Hologres支援三種表格儲存體格式,分別為:行存、列存和行列共存,不同的儲存格式適用於不同的查詢情境,您需要根據表的使用情境設定表的儲存格式,合適的儲存格式可以顯著提高資料處理和查詢速度,同時也可以節省儲存空間。
設定儲存格式文法
在Hologres中支援行存、列存和行列共存三種儲存格式,在建表時通過設定orientation屬性指定表的儲存格式,文法如下:
-- 2.1版本起支援
CREATE TABLE <table_name> (...) WITH (orientation = '[column | row | row,column]');
-- 所有版本支援
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'orientation', '[column | row | row,column]');
COMMIT;table_name:表名稱。
orientation:指定了資料庫表在Hologres中的儲存模式是列存還是行存,Hologres從 V1.1版本開始支援行列共存的模式。
建表時預設為列存(column storage)形式。行存或行列共存需要在建表時顯式指定。修改表的儲存格式需要重建立表,不能直接轉換。
使用建議
表的儲存格式使用建議如下。
儲存格式 | 適用情境 | 列限制 | 使用說明 |
列存 | 適用於OLAP情境,適合各種複雜查詢、資料關聯、掃描、過濾和統計。 | 建議不超過300列。 | 列存會預設建立更多的索引,包括對字串類型建立bitmap索引,這些索引可以顯著加速查詢過濾和統計。 |
行存 | 適合基於Primary Key點查的情境,即查詢語句如下所示。 | 建議不超過3000列。 | 行存預設僅對主鍵建立索引,僅支援主鍵的快速查詢,使用情境也受到限制。 |
行列共存 | 支援行存和列存的所有情境,以及非主鍵點查的情境。 | 建議不超過300列。 | 行列共存適用的情境更廣,但會帶來更多的儲存開銷,以及內部資料狀態同步的開銷。 |
技術原理
列存
如果表是列存,那麼資料將會按照列的形式儲存。列存預設使用ORC格式,採用各種類型的Encoding演算法(如RLE、字典編碼等)對資料進行編碼,並且對編碼後的資料應用主流壓縮演算法(如Snappy、 Zlib、 Zstd、 Lz4等)對資料進一步進行壓縮,並結合Bitmap index、延遲物化等機制,提升資料的儲存和查詢效率。
系統會為每張表在底層儲存一個主鍵索引檔案,詳情請參見主鍵Primary Key。列存表如果設定了主鍵PK,系統會自動產生一個Row Identifier(RID),用於快速定位整行資料,同時如果為查詢的列設定合適的索引(如Distribution Key、Clustering Key等),那麼就可以通過索引快速定位到資料所在的分區和檔案,從而提升查詢效能,因此列存的適用範圍更廣,通常用於OLAP查詢的情境。樣本如下。
V2.1版本起支援的建表文法:
CREATE TABLE public.tbl_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, in_time TIMESTAMPTZ NOT NULL, PRIMARY KEY (id) ) WITH ( orientation = 'column', clustering_key = 'class', bitmap_columns = 'name', event_time_column = 'in_time' ); SELECT * FROM public.tbl_col WHERE id ='3333'; SELECT id, class,name FROM public.tbl_col WHERE id < '3333' ORDER BY id;所有版本支援的建表文法:
BEGIN; CREATE TABLE public.tbl_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, in_time TIMESTAMPTZ NOT NULL, PRIMARY KEY (id) ); CALL set_table_property('public.tbl_col', 'orientation', 'column'); CALL set_table_property('public.tbl_col', 'clustering_key', 'class'); CALL set_table_property('public.tbl_col', 'bitmap_columns', 'name'); CALL set_table_property('public.tbl_col', 'event_time_column', 'in_time'); COMMIT; SELECT * FROM public.tbl_col WHERE id ='3333'; SELECT id, class,name FROM public.tbl_col WHERE id < '3333' ORDER BY id;
示意圖如下。
行存
