雜湊聚簇(Hash Clustering)表通過設定表的Shuffle和Sort屬性,進而MaxCompute根據資料已有的儲存特性,最佳化執行計畫,提高效率,節省資源消耗。本文為您介紹在MaxCompute中如何使用Hash Clustering表。
背景資訊
id列串連起來。SELECT t1.a, t2.b FROM t1 JOIN t2 ON t1.id = t2.id;- Broadcast Hash Join
當Join表中存在一個很小的表時,MaxCompute採用此方式,即把小表廣播傳遞到所有的Join Task Instance上面,然後直接和大表做Hash Join。
- Shuffle Hash Join
如果Join表比較大,就不能直接廣播了。這時候把兩個表按照Join Key做Hash Shuffle,由於相同的索引值Hash結果也是一樣的,這就保證了相同的Key的記錄會收集到同一個Join Task Instance上面。然後每個Instance對資料量小的一路建Hash表,資料量大的順序讀取Join。
- Sort Merge Join如果Join的表資料更大一些,Shuffle Hash Join方法也用不了,因為記憶體已經不足以容納建立一個Hash Table。這時的實現方法是:先按照Join Key做Hash Shuffle,然後再按照Join Key做排序(Sort),最後對Join雙方做一個歸併,具體流程如下圖所示:
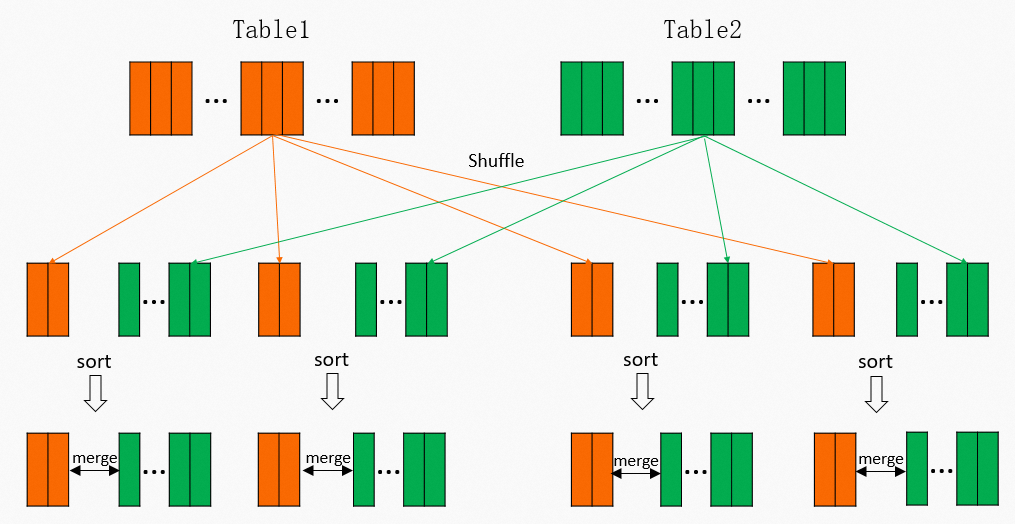 實際上對於MaxCompute目前資料量和規模,絕大多數情況下都是使用的Sort Merge Join,但這其實是非常昂貴的操作。從上圖可以看到,Shuffle的時候需要一次計算,並且中間結果需要落盤,後續Reducer讀取的時候,又需要讀取和排序的過程。對於
實際上對於MaxCompute目前資料量和規模,絕大多數情況下都是使用的Sort Merge Join,但這其實是非常昂貴的操作。從上圖可以看到,Shuffle的時候需要一次計算,並且中間結果需要落盤,後續Reducer讀取的時候,又需要讀取和排序的過程。對於M個Mapper和R個Reducer的情境,將產生M x R次的IO讀取。對應的Fuxi物理執行計畫如下所示,需要兩個Mapper Stage,一個Join Stage,其中紅色部分為Shuffle和Sort操作: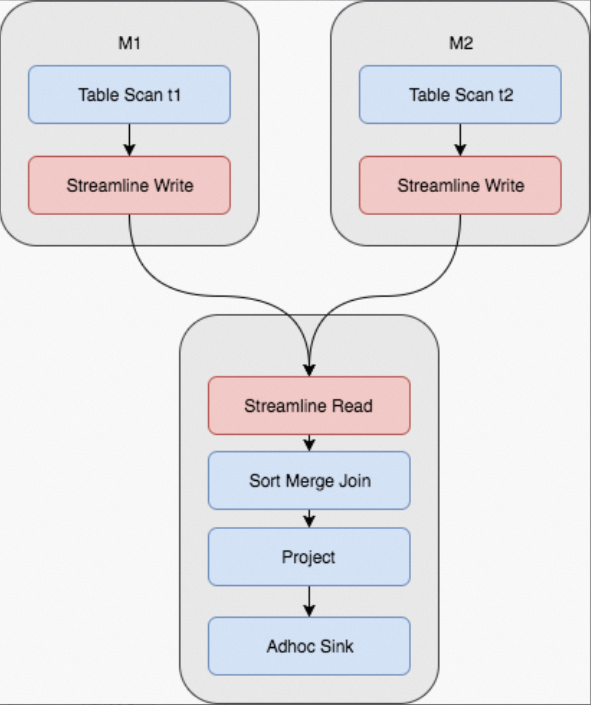 與此同時,有些Join是可能反覆發生的,比如將Query改為:
與此同時,有些Join是可能反覆發生的,比如將Query改為:
雖然選擇的列不一樣了,但是Join是完全一樣的,整個Shuffle和Sort的過程也是完全一樣的。SELECT t1.c, t2.d FROM t1 JOIN t2 ON t1.id = t2.id;又或者將Query改為:
這個時候對錶t1和t3來Join,但實際上對於t1而言,整個Shuffle和Sort過程還是完全一樣。SELECT t1.c, t3.d FROM t1 JOIN t3 ON t1.id = t3.id;於是,考慮如果初始表資料產生時,按照Hash Shuffle和Sort的方式儲存,那麼後續查詢中將避免對資料的再次Shuffle和Sort。這樣做的好處是,雖然建表時付出了一次性的代價,卻節省了將來可能產生的反覆的Shuffle和Join。這時Join的Fuxi物理執行計畫變成了如下,不僅節省了Shuffle和Sort的操作,並且查詢從3個Stage變成了1個Stage完成: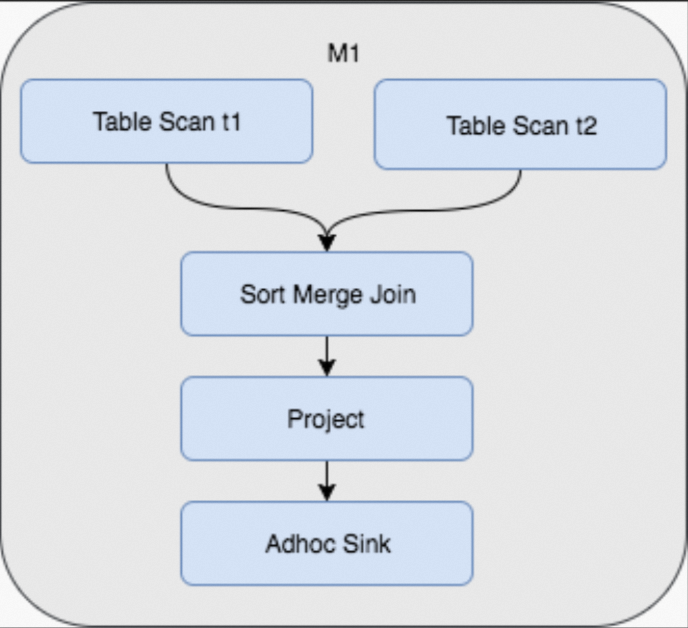
使用說明
建立Hash Clustering表
- 命令文法
CREATE TABLE [IF NOT EXISTS] <table_name> [(<col_name> <data_type> [comment <col_comment>], ...)] [comment <table_comment>] [PARTITIONED BY (<col_name> <data_type> [comment <col_comment>], ...)] [CLUSTERED BY (<col_name> [, <col_name>, ...]) [SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> BUCKETS] [AS <select_statement>] - 使用樣本。
- 非分區表。
CREATE TABLE T1 (a string, b string, c bigint) CLUSTERED BY (c) SORTED by (c) INTO 1024 BUCKETS; - 分區表。
CREATE TABLE T1 (a string, b string, c bigint) PARTITIONED BY (dt string) CLUSTERED BY (c) SORTED by (c) INTO 1024 BUCKETS;
- 非分區表。
- 屬性說明
- CLUSTERED BY
指定Hash Key,MaxCompute將對指定列進行Hash運算,按照Hash值分散到各個Bucket裡面。為避免資料扭曲,避免熱點,取得較好的並存執行效果,CLUSTERED BY列適宜選擇取值範圍大、重複索引值少的列。此外為了達到Join最佳化的目的,也應該考慮選取常用的Join或Aggregation Key,即類似於傳統資料庫中的主鍵。
- SORTED BY
指定在Bucket內欄位的排序方式,建議Sorted By和Clustered By一致,以取得較好的效能。此外當SORTED BY子句指定之後,MaxCompute將自動產生索引,並且在查詢的時候利用索引來加速執行。
