詢方式 | 物化視圖查詢方式 |
查詢語句 | 直接使用SQL語句查詢資料。 | 您需要建立物化視圖,然後基於物化視圖查詢資料。 建立物化視圖語句如下: 基於建立的物化視圖查詢資料: 如果物化視圖開啟了查詢改寫功能,使用如下SQL語句查詢資料時會直接從物化視圖中查詢資料: |
查詢特點 | 查詢涉及讀表、JOIN、過濾(WHERE)操作。當源表資料量很大時,查詢速度會很慢。操作複雜度較高,運行效率低。 | 查詢涉及讀表、過濾操作。不涉及JOIN操作。MaxCompute會自動匹配到最優物化視圖,並直接從物化視圖中讀取資料,從而大大提高查詢效率。 |
計費規則
物化視圖費用包含如下兩部分:
儲存費用
物化視圖會佔用實體儲存體空間,會產生儲存費用,隨用隨付。更多計費資訊,請參見儲存費用(隨用隨付)。
計算費用
建立、更新、查詢物化視圖及查詢改寫(物化視圖有效)過程中涉及到查詢資料,會消耗計算資源產生計算費用。
當MaxCompute專案的規格類型為訂用帳戶時,不單獨收費。
當MaxCompute專案的規格類型為隨用隨付時,按照SQL複雜度及輸入資料量計算費用。更多計費資訊,請參見SQL標準計費。您需要注意如下資訊:
更新物化視圖執行的SQL與建立物化視圖執行的SQL相同,如果該物化視圖所在專案綁定的是預付費(訂用帳戶)計算資源群組,那麼會使用已經購買的預付費資源,不會有額外費用;如果綁定的是後付費資源群組,費用取決於執行SQL時輸入的資料量和複雜度。同時重新整理物化視圖後會按照實際儲存大小收取儲存費用。
當物化視圖處於生效狀態時查詢改寫會從物化視圖中讀取資料,查詢語句的輸入資料量(從物化視圖讀取部分)與物化視圖相關,與物化視圖源表無關。當物化視圖處於失效狀態時不支援查詢改寫,查詢語句會直接查詢源表,查詢語句的輸入資料量與源表相關。更多查詢物化檢視狀態資訊,請參見查詢物化檢視狀態。
由於多表關聯產生物化視圖會產生資料膨脹等原因,從物化視圖讀取的資料量不一定絕對小於源表,MaxCompute不能保證讀取物化視圖一定比讀取源表節省費用。
使用限制
物化視圖的使用限制如下:
不支援視窗函數。
不支援UDTF函數。
預設不支援非確定性函數(例如UDF、UDAF等)。當您的業務情境必須要使用非確定性函數時,請在Session層級設定屬性
set odps.sql.materialized.view.support.nondeterministic.function=true;。
注意事項
當查詢語句執行失敗時,物化視圖也會建立失敗。
物化視圖分區列必須來源於某張源表,其順序和列數目必須和源表一樣,列名稱可以不一樣。
列注釋需要指定所有列,包含分區列。如果只指定部分列,會報錯。
可以同時指定分區和聚簇,此時每個分區中的資料都有指定的聚簇屬性。
當查詢語句中包含不支援的運算元時會報錯。物化視圖支援的運算元列表,請參見基於物化視圖執行查詢改寫操作。
MaxCompute預設不支援使用非確定性函數(例如UDF、UDAF等)建立物化視圖。當您的業務情境必須要使用非確定性函數時,請在Session層級設定屬性
set odps.sql.materialized.view.support.nondeterministic.function=true;。物化視圖支援產生空分區,原始表分區為空白的時候,重新整理物化視圖,自動產生空分區。
命令格式
CREATE MATERIALIZED VIEW [IF NOT EXISTS][project_name.]<mv_name>
[LIFECYCLE <days>] --指定生命週期
[BUILD DEFERRED] -- 指定是在建立時只產生表結構,不產生資料
[(<col_name> [COMMENT <col_comment>],...)] --列注釋
[DISABLE REWRITE] --指定是否用於改寫
[COMMENT 'table comment'] --表注釋
[PARTITIONED BY (<col_name> [, <col_name>, ...]) --建立物化視圖表為分區表
[CLUSTERED BY|RANGE CLUSTERED BY (<col_name> [, <col_name>, ...])
[SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])]
INTO <number_of_buckets> BUCKETS] --用於建立聚簇表時設定表的Shuffle和Sort屬性
[REFRESH EVERY <num> MINUTES/HOURS/DAYS]
[TBLPROPERTIES("compressionstrategy"="normal/high/extreme", --指定表資料存放區壓縮策略
"enable_auto_substitute"="true", --指定當分區不存在時是否轉化視圖來查詢
"enable_auto_refresh"="true", --指定是否開啟自動重新整理
"refresh_interval_minutes"="120", --指定重新整理時間間隔
"only_refresh_max_pt"="true" --針對分區物化視圖,只自動重新整理源表最新分區
)]
AS <select_statement>;參數說明
參數 | 是否必填 | 說明 |
IF NOT EXISTS | 否 | 如果沒有指定IF NOT EXISTS且物化視圖已經存在會返回報錯。 |
project_name | 否 | 物化視圖所屬目標MaxCompute專案名稱。不填寫時表示當前所在MaxCompute專案。您可以登入MaxCompute控制台,左上方切換地區後,即可在專案管理頁面查看到具體的MaxCompute專案名稱。 |
mv_name | 是 | 建立物化視圖的名稱。 |
days | 否 | 指定物化視圖的生命週期,單位為天。取值範圍為1~37231。 |
BUILD DEFERRED | 否 | 如果加上這個關鍵字代表建立物化視圖時,只產生表結構,不重新整理資料。 |
col_name | 否 | 指定物化視圖的列名稱。 |
col_comment | 否 | 指定物化視圖的列的注釋。 |
DISABLE REWRITE | 否 | 設定禁止通過物化視圖執行查詢改寫操作。不指定時表示允許通過物化視圖執行查詢改寫操作,您可以執行 |
PARTITIONED BY | 否 | 指定物化視圖分區欄位,表示建立的物化視圖表為分區表。 |
CLUSTERED BY|RANGE CLUSTERED BY | 否 | 用於建立聚簇表時設定表的Shuffle屬性。 |
SORTED BY | 否 | 用於建立聚簇表時設定表的Sort屬性。 |
REFRESH EVERY | 否 | 用於設定物化視圖定時更新間隔。單位可選擇:分鐘/小時/天。 |
number_of_buckets | 否 | 用於建立聚簇表時設定表分桶數。 |
TBLPROPERTIES | 否 |
|
select_statement | 是 | 查詢語句,詳細格式請參見SELECT文法。 |
使用樣本
建立物化視圖
建立
mf_t和mf_t1兩張表並插入資料。CREATE TABLE IF NOT EXISTS mf_t( id bigint, value bigint, name string) PARTITIONED BY (ds STRING); ALTER TABLE mf_t ADD PARTITION (ds='1'); INSERT INTO mf_t PARTITION (ds='1') VALUES (1,10,'kyle'),(2,20,'xia'); SELECT * FROM mf_t WHERE ds ='1'; -- 返回結果如下。 +------------+------------+------------+------------+ | id | value | name | ds | +------------+------------+------------+------------+ | 1 | 10 | kyle | 1 | | 2 | 20 | xia | 1 | +------------+------------+------------+------------+ CREATE TABLE IF NOT EXISTS mf_t1( id bigint, value bigint, name string) PARTITIONED BY (ds STRING); ALTER TABLE mf_t1 ADD PARTITION (ds='1'); INSERT INTO mf_t1 PARTITION (ds='1') VALUES (1,10,'kyle'),(3,20,'john'); SELECT * FROM mf_t1 WHERE ds ='1'; -- 返回結果如下。 +------------+------------+------------+------------+ | id | value | name | ds | +------------+------------+------------+------------+ | 1 | 10 | kyle | 1 | | 3 | 20 | john | 1 | +------------+------------+------------+------------+建立物化視圖。
