本文為您介紹如何使用DataWorksData Integration同步功能自動建立分區,動態地將RDS中的資料移轉至MaxComputeMaxCompute。
前提條件
準備DataWorks環境
在DataWorks上完成建立商務程序,本例使用DataWorks簡單模式。詳情請參見建立商務程序。
新增資料來源
新增MySQL資料來源作為資料來源,詳情請參見配置MySQL資料來源。
新增MaxCompute資料來源作為目標資料來源接收RDS資料,詳情請參見配置MaxCompute資料來源。
自動建立分區
準備工作完成後,需要將RDS中的資料定時每天同步到MaxCompute中,自動建立按天日期的分區。詳細的資料同步任務的操作和配置請參見DataWorks資料開發和營運。
本例使用DataWorks簡單模式,建立工作空間時,預設保持參加資料開發(Data Studio)公測不開啟,公測工作空間不適用本例。
登入DataWorks控制台。
在MaxCompute上建立目標表。
在左側導覽列,單擊工作空間。
單擊相應工作空間操作列的快速進入 > 資料開發。
按右鍵已建立的商務程序,選擇。
在建立表頁面,選擇引擎執行個體、Schema和路徑後,輸入表名,並單擊建立。
在表的編輯頁面,單擊
 表徵圖,切換為DDL模式。
表徵圖,切換為DDL模式。在DDL對話方塊,輸入如下建表語句,單擊產生表結構。然後在確認操作對話方塊裡單擊確認。
CREATE TABLE IF NOT EXISTS ods_user_info_d ( uid STRING COMMENT '使用者ID', gender STRING COMMENT '性別', age_range STRING COMMENT '年齡段', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING );單擊提交到生產環境。
建立離線同步節點。
進入資料開發頁面,按右鍵指定商務程序,選擇。
在建立節點對話方塊中,輸入節點名稱,並單擊確認。
選擇資料來源、資源群組和資料去向,並測試連通性。
資料來源:已建立的MySQL資料來源。
我的資源群組:選擇獨享Data Integration資源群組。
資料去向:已建立的MaxCompute資料來源。
單擊下一步,配置任務。
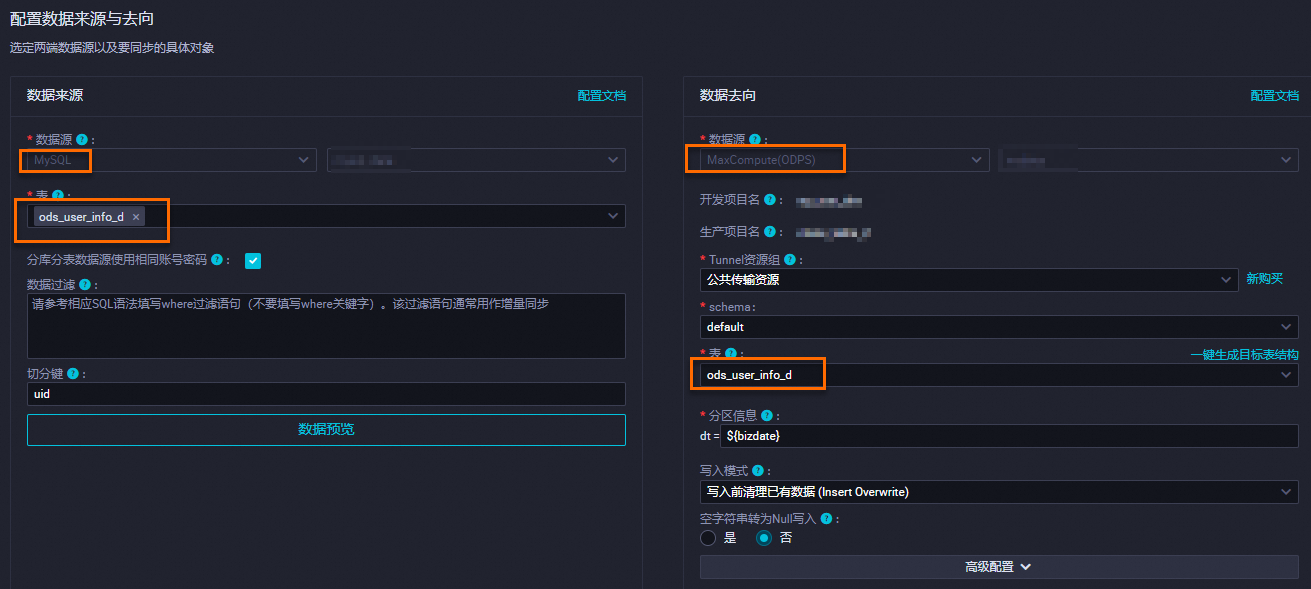
配置分區參數。
在右側導覽列上,單擊調度配置。
在調度參數地區,設定參數。參數值預設為系統內建的時間參數
${bizdate},格式為yyyymmdd。說明預設參數值與資料去向中的分區資訊值對應。調度執行遷移任務時,目標表的分區值會被自動替換為任務執行日期的前一天,預設情況下,您會在當前執行前一天的業務資料,這個日期也叫做業務日期。如果您需要使用當天任務啟動並執行日期作為分區值,則需自訂參數值。
自訂參數設定:使用者可以自主選擇某一天和格式配置,如下所示:
後N年:
$[add_months(yyyymmdd,12*N)]前N年:
$[add_months(yyyymmdd,-12*N)]前N月:
$[add_months(yyyymmdd,-N)]後N周:
$[yyyymmdd+7*N]後N月:
$[add_months(yyyymmdd,N)]前N周:
$[yyyymmdd-7*N]後N天:
$[yyyymmdd+N]前N天:
$[yyyymmdd-N]後N小時:
$[hh24miss+N/24]前N小時:
$[hh24miss-N/24]後N分鐘:
$[hh24miss+N/24/60]前N分鐘:
$[hh24miss-N/24/60]
說明使用中括弧([])編輯自訂變數參數的取值計算公式,例如
key1=$[yyyy-mm-dd]。預設情況下,自訂變數參數的計算單位為天。例如
$[hh24miss-N/24/60]表示(yyyymmddhh24miss-(N/24/60 * 1天))的計算結果,然後按 hh24miss 的格式取時分秒。使用add_months的計算單位為月。例如