如果Hologres的表設定的是行存,那麼資料將會按照行儲存。行存預設使用SST格式,資料按照Key有序分塊壓縮儲存,並且通過Block Index、Bloom Filter等索引,以及後台Compaction機制對檔案進行整理,最佳化點查查詢效率。
(推薦)設定主鍵Primary Key
系統會為每張表在底層儲存一個主鍵索引檔案,詳情請參見主鍵Primary Key。行存表設定了Primary Key(PK)的情境,系統會自動產生一個Row Identifier(RID),RID用於定位整行資料,同時系統也會將PK設定為Distribution Key和Clustering Key,這樣就能快速定位到資料所在的Shard和檔案,在基於主鍵查詢的情境上,只需要掃描一個主鍵就能快速拿到所有列的全行資料,提升查詢效率,SQL樣本如下。
V2.1版本起支援的建表文法:
CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT, PRIMARY KEY (id) ) WITH ( orientation = 'row', clustering_key = 'id', distribution_key = 'id' ); --基於PK的點查樣本 SELECT * FROM public.tbl_row WHERE id ='1111'; --查詢多個key SELECT * FROM public.tbl_row WHERE id IN ('1111','2222','3333');所有版本支援的建表文法:
BEGIN; CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); CALL set_table_property('public.tbl_row', 'clustering_key', 'id'); CALL set_table_property('public.tbl_row', 'distribution_key', 'id'); COMMIT; --基於PK的點查樣本 SELECT * FROM public.tbl_row WHERE id ='1111'; --查詢多個key SELECT * FROM public.tbl_row WHERE id IN ('1111','2222','3333');
示意圖如下。

(不建議使用)設定的PK和Clustering Key不一致
但如果在建表時,設定表為行存表,且將PK和Clustering Key設定為不同的欄位,查詢時,系統會根據PK定位到Clustering Key和RID,再通過Clustering Key和RID快速定位到全行資料,相當於掃描了兩次,有一定的效能犧牲,SQL樣本如下。
V2.1版本起支援的建表文法,設定行存表,PK和Clustering Key不一致:
CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT, PRIMARY KEY (id) ) WITH ( orientation = 'row', clustering_key = 'name', distribution_key = 'id' );所有版本支援的建表文法,設定行存表,PK和Clustering Key不一致:
BEGIN; CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); CALL set_table_property('public.tbl_row', 'clustering_key', 'name'); CALL set_table_property('public.tbl_row', 'distribution_key', 'id'); COMMIT;
示意圖如下所示。
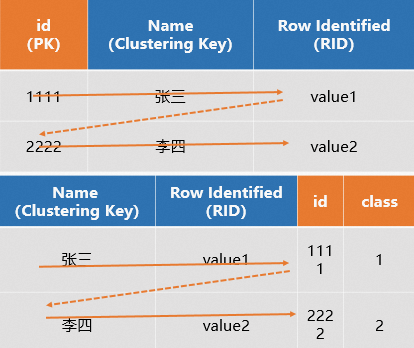
綜上:行存表非常適用於基於PK的點查情境,能夠實現高QPS的點查。同時建表時建議只設定PK,系統會自動將PK設定為Distribution Key和Clustering Key,以提升查詢效能。不建議將PK和Clustering Key設定為不同的欄位,設定為不同的欄位會有一定的效能犧牲。
行列共存
在實際應用情境中,一張表可能用於主鍵點查,又用於OLAP查詢,因此Hologres在V1.1版本支援了行列共存的儲存格式。行列共存同時擁有行存和列存的能力,既支援高效能的基於PK點查,又支援OLAP分析。資料在底層儲存時會儲存兩份,一份按照行存格式儲存,一份按照列存格式儲存,因此會帶來更多的儲存開銷。
資料寫入時,會同時寫一份行存格式和寫一份列存格式,只有兩份資料都寫完了才會返回成功,保證資料的原子性。
資料查詢時,最佳化器會根據SQL,解析出對應的執行計畫,執行引擎會根據執行計畫判斷走行存還是列存的查詢效率更高,要求行列共存的表必須設定主鍵:
對於主鍵點查情境(如
select * from tbl where pk=xxx語句)以及Fixed Plan加速SQL執行情境,最佳化器會預設走行存主鍵點查的路徑。對於非主鍵點查情境(如