樣本1:建立以ds為分區列的物化視圖。
CREATE MATERIALIZED VIEW mf_mv LIFECYCLE 7 ( key comment 'unique id', value comment 'input value', ds comment 'partitiion' ) PARTITIONED BY (ds) AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1'; --查詢物化視圖 SELECT * FROM mf_mv WHERE ds =1; +------------+------------+------------+ | key | value | ds | +------------+------------+------------+ | 1 | 10 | 1 | +------------+------------+------------+樣本2:建立帶有聚簇屬性的非分區物化視圖。
CREATE MATERIALIZED VIEW mf_mv2 LIFECYCLE 7 CLUSTERED BY (key) SORTED BY (value) INTO 1024 buckets AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1';樣本3:建立帶有聚簇屬性的分區物化視圖。
CREATE MATERIALIZED VIEW mf_mv3 LIFECYCLE 7 PARTITIONED BY (ds) CLUSTERED BY (key) SORTED BY (value) INTO 1024 buckets AS SELECT t1.id AS key, t1.value AS value, t1.ds AS ds FROM mf_t AS t1 JOIN mf_t1 AS t2 ON t1.id = t2.id AND t1.ds=t2.ds AND t1.ds='1';
改寫物化視圖
情境:假設有一張頁面訪問表visit_records,記錄了各個使用者訪問的頁面ID、使用者ID、訪問時間。使用者經常要對不同頁面的訪問量進行查詢分析。visit_records的結構如下。
+------------------------------------------------------------------------------------+
| Field | Type | Label | Comment |
+------------------------------------------------------------------------------------+
| page_id | string | | |
| user_id | string | | |
| visit_time | string | | |
+------------------------------------------------------------------------------------+此時,可以給visit_records表建立一個以頁面ID分組,統計各個頁面訪問次數的物化視圖,並基於物化視圖執行後續查詢操作:
執行如下語句建立物化視圖。
CREATE MATERIALIZED VIEW count_mv AS SELECT page_id, count(*) FROM visit_records GROUP BY page_id;執行查詢語句如下。
SET odps.sql.materialized.view.enable.auto.rewriting=true; SELECT page_id, count(*) FROM visit_records GROUP BY page_id;執行該查詢語句時,MaxCompute能自動匹配到物化視圖count_mv,從count_mv中讀取彙總好的資料。
執行如下命令檢驗查詢語句是否匹配到物化視圖。
EXPLAIN SELECT page_id, count(*) FROM visit_records GROUP BY page_id;返回結果如下。
job0 is root job In Job job0: root Tasks: M1 In Task M1: Data source: doc_test_dev.count_mv TS: doc_test_dev.count_mv FS: output: Screen schema: page_id (string) _c1 (bigint) OK從返回結果中的Data source可查看到當前查詢讀取的表是doc_test_dev專案下的count_mv,說明物化視圖有效,查詢改寫成功。
基於物化視圖執行查詢改寫操作
物化視圖最重要的作用就是對查詢語句進行查詢改寫,如果期望查詢語句能利用物化視圖進行查詢改寫,則需要在查詢語句前添加set odps.sql.materialized.view.enable.auto.rewriting=true;配置。當物化視圖處於失效狀態時無法用於查詢改寫,查詢語句會直接查詢源表而無法獲得加速作用。
