INSERT語句用於插入新的行資料至表中。本文為您介紹在即時數倉Hologres中如何使用INSERT插入資料。
命令介紹
您可以插入一個或多個由運算式指定的行,以及插入來自一個查詢的零行或多行資料至Hologres。語句如下。
INSERT INTO <schema>.<table> [( <column> [, ...] )]
VALUES ( {<expression>} [, ...] )
[, ...] | <query>}參數說明如下。
參數 | 描述 |
schema | 表所在的Schema名稱。 |
table | 已建立的表名稱。 通過Flink寫入時可以插入父表並自動路由到子表。從Hologres V1.3版本起,支援符合FixedPlan的Insert語句直接寫入分區表父表,詳情請參見Fixed Plan加速SQL執行。 |
column | table表中的某個列的名稱。 您也可以使用子網域名稱或者數組下標限定列名稱。(指向一個組合列的某些列中插入會讓其他域為空白)。 |
expression | 賦予相應列的運算式或值。 |
query | 需要被插入行的SELECT查詢語句。 文法詳情請參見SELECT語句。 |
目前INSERT只支援以下兩種資料寫入方式:
insert into values:INSERT INTO holo2mysqltest (cate_id, cate_name) VALUES (3, 'true'), (3, 'fale'), (3, 'trxxue'), (3, 'x'), (4, 'The Dinner Game');insert into select:
INSERT INTO test2 SELECT * FROM test1;
技術原理
Hologres表的儲存結構分為行存、列存和行列共存,但三者的寫入原理一致。
如下圖所示,INSERT是以Append Only的方式寫入WAL,並即時更新到記憶體表(MemTable),保證資料即時可見。但Mem Table有一定的大小,寫滿了之後會切換新的MemTable,並觸發背景非同步Flush過程,將其中的資料逐漸Flush到檔案中,檔案儲存體在Pangu中。在Flush的過程中會產生很多小檔案,後台會將這些小檔案做合并和整理,即Compaction。為了寫速度儘可能的快,後台會先將資料寫完,待非同步Compaction時再執行壓縮和整理,因此會看到在資料寫入過程中,資料的儲存會一定的膨脹,等資料寫入之後,Compaction完成後儲存會下降。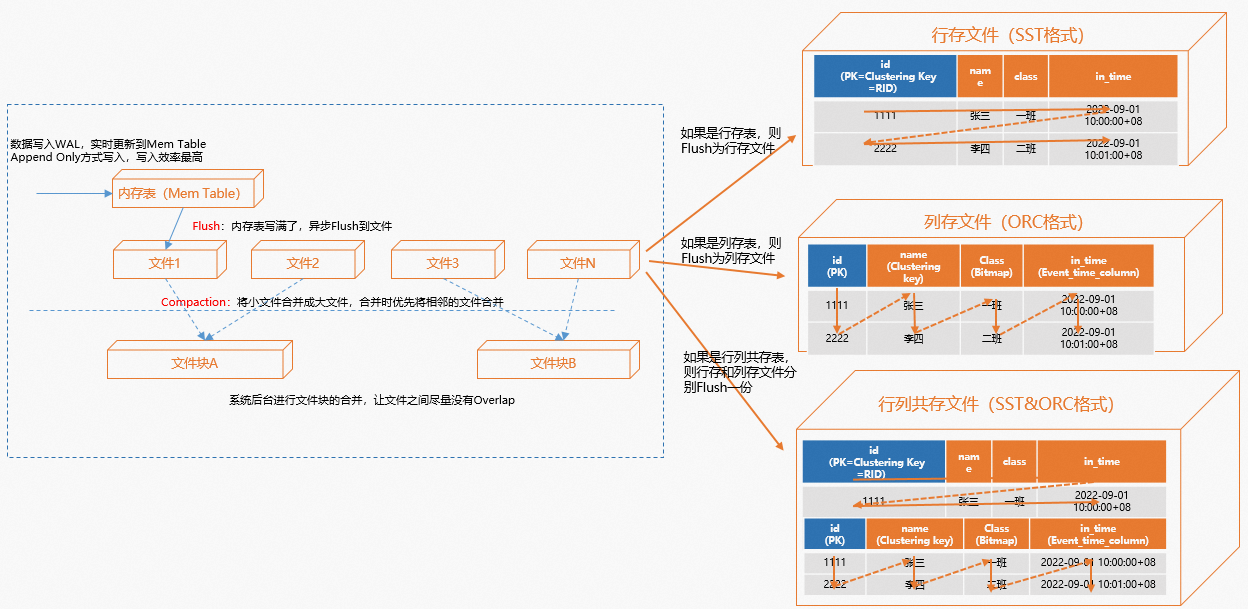
對於行存、列存、行列共存表的區別一方面是記憶體的Mem Table的索引格式不同,另外一方面在Flush到檔案的過程中:
行存表:會Flush成行儲存的檔案,即SST格式。
列存表:會Flush成列存檔案,即ORC格式。
行列共存表:會分別Flush為行存和列存兩種檔案,SST和ORC格式,在Flush過程中會保證資料的一致性,只有行存、列存都同時Flush完成才會返回成功,同時在儲存上行列共存相當於是兩份儲存,因此行列共存的表在儲存上會有一定的犧牲。
使用限制
若是分區表,必須插入具體的子表,不能插入分區父表,且插入時,對應的分區欄位值要和子表分區欄位值一致。
目標列的名稱可以以任意順序列出。如果使用
insert into select的方式插入資料,目標列和查詢列類型需要一一對齊。
使用樣本
Hologres從V2.1.17版本起支援Serverless Computing能力,針對巨量資料量離線匯入、大型ETL作業、外表巨量資料量查詢等情境,使用Serverless Computing執行該類任務可以直接使用額外的Serverless資源,避免使用執行個體自身資源,無需為執行個體預留額外的計算資源,顯著提升執行個體穩定性、減少OOM機率,且僅需為任務單獨付費。Serverless Computing詳情請參見Serverless Computing概述,Serverless Computing使用方法請參見Serverless Computing使用指南。
插入普通表。