select * from tbl where col1=xx and col2=yyy語句),尤其是表的列很多,且查詢結果需要展示很多列,行列共存針對該情境,最佳化器在產生執行計畫時,會先讀取列存表的資料,讀取完成後根據列存索引值Key查詢行存表的資料,避免全表掃描,提升非主鍵查詢效能。該情境能充分發揮行列共存的優勢,提高資料的快速檢索效能。對於其他的普通查詢,則會預設走列存。
因此行列共存表在通常查詢情境,尤其是非主鍵點查情境,查詢效率更好,樣本如下。
V2.1版本起支援的建表文法:
CREATE TABLE public.tbl_row_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, PRIMARY KEY (id) ) WITH ( orientation = 'row,column', distribution_key = 'id', clustering_key = 'class', bitmap_columns = 'name' ); SELECT * FROM public.tbl_row_col WHERE id =‘2222’; --基於主鍵的點查 SELECT * FROM public.tbl_row_col WHERE class=‘二班’;--非主鍵點查 SELECT * FROM public.tbl_row_col WHERE id =‘2222’ AND class=‘二班’; --普通OLAP查所有版本支援的建表文法:
BEGIN; CREATE TABLE public.tbl_row_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row_col', 'orientation','row,column'); CALL set_table_property('public.tbl_row_col', 'distribution_key','id'); CALL set_table_property('public.tbl_row_col', 'clustering_key','class'); CALL set_table_property('public.tbl_row_col', 'bitmap_columns','name'); COMMIT; SELECT * FROM public.tbl_row_col WHERE id =‘2222’; --基於主鍵的點查 SELECT * FROM public.tbl_row_col WHERE class=‘二班’;--非主鍵點查 SELECT * FROM public.tbl_row_col WHERE id =‘2222’ AND class=‘二班’; --普通OLAP查
示意圖如下。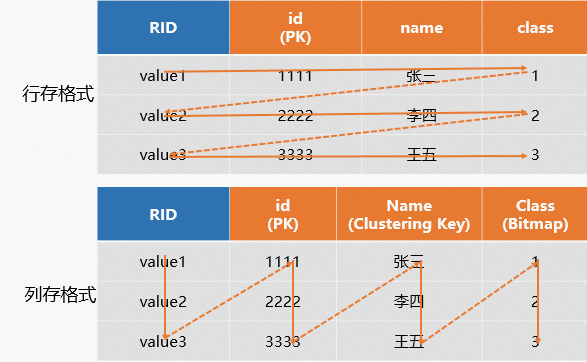
使用樣本
建立不同儲存模式的表使用樣本如下。
V2.1版本起支援的建表文法:
--建行存表 CREATE TABLE public.tbl_row ( a INTEGER NOT NULL, b TEXT NOT NULL, PRIMARY KEY (a) ) WITH ( orientation = 'row' ); --建列存表 CREATE TABLE tbl_col ( a INT NOT NULL, b TEXT NOT NULL ) WITH ( orientation = 'column' ); --建行列共存 CREATE TABLE tbl_col_row ( pk TEXT NOT NULL, col1 TEXT, col2 TEXT, col3 TEXT, PRIMARY KEY (pk) ) WITH ( orientation = 'row,column' );所有版本支援的建表文法:
--建行存表 BEGIN; CREATE TABLE public.tbl_row ( a INTEGER NOT NULL, b TEXT NOT NULL, PRIMARY KEY (a) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); COMMIT; --建列存表 BEGIN; CREATE TABLE tbl_col ( a INT NOT NULL, b TEXT NOT NULL); CALL set_table_property('tbl_col', 'orientation', 'column'); COMMIT; --建行列共存 BEGIN; CREATE TABLE tbl_col_row ( pk TEXT NOT NULL, col1 TEXT, col2 TEXT, col3 TEXT, PRIMARY KEY (pk)); CALL set_table_property('tbl_col_row', 'orientation', 'row,column'); COMMIT;
相關文檔
根據業務查詢情境設定合適的表屬性指南請參見情境化建表調優指南。