預設每個MaxCompute專案只能利用自身的物化視圖進行查詢改寫,如果需要利用其他專案中的物化視圖進行改寫,您需要在查詢語句前添加set odps.sql.materialized.view.source.project.white.list=<project_name1>,<project_name2>,<project_name3>;配置指定其他MaxCompute專案列表。
MaxCompute中物化視圖的查詢改寫支援的運算元類型及與其他產品的對照關係如下。
運算元類型 | 分類 | MaxCompute | BigQuery | Amazon RedShift | Hive |
FILTER | 運算式完全符合 | 支援 | 支援 | 支援 | 支援 |
運算式部分匹配 | 支援 | 支援 | 支援 | 支援 | |
AGGREGATE | 單個AGGREGATE | 支援 | 支援 | 支援 | 支援 |
多個AGGREGATE | 不支援 | 不支援 | 不支援 | 不支援 | |
JOIN | JOIN類型 | INNER JOIN | 不支援 | INNER JOIN | INNER JOIN |
單個JOIN | 支援 | 不支援 | 支援 | 支援 | |
多個JOIN | 支援 | 不支援 | 支援 | 支援 | |
AGGREGATE+JOIN | - | 支援 | 不支援 | 支援 | 支援 |
使用物化視圖查詢改寫的原則是查詢語句中需要的資料必須從物化視圖中得到,包括輸出資料行、篩選條件中需要的列、彙總函式需要的列、JOIN條件需要的列。如果查詢語句中需要的列不包含在物化視圖中或彙總函式不支援,則無法基於物化視圖進行查詢改寫。
改寫帶過濾條件的查詢語句
建立物化視圖樣本如下。
CREATE MATERIALIZED VIEW mv AS SELECT a,b,c FROM src WHERE a>5;基於建立的物化視圖執行查詢語句,查詢改寫對照如下。
原始查詢語句
改寫後的查詢語句
SELECT a,b FROM src WHERE a>5;SELECT a,b FROM mv;SELECT a, b FROM src WHERE a=10;SELECT a,b FROM mv WHERE a=10;SELECT a, b FROM src WHERE a=10 AND b=3;SELECT a,b FROM mv WHERE a=10 AND b=3;SELECT a, b FROM src WHERE a>3;(SELECT a,b FROM src WHERE a>3 AND a<=5) UNION (SELECT a,b FROM mv);SELECT a, b FROM src WHERE a=10 AND d=4;改寫不成功,因為mv中沒有d列。
SELECT d, e FROM src WHERE a=10;改寫不成功,因為mv中沒有d、e列。
SELECT a, b FROM src WHERE a=1;改寫不成功,因為mv中沒有a=1的資料。
改寫帶彙總函式的查詢語句
如果物化視圖的SQL語句和查詢語句的彙總Key相同,那麼所有彙總函式都可以改寫,如果彙總Key不相同,只支援SUM、MIN和MAX。
建立的物化視圖如下。
CREATE MATERIALIZED VIEW mv AS SELECT a, b, sum(c) AS sum, count(d) AS cnt FROM src GROUP BY a, b;基於建立的物化視圖執行查詢語句,查詢改寫對照如下。
原始查詢語句
改寫後的查詢語句
SELECT a, sum(c) FROM src GROUP BY a;SELECT a, sum(sum) FROM mv GROUP BY a;SELECT a, count(d) FROM src GROUP BY a, b;SELECT a, cnt FROM mv;SELECT a, count(b) FROM (SELECT a, b FROM src GROUP BY a, b) GROUP BY a;SELECT a,count(b) FROM mv GROUP BY a;SELECT a,count(b) FROM mv GROUP BY a;改寫不成功,視圖對a、b列進行過彙總,不能再對b進行彙總。
SELECT a, count(c) FROM src GROUP BY a;改寫不成功,對於COUNT函數不支援重新彙總。
如果彙總函式中有DISTINCT,當物化視圖語句和查詢語句彙總Key相同,可以改寫,否則不可以改寫。
建立的物化視圖如下。
CREATE MATERIALIZED VIEW mv AS SELECT a, b, sum(DISTINCT c) AS sum, count(DISTINCT d) AS cnt FROM src GROUP BY a, b;基於建立的物化視圖執行查詢語句,查詢改寫對照如下。
原始查詢語句
改寫後的查詢語句
