在實際業務開發過程中,企業通常要求作業能在期望的時間節點前產出結果,並根據結果做進一步決策,這就需要作業開發人員及時關注作業運行狀態,識別並最佳化慢作業。您可以通過MaxCompute的Logview功能診斷慢作業。本文為您介紹導致出現慢作業的原因及如何查看慢作業並提供對應的解決措施。
分析運行出錯作業
作業運行失敗時,通過Logview中的Result頁簽可以查看出錯資訊,對於失敗的作業,開啟Logview預設會跳轉到Result頁簽。
常見失敗原因包括:
SQL語法錯誤,此時不會有DAG和Fuxi jobs,因為還未提交到計算叢集執行。
使用者UDF出錯,在Job Details頁簽中查看DAG圖,確定出問題的UDF,並查看StdOut或StdErr等報錯資訊。
其他報錯,可以參見文檔錯誤碼以及解決方案。
分析運行慢作業
編譯階段
作業處於編譯階段的特徵是有Logview,但還未執行計畫。根據Logview的子狀態(SubStatusHistory)可以進一步細分為調度、最佳化、產生物理執行計畫、資料跨叢集複製等子階段。 編譯階段的問題主要表現為在某個子階段卡住,即作業長時間停留在某一個子階段。下面將介紹作業停留在每個子階段的可能原因和解決措施。
編譯階段的問題主要表現為在某個子階段卡住,即作業長時間停留在某一個子階段。下面將介紹作業停留在每個子階段的可能原因和解決措施。
調度階段
問題現象:子狀態為
Waiting for cluster resource,作業排隊等待被編譯。產生原因:計算叢集資源緊缺。
解決措施:查看計算叢集的狀態,需要等待計算叢集的資源,如果是預付費客戶可以綜合考慮,對資源進行擴容。
最佳化階段
問題現象:子狀態為
SQLTask is optimizing query,最佳化器正在最佳化執行計畫。產生原因:執行計畫複雜,需要較長時間做最佳化。
解決措施:請耐心等待,正常不會超過10分鐘。
產生物理執行計畫階段
問題現象:子狀態為
SQLTask is generating execution plan。產生原因一:讀取的分區過多。
解決措施:需要最佳化設計SQL,減少分區的數量,包括:分區裁剪、過濾掉不需要讀的分區、把大作業拆成小作業。如何判斷SQL中分區剪裁是否生效,以及分區裁剪失效的常見情境請參考文章:分區剪裁合理性評估。
產生原因二:小檔案過多。 產生小檔案的原因主要有兩個:
使用Tunnel上傳資料時操作不正確(例如每上傳一條資料就重建立一個
upload session),具體可以參考文檔:Tunnel命令常見問題。對分區表進行
insert into操作時,會在partition目錄下面產生一個新檔案。
解決措施:
使用TunnelBufferedWriter介面,可以更簡單地進行上傳功能,同時避免存在過多小檔案。
手工執行一次小檔案合并,把小檔案Merge起來,更多內容請參考官方文檔:合并小檔案。
說明小檔案個數在萬以上可以執行小檔案合并動作,系統每天會自動進行小檔案合并,但是在一些特殊情境小檔案合并失敗後,需要手工執行合并。
資料跨叢集複製階段
問題現象:子狀態列表裡面出現多次
Task rerun,Result裡有錯誤資訊FAILED: ODPS-0110141:Data version exception。作業看似失敗了,實際還在執行,說明作業正在做資料的跨叢集複製。產生原因一:Project剛做叢集遷移,往往前一兩天有大量需要跨叢集複製的作業。
解決措施:這種情況是預期中的跨叢集複製,需要使用者等待。
產生原因二:Project做過遷移,分區過濾未能處理好,導致讀取了比較老的分區。
解決措施:過濾掉不必要讀取的老分區。
執行階段
