本文為您介紹如何使用DataWorks的PyODPS類型節點,結合開源結巴中文分詞庫,對資料表中的中文欄位進行分詞處理並寫入新的資料表,以及如何通過閉包函數使用自訂字典進行分詞。
前提條件
已建立DataWorks工作空間並綁定了MaxCompute計算引擎建立工作空間。
背景資訊
DataWorks為您提供PyODPS節點,您可以在DataWorks的PyODPS節點上直接編輯Python代碼,並使用MaxCompute的Python SDK。DataWorks的PyODPS節點包括PyODPS 2節點和PyODPS 3節點,建議您使用PyODPS 3節點,詳情請參見開發PyODPS 3任務。
本文的操作僅作為程式碼範例,不建議用於實際的生產環境。
準備工作:下載開源結巴中文分詞包
請在GitHub下載開源結巴分詞中文包。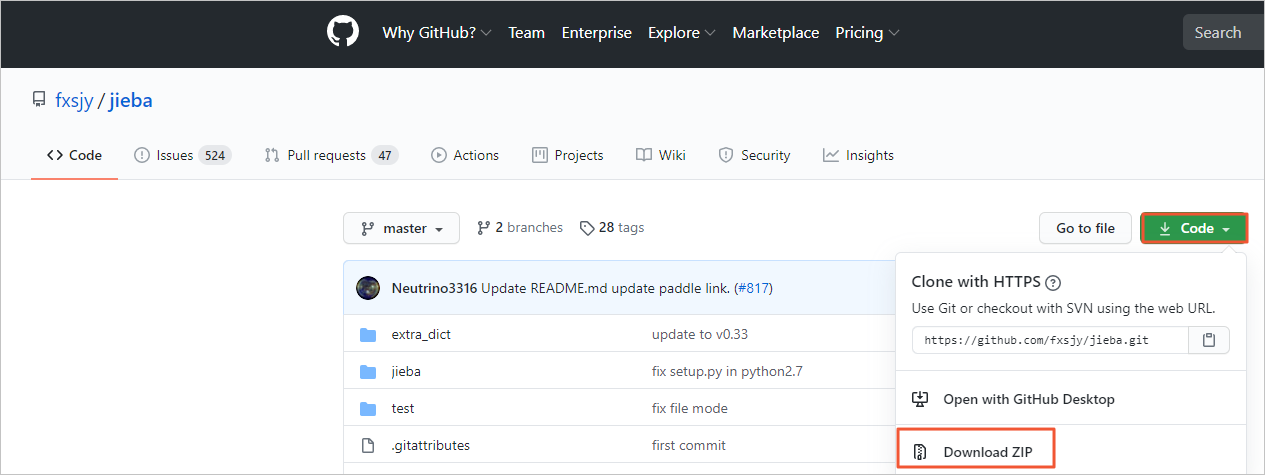
實踐1:使用開源詞包進行分詞
建立商務程序。
操作詳情請參見建立商務程序。
建立MaxCompute資源並上傳jieba-master.zip包。
右鍵建立的商務程序,選擇。
在建立資源對話方塊中,配置各項參數,完成後單擊建立。
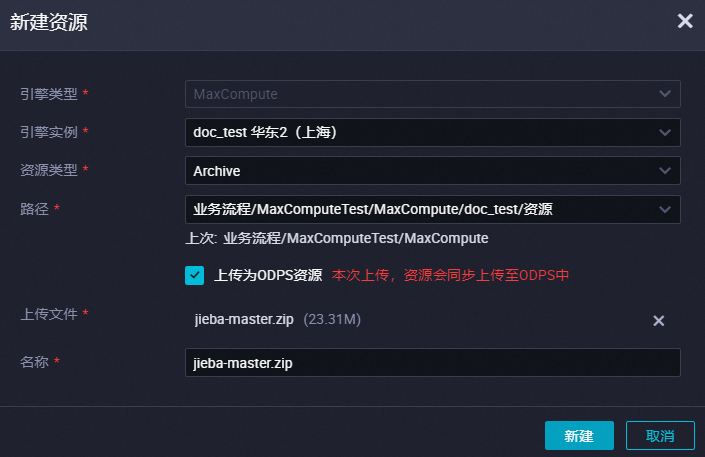 核心參數配置說明如下。
核心參數配置說明如下。參數
描述
上傳檔案
單擊點擊上傳,根據介面提示選擇已下載的jieba-master.zip檔案。
名稱
資源的名稱,無需和上傳的檔案名稱保持一致,但需要符合命名規範,您可根據介面命名規範提示自訂資源名稱,本實踐名稱可配置為jieba-master.zip。
單擊工具列中的
 表徵圖,根據介面提示提交建立的資源。
表徵圖,根據介面提示提交建立的資源。
建立測試資料表jieba_test和測試結果表jieba_result。
您可以右鍵建立的商務程序,選擇,根據介面提示建立表,並使用DDL模式配置表的欄位資訊。本實踐需要建立的兩個表的配置要點如下。
表名
DDL語句
作用
jieba_test
CREATE TABLE jieba_test ( `chinese` string, `content` string );用於儲存測試的資料。
jieba_result
CREATE TABLE jieba_result ( `chinese` string ) ;用於儲存分詞測試結果資料。
建立完成後,提交表到開發環境。
下載測試資料並匯入測試資料表jieba_test。
單擊分詞測試資料下載測試資料jieba_test.csv至本地。
在資料開發頁面,單擊
 表徵圖。
表徵圖。在資料匯入嚮導對話方塊中,輸入需要匯入資料的測試表jieba_test並選中,單擊下一步。
單擊瀏覽,上傳您下載至本地的jieba_test.csv檔案,單擊下一步。
選中按名稱匹配,單擊匯入資料。
建立PyODPS 3節點。
右鍵建立的商務程序,選擇。
在建立節點對話方塊中,輸入名稱(樣本為word_split),單擊確認。
使用開源詞包測試回合分詞代碼。
在PyODPS 3節點中運行下方範例程式碼,對上傳至jieba_test表中的測試資料進行分詞,並回顯分詞結果表的前十行資料。
def test(input_var): import jieba result = jieba.cut(input_var, cut_all=False) return "/ ".join(result) # odps.stage.mapper.split.size 可用於提高執行並行度 hints = { 'odps.isolation.session.enable': True, 'odps.stage.mapper.split.size': 64, } libraries =['jieba-master.zip'] # 引用您的 jieba-master.zip 壓縮包 src_df = o.get_table('jieba_test').to_df() # 引用您的 jieba_test 表中的資料 result_df = src_df.chinese.map(test).persist('jieba_result', hints=hints, libraries=libraries) print(result_df.head(10)) # 查看分詞結果前10行,更多資料需要在表 jieba_result 中查看說明odps.stage.mapper.split.size 可用於提高執行並行度,詳情請參見Flag參數列表。