SELECT a, count(DISTINCT d) FROM src GROUP BY a, b;SELECT a, cnt FROM mv;SELECT a, count(c) FROM src GROUP BY a, b;改寫不成功,對於COUNT函數不支援重新彙總。
SELECT a, count(DISTINCT c) FROM src GROUP BY a;改寫不成功,因為需要對a再進行彙總。
改寫帶JOIN的查詢語句
改寫JOIN輸入
建立的物化視圖如下。
CREATE MATERIALIZED VIEW mv1 AS SELECT a, b FROM j1 WHERE b > 10; CREATE MATERIALIZED VIEW mv2 AS SELECT a, b FROM j2 WHERE b > 10;基於建立的物化視圖執行查詢語句,查詢改寫對照如下。
原始查詢語句
改寫後的查詢語句
SELECT j1.a,j1.b,j2.a FROM (SELECT a,b FROM j1 WHERE b > 10) j1 JOIN j2 ON j1.a=j2.a;SELECT mv1.a, mv1.b, j2.a FROM mv1 JOIN j2 ON mv1.a=j2.a;SELECT j1.a,j1.b,j2.a FROM (SELECT a,b FROM j1 WHERE b > 10) j1 JOIN (SELECT a,b FROM j2 WHERE b > 10) j2 ON j1.a=j2.a;SELECT mv1.a,mv1.b,mv2.a FROM mv1 JOIN mv2 ON mv1.a=mv2.a;
JOIN帶過濾條件
建立的物化視圖如下。
--建立非分區物化視圖。 CREATE MATERIALIZED VIEW mv1 AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a=j2.a; CREATE MATERIALIZED VIEW mv2 AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a > 10; --建立分區物化視圖。 CREATE MATERIALIZED VIEW mv LIFECYCLE 7 PARTITIONED BY (ds) AS SELECT t1.id, t1.ds AS ds FROM t1 JOIN t2 ON t1.id = t2.id;基於建立的物化視圖執行查詢語句,查詢改寫對照如下。
原始查詢語句
改寫後的查詢語句
SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a=4;SELECT a, b FROM mv1 WHERE a=4;SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a > 20;SELECT a,b FROM mv2 WHERE a>20;SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a > 5;(SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j1.a > 5 AND j1.a <= 10) UNION SELECT * FROM mv2;SELECT key FROM t1 JOIN t2 ON t1.id= t2.id WHERE t1.ds='20210306';SELECT key FROM mv WHERE ds='20210306';SELECT key FROM t1 JOIN t2 ON t1.id= t2.id WHERE t1.ds>='20210306';SELECT key FROM mv WHERE ds>='20210306';SELECT j1.a,j1.b FROM j1 JOIN j2 ON j1.a=j2.a WHERE j2.a=4;改寫不成功,因為物化視圖沒有j2.a列。
JOIN增加表
建立的物化視圖如下。
CREATE MATERIALIZED VIEW mv AS SELECT j1.a, j1.b FROM j1 JOIN j2 ON j1.a=j2.a;基於建立的物化視圖執行查詢語句,查詢改寫對照如下。
原始查詢語句
改寫後的查詢語句
SELECT j1.a, j1.b FROM j1 JOIN j2 JOIN j3 ON j1.a=j2.a AND j1.a=j3.a;SELECT mv.a, mv.b FROM mv JOIN j3 ON mv.a=j3.a;SELECT j1.a, j1.b FROM j1 JOIN j2 JOIN j3 ON j1.a=j2.a AND j2.a=j3.a;SELECT mv.a,mv.b FROM mv JOIN j3 ON mv.a=j3.a;
以上三種語句可以相互結合,如果查詢語句符合改寫條件,則可以改寫。
MaxCompute會選擇最佳的改寫規則運行,如果改寫後增加了一些操作,不是最優運行計劃,最終也不會被選中。
改寫帶LEFT JOIN的查詢語句
建立的物化視圖如下。