Logview的Job Details介面有執行計畫(執行計畫沒有全部完畢),且作業狀態還是Running。執行階段卡住或執行時間比預期長的主要原因有等待資源、資料扭曲、UDF執行低效、資料膨脹等,下面將具體介紹每種情況的特徵和解決思路。
等待資源
特徵:Instance處於Ready狀態,或部分Instance是Running狀態,部分是Ready狀態。需要注意的是,如果Instance狀態是Ready,但有Debug歷史資訊,那麼可能是Instance Fail觸發重試,而不是在等待資源。
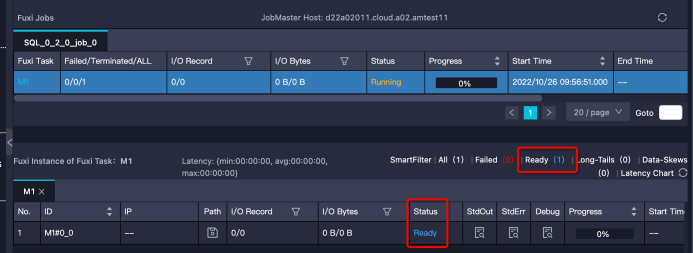
解決思路:。
確定排隊狀態是否正常。可以通過Logview的排隊資訊
Queue Length查看作業在隊列的位置:如下圖所示。 或者通過MaxCompute控制台查看對應Quota組的資源使用方式。如果某項資源的使用率已經接近甚至超過配額了,那麼證明Quota組資源緊張,作業有排隊是正常的。作業的調度順序不僅與作業提交時間、優先順序有關,還和作業所需記憶體或CPU資源大小能否被滿足有關。
或者通過MaxCompute控制台查看對應Quota組的資源使用方式。如果某項資源的使用率已經接近甚至超過配額了,那麼證明Quota組資源緊張,作業有排隊是正常的。作業的調度順序不僅與作業提交時間、優先順序有關,還和作業所需記憶體或CPU資源大小能否被滿足有關。查看Quota組中啟動並執行作業。
可能存在誤交了低優先順序的大作業(或批量提交了很多小作業),佔用了大量的資源,可以和作業的負責人協商,先把作業終止掉,讓出資源。
考慮走其他Quota組的專案。
對資源進行擴容(訂用帳戶客戶)。
資料扭曲
特徵:Task中大多數Instance都已經結束了,但仍有幾個Instance卻遲遲不結束(長尾)。如下圖中大多數Instance都結束了,但是還有21個的狀態是Running,這些Instance運行慢,可能是因為處理的資料較多。

解決思路:您可參考資料扭曲調優,其中介紹了一些導致資料扭曲的常見原因及對應的最佳化思路。
UDF執行低效
這裡的UDF泛指各種使用者自訂的擴充,包括UDF、UDAF、UDTF、UDJ和UDT等。
特徵:某個Task執行效率低,且該Task中有使用者自訂的擴充。甚至是UDF的執行逾時報錯:
Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance。排查方法:任務報錯時,可以在Logview的Job Details頁簽中,快速通過DAG圖判斷報錯的Task中是否包含UDF。可以看到報錯的Task R4_3包含使用者使用Java語言編寫的UDF,如下圖所示。
 雙擊R4_3展開Operator視圖,可以看到該Task包含的所有UDF名稱,如下圖所示。
雙擊R4_3展開Operator視圖,可以看到該Task包含的所有UDF名稱,如下圖所示。 此外,在Task的StdOut日誌裡,UDF架構會列印UDF輸入的記錄數、輸出記錄數、以及處理時間,如下圖所示,通過這些資料可以看出UDF是否有效能問題。一般正常情況
此外,在Task的StdOut日誌裡,UDF架構會列印UDF輸入的記錄數、輸出記錄數、以及處理時間,如下圖所示,通過這些資料可以看出UDF是否有效能問題。一般正常情況Speed(records/s)在百萬或者十萬層級,如果降到萬層級,那麼基本上就存在效能問題了。
解決思路:當出現效能問題時,可以按照下述方法進行排查和最佳化:
檢查UDF是否出錯。