$[add_months(yyyymmdd,12 N)-M/24/60]表示(yyyymmddhh24miss-(12 * N * 1月))-(M/24/60 * 1天)的結果,然後按yyyymmdd的格式取年月日。
單擊
 表徵圖運行代碼。
表徵圖運行代碼。您可以在作業記錄查看運行結果。
補資料實驗
如果您的資料中存在大量運行日期之前的歷史資料,需要實現自動同步和自動分區。您可以通過DataWorks的營運中心,選擇當前的同步資料節點,使用補資料功能實現。
在RDS端按照日期篩選出歷史資料。
您可以在同步節點資料來源地區設定資料過濾條件(例如設定為
${bizdate})。執行補資料操作。詳情請參見執行補資料並查看補資料執行個體(新版)。
在啟動並執行日誌中查看對RDS資料的抽取結果。
從運行結果中可以看到MaxCompute已自動建立分區。

運行結果驗證。在MaxCompute用戶端執行如下命令,查看資料寫入情況。
SELECT count(*) from ods_user_info_d where dt = 20180913;
Hash實現非日期欄位分區
如果您的資料量較大,或沒有按照日期欄位對第一次全量的資料進行分區,而是按照省份等非日期欄位分區,則此時Data Integration操作將不能實現自動分區。這種情況下,您可以按照RDS中某個欄位進行Hash,將相同的欄位值自動存放到這個欄位對應值的MaxCompute分區中。
將資料全量同步到MaxCompute的一個暫存資料表,建立一個SQL指令碼節點。執行如下命令。
drop table if exists ods_user_t; CREATE TABLE ods_user_t ( dt STRING, uid STRING, gender STRING, age_range STRING, zodiac STRING); --將MaxCompute表中的資料存入暫存資料表。 insert overwrite table ods_user_t select dt,uid,gender,age_range,zodiac from ods_user_info_d;建立同步任務的節點mysql_to_odps,即簡單的同步任務。將RDS資料全量同步到MaxCompute,無需設定分區。
使用SQL語句進行動態分區到目標表,命令如下。
drop table if exists ods_user_d; //建立一個ODPS分區表(最終目的表)。 CREATE TABLE ods_user_d ( uid STRING, gender STRING, age_range STRING, zodiac STRING ) PARTITIONED BY ( dt STRING ); //執行動態分區SQL,按照暫存資料表的欄位dt自動分區,dt欄位中相同的資料值,會按照這個資料值自動建立一個分區值。 //例如dt中有些資料是20181025,會自動在ODPS分區表中建立一個分區,dt=20181025。 //動態分區SQL如下。 //可以注意到SQL中select的欄位多寫了一個dt,就是指定按照這個欄位自動建立分區。 insert overwrite table ods_user_d partition(dt)select dt,uid,gender,age_range,zodiac from ods_user_t; //匯入完成後,可以把暫存資料表刪除,節約儲存成本。 drop table if exists ods_user_t;在MaxCompute中您可以通過SQL陳述式完成資料同步。
將三個節點配置成一個工作流程,按順序執行。

查看執行過程。您可以重點觀察最後一個節點的動態分區過程。
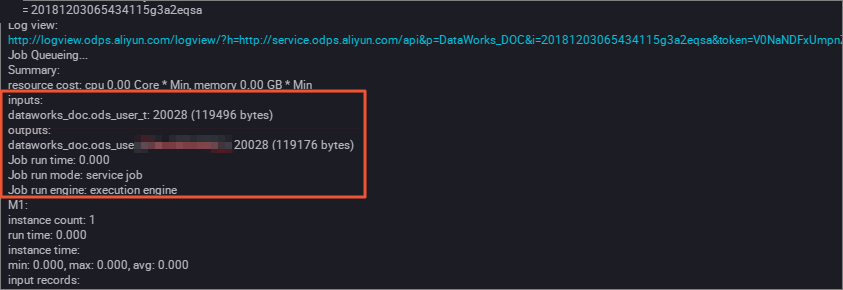
運行結果驗證。在MaxCompute用戶端執行如下命令,查看資料寫入情況。
SELECT count(*) from ods_user_d where dt = 20180913;