- INTO number_of_buckets BUCKETS
指定雜湊桶的數目,這個數字必須提供,由資料量大小來決定。Bucket越多並發度越大,Job整體已耗用時間越短,但同時如果Bucket太多的話,可能導致小檔案太多,另外並發度過高也會造成CPU時間的增加。目前推薦設定讓每個Bucket資料大小在500MB ~ 1GB之間,如果是特別大的表,這個數值可以適當增加。對於Join最佳化的情境,兩個表的Join要去掉Shuffle和Sort步驟,要求雜湊桶數目成倍數關係,比如
256和512。目前建議桶的數目統一使用2的N次冪,比如512、1024、2048、4096,這樣系統可以自動進行雜湊桶的分裂和合并時,也可以去除Shuffle和Sort的步驟。
- CLUSTERED BY
更改表的Hash Clustering屬性
- 命令語句
--更改表為Hash Clustering表 ALTER TABLE <table_name> [CLUSTERED BY (<col_name> [, <col_name>, ...]) [SORTED BY (<col_name> [ASC | DESC] [, <col_name> [ASC | DESC] ...])] INTO <number_of_buckets> BUCKETS]; --更改Hash Clustering表為非Hash Clustering表 ALTER TABLE <table_name> NOT CLUSTERED; - 注意事項
- ALTER TABLE語句改變聚集屬性,只對於分區表有效,非分區表一旦聚集屬性建立就無法改變。
- ALTER TABLE語句只會影響分區表的建立分區(包括insert overwrite產生的),新分區將按新的聚集屬性儲存區,老的資料分區保持不變。
- 由於ALTER TABLE語句隻影響新分區,所以該語句不可以再指定PARTITION。
表屬性顯式驗證
Extended Info裡面。DESC EXTENDED <table_name>;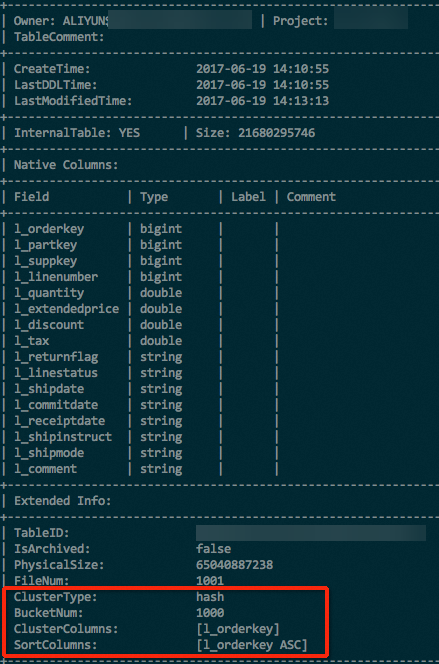 對於分區表,除了使用以上命令查看錶屬性之後,還需要通過以下命令查看分區的屬性。
對於分區表,除了使用以上命令查看錶屬性之後,還需要通過以下命令查看分區的屬性。DESC EXTENDED <table_name> partition(<pt_spec>);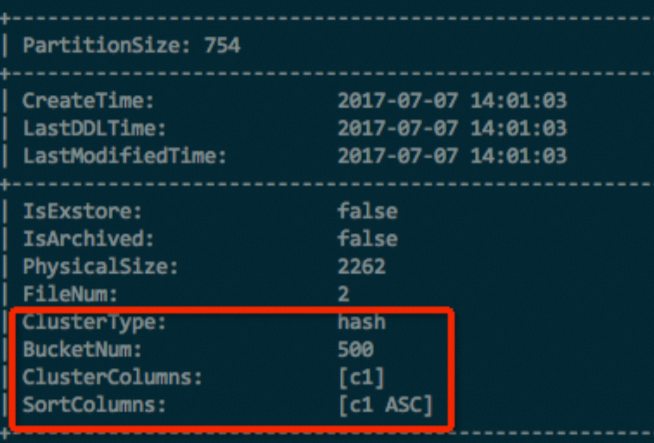
Hash Clustering優勢
Bucket Pruning和Index最佳化
CREATE TABLE t1 (id bigint,
a string,
b string)
CLUSTERED BY (id)
SORTED BY (id) into 1000 BUCKETS;
...