有時候是由於某些特定的資料值引起的,比如出現某個值的時候會引起死迴圈。 MaxCompute Studio支援下載表的部分Sample資料到本地運行,進行排查,詳情請參考MaxCompute Studio開發手冊:Java UDF、Python UDF 。
檢查UDF函數是否與內建函數同名。
內建函數是有可能被同名UDF覆蓋的,當看到一個函數像是內建函數時,需要確定是否有同名UDF覆蓋了內建函數。
使用內建函數代替UDF。
有相似功能的內建函數的情況下,儘可能不要使用UDF。內建函數一般經過驗證,實現比較高效,並且內建函數對最佳化器而言是白盒,能夠做更多的最佳化。更多內建函數的用法請參考官方文檔:內建函數。
將UDF函數進行功能拆分,部分使用內建函數替換,內建函數無法實現的再使用UDF。
最佳化UDF的evaluate方法。
evaluate中只做與參數相關的必要操作。因為evaluate方法會被反覆執行,所以儘可能將一些初始化的操作,或者一些重複計算事先計算好。
預估UDF的執行時間。
先在本地類比1個Instance處理的資料量測試UDF的已耗用時間,最佳化UDF的實現。預設UDF運行時限是30分鐘,也就是30分鐘內UDF必須要返回資料,或者用
context.progress()來報告心跳。如果UDF預計已耗用時間本身就大於30分鐘,可以通過參數設定UDF逾時時間:預設為1800秒。取值範圍為1s~3600s --設定UDF逾時時間,單位秒,預設為600秒 --可手動調整區間[0,3600]調整記憶體參數。
UDF效率低的原因並不一定是計算複雜度,有可能是受儲存複雜度影響。比如:
某些UDF在記憶體計算、排序的資料量比較大時,會報記憶體溢出錯誤。
記憶體不足引起GC頻率過高。
這時可以嘗試調整記憶體參數,不過此方法只能暫時緩解,具體的最佳化還是需要從業務上去處理。樣本如下:
set odps.sql.udf.jvm.memory= --設定UDF JVM Heap使用的最大記憶體,單位M,預設1024M --可手動調整區間[256,12288]說明目前如果使用了UDF可能會導致分區剪裁失效。從新版本開始,MaxCompute支援了
UdfProperty註解。UDF的作者在定義UDF時,可以指定這個註解,讓編譯器知道這個函數是確定性,如:@com.aliyun.odps.udf.annotation.UdfProperty(isDeterministic = true) public class AnnotatedUdf extends com.aliyun.odps.udf.UDF { public String evaluate(String x) { return x; } }改寫SQL語句為如下所示,就可以在分區過濾中使用UDF了。
--原來的寫法 SELECT * FROM t WHERE pt = udf('foo'); --pt 是 t 的一個分區列 --改成下面的樣子 SELECT * FROM t WHERE pt = (SELECT udf('foo')); --pt 是 t 的一個分區列
資料膨脹
特徵:Task的輸出資料量比輸入資料量大很多。比如1 GB的資料經過處理,變成了1 TB,在一個Instance下處理1 TB的資料,運行效率肯定會大大降低。作業運行完成後輸入輸出資料量體現在Task的I/O Records中,如果作業在Join階段長時間不結束,可以選擇幾個Running狀態的Fuxi Instance查看StdOut裡的日誌,如下圖所示:
 StdOut裡一直在列印Merge Join的日誌,說明對應的單個Worker一直執行Merge Join,紅框中Merge Join輸出的資料條數已經超過1433億條,有嚴重的資料膨脹,需要檢查JOIN條件和Join Key是否合理,如下圖所示:
StdOut裡一直在列印Merge Join的日誌,說明對應的單個Worker一直執行Merge Join,紅框中Merge Join輸出的資料條數已經超過1433億條,有嚴重的資料膨脹,需要檢查JOIN條件和Join Key是否合理,如下圖所示:
解決思路:
檢查代碼是否有誤:JOIN條件是否寫錯,是否寫成笛卡爾積了、UDTF是否正常,是否輸出過多資料。
檢查Aggregation引起的資料膨脹。
因為大多數Aggregator是recursive的,中間結果先做了一層Merge,中間結果不大,而且大多數Aggregator的計算複雜度比較低,即使資料量不小,也能較快完成。所以通常情況下這些操作問題不大,如以下兩種情況:
SELECT中使用Aggregation按照不同維度做DISTINCT,每一次DISTINCT都會使資料做一次膨脹。
使用GROUPING SETS 、CUBE | ROLLUP,中間資料可能會擴充很多倍。但是,有些操作如COLLECT_LIST、MEDIAN操作需要把全量中間資料都保留下來,可能會產生問題。
避免Join引起的資料膨脹。
例如:兩個表Join,左表是人口資料,資料量很大,但是由於並行度足夠,效率可觀。右表是個維表,記錄每種性別對應的一些資訊(比如每種性別可能的壞毛病),雖然只有兩種性別,但是每種都包含數百行。那麼如果直接按照性別來Join,可能會讓左表膨脹數百倍。要解決這個問題,可以考慮先將右表的行做彙總,變成兩行資料,這樣Join的結果就不會膨脹了。
由於Grouping Set導致的資料膨脹。Grouping Set操作會有一個擴充過程,輸出資料會按照Group數倍增。 目前的plan沒有能力適配Grouping Set並做下遊Task dop的調整,使用者可以手動設定下遊Task的dop。樣本如下:
set odps.stage.reducer.num = xxx; set odps.stage.joiner.num = xxx;
結束階段
大部分SQL作業在Fuxi作業結束後即停止。但有時Fuxi作業結束時,作業總體進度仍然處於運行狀態。如下圖中的Logview,右側Job Details頁面顯示Fuxi作業所有階段為Terminated,但左側代表作業整體進度的Status仍然顯示Running: 造成這種現象一般分為兩種情況:
造成這種現象一般分為兩種情況:
一個SQL作業可能包含多個Fuxi作業,比如子查詢存在多階段執行,作業輸出小檔案過多導致的自動合并作業。
SQL在結束階段運行於控制叢集的邏輯佔用時間較長,比如更新動態分區的中繼資料,下面將舉例介紹幾種典型。
子查詢多階段執行
大部分情況下,MaxCompute SQL的子查詢會被編譯進同一個Fuxi DAG,即所有子查詢和主查詢都通過一個Fuxi作業完成。但也有一些特殊子查詢需要先將子查詢單獨執行。如下樣本:
SELECT product, sum(price) FROM sales WHERE ds in (SELECT DISTINCT ds FROM t_ds_set) GROUP BY product;子查詢
SELECT DISTINCT ds FROM t_ds_set先執行,其結果需要被用來做分區裁剪,來最佳化主查詢需要讀取的分區數。這兩次運行分別是兩個Fuxi作業,Logview中體現的是兩個tab頁來顯示:第一個tab頁顯示job_0全部成功,實際上第二個tab頁的job_1作業還正在執行。如下圖所示: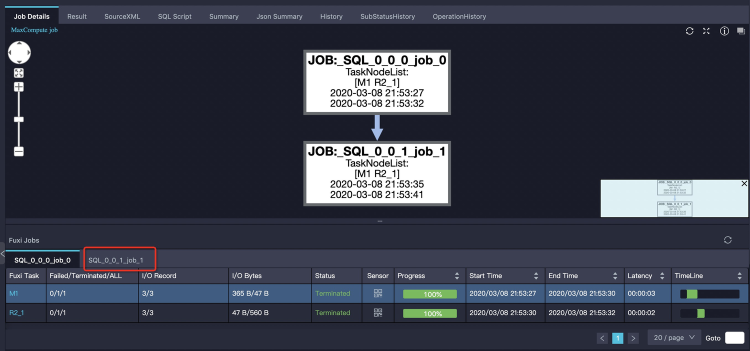 這時我們只需單擊第二個tab頁可以看到job_1的執行情況,如下圖所示:
這時我們只需單擊第二個tab頁可以看到job_1的執行情況,如下圖所示:
過多小檔案
小檔案主要帶來儲存和計算兩方面問題。
儲存方面:小檔案過多會給Pangu檔案系統帶來一定的壓力,且影響空間的有效利用。
計算方面:ODPS處理單個大檔案比處理多個小檔案效率高,小檔案過多會影響整體的計算執行效能。因此,為了避免系統產生過多小檔案,SQL作業在結束時會針對一定條件自動觸發合并小檔案的操作。
解決措施:通過Logview可以查看作業是否觸發了自動合并小檔案。與前面介紹過的子查詢多階段執行類似,Merge作業也是作為一個單獨的tab頁顯示,自動合并小檔案多出來的Merge Task,雖然會增加當前作業整體執行時間,但是會讓結果表在合并後產生的檔案數和檔案大小更合理,從而避免對檔案系統產生過大壓力,也使得表被後續的作業使用時,擁有更好的讀取效能。如下圖所示:

小檔案過多除了造成上文說的問題外,還會導致SELECT屏顯也在作業結束階段長時間運行。因為在匯聚屏顯結果時,需要開啟大量小檔案進行讀取,耗費大量時間在檔案操作上。對於這種情況,需要盡量避免使用SELECT語句造成屏顯數量巨大的結果,如果需要大批量返回結果應該使用Tunnel進行下載資料。另外如果結果實際不大,但是檔案數過多,那麼最好是先檢查前文所述的小檔案閾值配置是否正確。瞭解更多關於合并小檔案的知識,請查閱官方文檔:合并小檔案。
動態分區中繼資料更新
問題現象:Fuxi作業執行完後,可能還有一些中繼資料操作。比如要把結果資料挪到特定目錄去,然後更新表的中繼資料。有可能動態分區輸出了太多分區,也會消耗一定的時間。例如,對分區表sales使用
insert into ... values命令新增2000個分區,如下所示:INSERT INTO TABLE sales partition (ds)(ds, product, price) VALUES ('20170101','a',1),('20170102','b',2),('20170103','c',3), ...;Fuxi作業執行結束後,仍需要一段時間進行表的中繼資料更新。如下圖Logview的子狀態所示,可以看到作業卡在
SQLTask is updating meta information。
輸出檔案size變大
問題現象:在輸入輸出條數相差不大的情況,可能存在結果膨脹幾倍。

解決思路:一種情況是資料分布變化導致的,在向表中寫資料的過程中,會對資料進行壓縮,而壓縮演算法對於重複資料的壓縮率是最高的,所以在寫資料的過程中,如果相同的資料都排布在一起,就可以獲得很高的壓縮率。資料分布情況主要取決於資料寫入的階段(對應上圖的R12)是如何Shuffle和排序的,上圖給出的SQL最後的操作是JOIN,JOIN Key為如下代碼:
on t1.query = t2.query and t1.item_id=t2.item_id研究一下資料的特徵,大部分列都是item的屬性,即相同的
item_id其餘的列都完全相同,按照Query排序會把item完全打亂,導致壓縮率降低非常多。這裡調整JOIN順序為如下所示,調整後資料減少到原來的三分之一。on t1.item_id=t2.item_id and t1.query = t2.query調整後資料減少到原來的三分之一。
另一種情況,JOIN或者
group by產生的Shuffle都沒有包含對壓縮來說最理想的排序列,這時候也可以考慮使用Zorder的方式增加一個本地的排序,以較小的代價獲得較高的壓縮率。也可以單獨執行distributed by sort by命令,手動進行重排布,但是這樣計算的代價會比較大。