CREATE MATERIALIZED VIEW mv LIFECYCLE 7( user_id, job, total_amount ) AS SELECT t1.user_id, t1.job, sum(t2.order_amount) AS total_amount FROM user_info AS t1 LEFT JOIN sale_order AS t2 ON t1.user_id=t2.user_id GROUP BY t1.user_id;基於建立的物化視圖執行查詢語句,查詢改寫對照如下。
原始查詢語句
改寫後的查詢語句
SELECT t1.user_id, sum(t2.order_amout) AS total_amount FROM user_info AS t1 LEFT JOIN sale_order AS t2 ON t1.user_id=t2.user_id GROUP BY t1.user_id;SELECT user_id, total_amount FROM mv;
改寫帶UNION ALL的查詢語句
建立的物化視圖如下。
CREATE MATERIALIZED VIEW mv LIFECYCLE 7( user_id, tran_amount, tran_date ) AS SELECT user_id, tran_amount, tran_date FROM alipay_tran UNION ALL SELECT user_id, tran_amount, tran_date FROM unionpay_tran;基於建立的物化視圖執行查詢語句,查詢改寫對照如下。
原始查詢語句
改寫後的查詢語句
SELECT user_id, tran_amount FROM alipay_tran UNION ALL SELECT user_id, tran_amount FROM unionpay_tran;SELECT user_id, total_amount FROM mv;
物化視圖查詢穿透
對於分區物化視圖,不一定所有分區都有資料,可能只重新整理了最新的一些分區資料。但使用者查詢資料時,實際並不知道查詢的所有分區資料是否都存在,當查詢的分區資料不存在時,需要自動實現到原始分區表去查詢資料,流程如下圖所示。
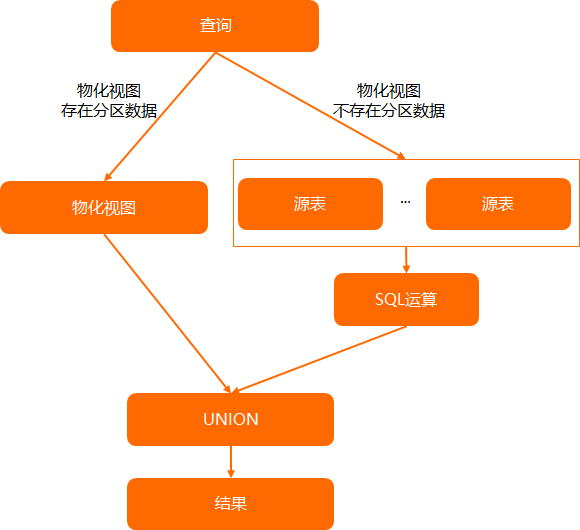
如果需要物化視圖支援穿透查詢能力,您需要設定如下參數:
建立物化視圖時,在tblproperties屬性中添加"enable_auto_substitute"="true"配置。
物化視圖支援穿透查詢樣本如下。
建立物化視圖支援分區並且支援查詢穿透。
-- 建立src表。 CREATE TABLE src(id bigint,name string) PARTITIONED BY (dt string); -- 插入資料。 INSERT INTO src PARTITION(dt='20210101') VALUES(1,'Alex'); INSERT INTO src PARTITION(dt='20210102') VALUES(2,'Flink'); --建立分區物化視圖支援穿透。 CREATE MATERIALIZED VIEW IF NOT EXISTS mv LIFECYCLE 7 PARTITIONED BY (dt) tblproperties("enable_auto_substitute"="true") AS SELECT id, name, dt FROM src;查詢表src中的分區為20210101的資料。
SELECT * FROM mv WHERE dt='20210101';查詢物化視圖mv中的分區為20210102的資料,自動穿透到源表查詢資料。
SELECT * FROM mv WHERE dt = '20210102'; --因為20210102的資料沒有物化,則需要把查詢轉化到對應的源表,等價於 SELECT * FROM (SELECT id, name, dt FROM src WHERE dt='20210102') t;查詢物化視圖mv中分區為20201230~20210102的資料,自動穿透到源表查詢的資料與物化視圖的資料執行UNION操作後再返回結果。
SELECT * FROM mv WHERE dt >= '20201230' AND dt<='20210102' AND id='5'; --因為20210102的資料沒有物化,則需要把查詢轉化到對應的源表。等價於: SELECT * FROM (SELECT id, name, dt FROM src WHERE dt='20211231' OR dt='20210102' UNION ALL SELECT * FROM mv WHERE dt='20210101' ) t WHERE id = '5';
相關命令
ALTER MATERIALIZED VIEW:更新物化視圖、修改物化視圖的生命週期、開啟或禁用物化視圖的生命週期和刪除物化視圖分區。
DESC TABLE/VIEW:查看MaxCompute物化視圖的資訊。
SELECT MATERIALIZED VIEW:查詢物化檢視狀態。
DROP MATERIALIZED VIEW:刪除已建立的物化視圖。