SELECT t1.a, t1.b FROM t1 WHERE t1.id=12345;id做Hash Shuffle,並且對id做排序,查詢可以極大簡化:- 通過查詢值
12345找到對應的Hash Bucket,這時候我們只需要在1個Bucket裡面掃描,而不是全部1000個Bucket裡面掃描。稱之為Bucket Pruning。 - 因為Bucket內資料按
id排序存放,MaxCompute會自動建立Index,利用Index lookup直接定位到相關記錄。
例如一個巨量資料任務,一共起了1111個Mapper,讀取了427億條記錄,最後找符合條件記錄26條,總共耗時1分48秒。同樣的資料、同樣的查詢,使用Hash Clustering表來做,可以直接定位到單個Bucket,並利用Index唯讀取包含查詢資料的Page,只用4個Mapper,讀取10000條記錄,總共耗時只需要6秒。
Aggregation最佳化
SELECT department, SUM(salary) FROM employee GROUP BY (department);department列資料進行Shuffle和Sort,然後做Stream Aggregate,統計每一個departmentGroup。但是如果表資料已經CLUSTERED BY (department) SORTED BY (department),那麼這個Shuffle和Sort的操作,也就相應節省掉了。儲存最佳化
即便不考慮以上所述的各種計算上的最佳化,單單是把表Shuffle並排序儲存,都會對於儲存空間節省上有很大協助。因為MaxCompute底層使用列儲存,通過排序,將索引值相同或相近的記錄存放到一起,對於壓縮、編碼都會更加友好,從而使得壓縮效率更高。在實際測試中,某些極端情況下,排序儲存的表可以比無序表的儲存空間節省50%。對於生命週期很長的表,使用Hash Clustering儲存,是一個很值得的最佳化。