查看運行結果。
運行完成後,您可以在頁面下方的作業記錄地區查看結巴分詞程式的運行結果。
您也可以在頁面左側單擊臨時查詢按鈕,建立一個臨時查詢節點,查看測試結果表jieba_result中的結果資料。
select * from jieba_result;
實踐2:使用自訂詞庫進行分詞
如果開源結巴分詞的詞庫無法滿足您的需求,需要使用自訂的詞典對分詞結果進行進一步修正,以下為您樣本如何使用自訂詞庫進行分詞。
建立MaxCompute資源。
PyODPS自訂函數可以讀取上傳至MaxCompute的資源(表資源或檔案資源)。此時,自訂函數需要寫為閉包函數或Callable類。如果您需要引用複雜的自訂函數,則可以使用DataWorks的註冊MaxCompute函數功能,詳情請參見建立並使用自訂函數。
本實踐以使用閉包函數的方式,引用上傳至MaxCompute的資源檔(即自訂字典)key_words.txt。
建立File類型的MaxCompute函數。
右鍵建立的商務程序,選擇,輸入資源名稱key_words.txt後單擊建立。
輸入自訂詞庫內容並儲存、提交。
以下為自訂詞庫的樣本,您可以根據自己的測試需求輸入合適的自訂詞庫。
增量備份 安全合規
使用自訂詞庫測試回合分詞代碼。
在PyODPS 3節點中運行下方範例程式碼,對上傳至jieba_test表中的測試資料進行分詞,並回顯分詞結果表的前十行資料。
重要執行下述代碼前,您需要提前建立一個結果表
jieba_result2,用於儲存自訂詞庫進行分詞的測試結果資料。具體操作請參見建立測試結果表jieba_result。def test(resources): import jieba fileobj = resources[0] jieba.load_userdict(fileobj) def h(input_var): # 在嵌套函數h()中,執行詞典載入和分詞 result = jieba.cut(input_var, cut_all=False) return "/ ".join(result) return h # odps.stage.mapper.split.size 可用於提高執行並行度 hints = { 'odps.isolation.session.enable': True, 'odps.stage.mapper.split.size': 64, } libraries =['jieba-master.zip'] # 引用您的 jieba-master.zip 壓縮包 src_df = o.get_table('jieba_test').to_df() # 引用您的 jieba_test 表中的資料 file_object = o.get_resource('key_words.txt') # get_resource() 引用 MaxCompute 資源 mapped_df = src_df.chinese.map(test, resources=[file_object]) # map調用函數,並傳遞 resources 參數 result_df = mapped_df.persist('jieba_result2', hints=hints, libraries=libraries) print(result_df.head(10)) # 查看分詞結果前10行,更多資料需要在表 jieba_result2 中查看說明odps.stage.mapper.split.size 可用於提高執行並行度,詳情請參見Flag參數列表。
查看運行結果。
運行完成後,您可以在頁面下方的作業記錄地區查看結巴分詞程式的運行結果。
您也可以在頁面左側單擊臨時查詢按鈕,建立一個臨時查詢節點,查看測試結果表jieba_result2中的結果資料。
select * from jieba_result2;
對比自訂詞庫與開源詞包的運行結果。
相關文檔
更多關於DataWorks中PyODPS 3節點的使用請參見通過DataWorks使用PyODPS。