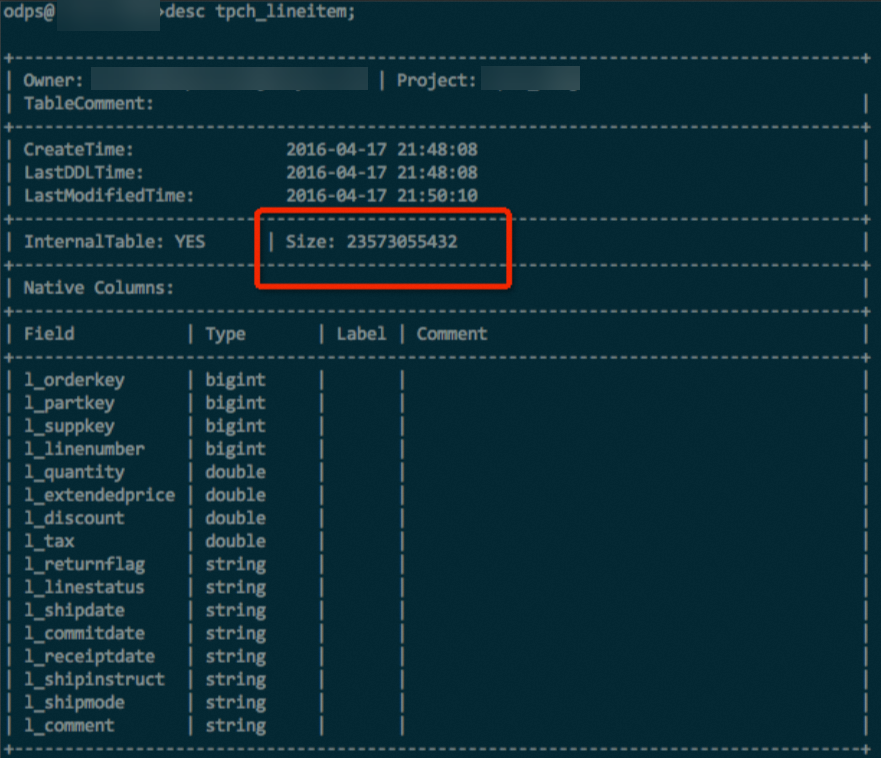
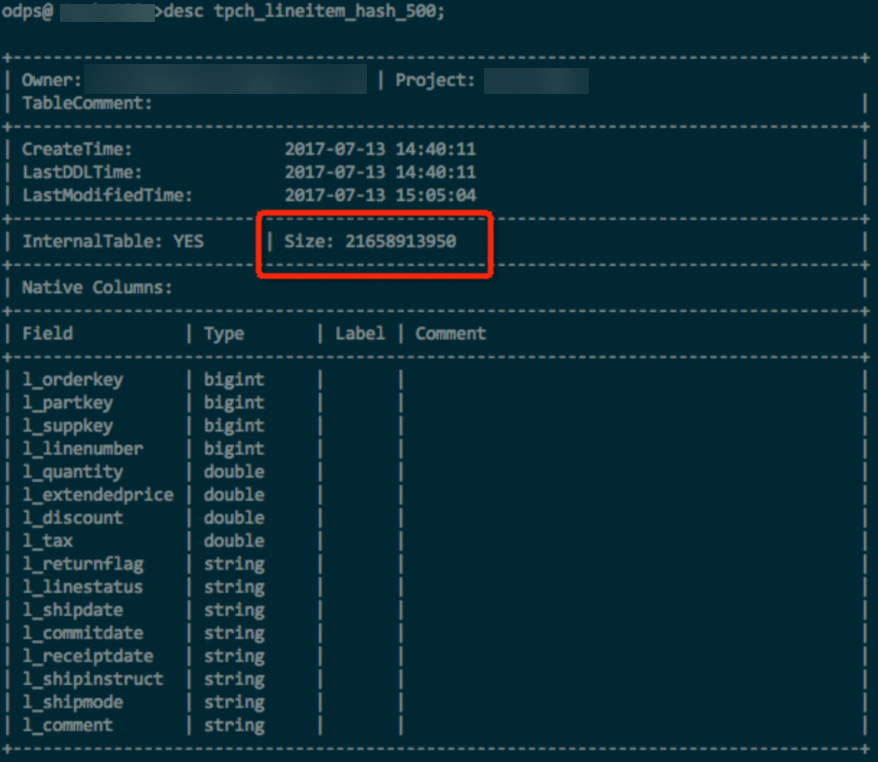
lineitem表,包含了int、double、string等多種資料類型,在資料和壓縮方式等完全一樣的情況下,對比使用Hash Clustering和未使用Hash Clustering的表格儲存體大小,使用Hash Clustering的表格儲存體節省了約10%,如下圖所示。- 未使用Hash Clustering。
- 使用Hash Clustering。
測試資料及分析
對於Hash Clustering整體帶來的效能收益,通過標準的TPC-H測試集進行衡量。測試使用1TB資料,統一使用500 Buckets,除了nation和region兩個極小的表以外,其餘所有表均按照第一個列作為Cluster和Sort Key。整體測試結果表明,在使用了Hash Clustering之後,總CPU時間減少了約17.3%,總的Job已耗用時間減少了約12.8%。
需要注意到是TPC-H裡並不是所有的Query都可以利用到Clustering屬性,特別是兩個耗時最長的Query沒有辦法利用上,所以從總體上的效率提升並不是非常驚人。但如果單看可以利用上Clustering屬性的Query,收益還是非常明顯的,比如Q4快了約68%、Q12快了約62%、Q10快了約47%等。
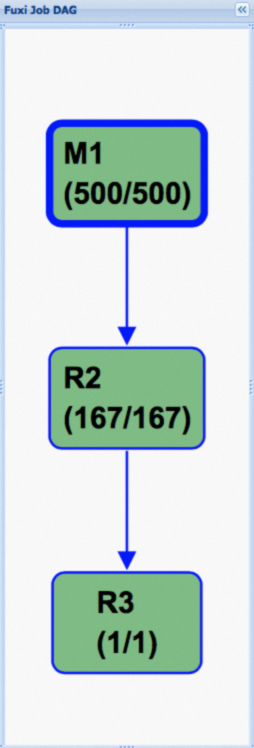
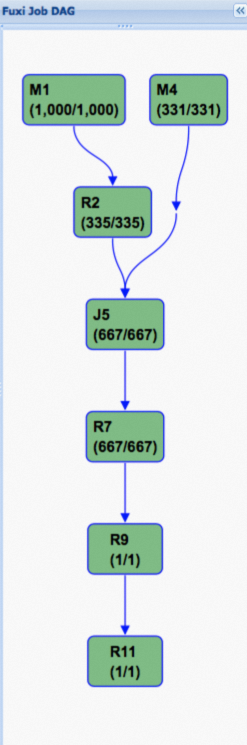 而下面則是使用Hash Clustering之後的執行計畫,可以看到,此DAG被大大簡化,這也是效能得到大幅提升的關鍵原因。
而下面則是使用Hash Clustering之後的執行計畫,可以看到,此DAG被大大簡化,這也是效能得到大幅提升的關鍵原因。