CREATE TABLE holotest ( a int, b bigint, c bool, e decimal(38,10), f text, g timestamp, h timestamptz, i jsonb, j int[] ); -- (可選)推薦使用Serverless Computing執行巨量資料量離線匯入和ETL作業 SET hg_computing_resource = 'serverless'; -- 匯入資料 INSERT INTO holotest VALUES (1,9223372036854775807,false,123.123456789123,'john','2020-01-01 01:01:01.123456', '2004-10-19 10:23:54+08','{"a":2}',ARRAY[1, 2, 3, 4]); -- 重設配置,保證非必要的SQL不會使用serverless資源。 RESET hg_computing_resource;從a表插入資料至b表。
CREATE TABLE holotest2( a int, b bigint, c bool); -- (可選)推薦使用Serverless Computing執行巨量資料量離線匯入和ETL作業 SET hg_computing_resource = 'serverless'; -- 匯入資料 INSERT INTO holotest2 (a,b,c) SELECT a,b,c FROM holotest; -- 重設配置,保證非必要的SQL不會使用serverless資源。 RESET hg_computing_resource;插入分區表資料。
--樣本:在public schema下建立不帶主鍵的分區父表和對應的分區子表 BEGIN; CREATE TABLE public.hologres_parent( a text, b int, c timestamp, d text ) PARTITION BY list(a); CALL set_table_property('public.hologres_parent', 'orientation', 'column'); CREATE TABLE public.hologres_2022 partition of public.hologres_parent for values in('2022'); CREATE TABLE public.hologres_2021 partition of public.hologres_parent for values in('2021'); CREATE TABLE public.hologres_2020 partition of public.hologres_parent for values in('2020'); COMMIT; -- (可選)推薦使用Serverless Computing執行巨量資料量離線匯入和ETL作業 SET hg_computing_resource = 'serverless'; --插入分區子表 INSERT INTO public.hologres_2022 values('2022',1,now(),'a') -- 重設配置,保證非必要的SQL不會使用serverless資源。 RESET hg_computing_resource;
常見問題
問題一:巨量資料量寫入時,執行個體CPU和記憶體資源使用率100%,影響執行個體其他寫入與查詢任務。
建議使用Serverless Computing能力執行巨量資料量寫入任務。
說明Hologres從V2.1.17版本起支援Serverless Computing能力,針對巨量資料量離線匯入、大型ETL作業、外表巨量資料量查詢等情境,使用Serverless Computing執行該類任務可以直接使用額外的Serverless資源,避免使用執行個體自身資源,無需為執行個體預留額外的計算資源,顯著提升執行個體穩定性、減少OOM機率,且僅需為任務單獨付費。Serverless Computing詳情請參見Serverless Computing概述,Serverless Computing使用方法請參見Serverless Computing使用指南。
問題二:資料在寫入時,為什麼監控指標中儲存用量上漲非常多,寫入完成後儲存用量又下降?
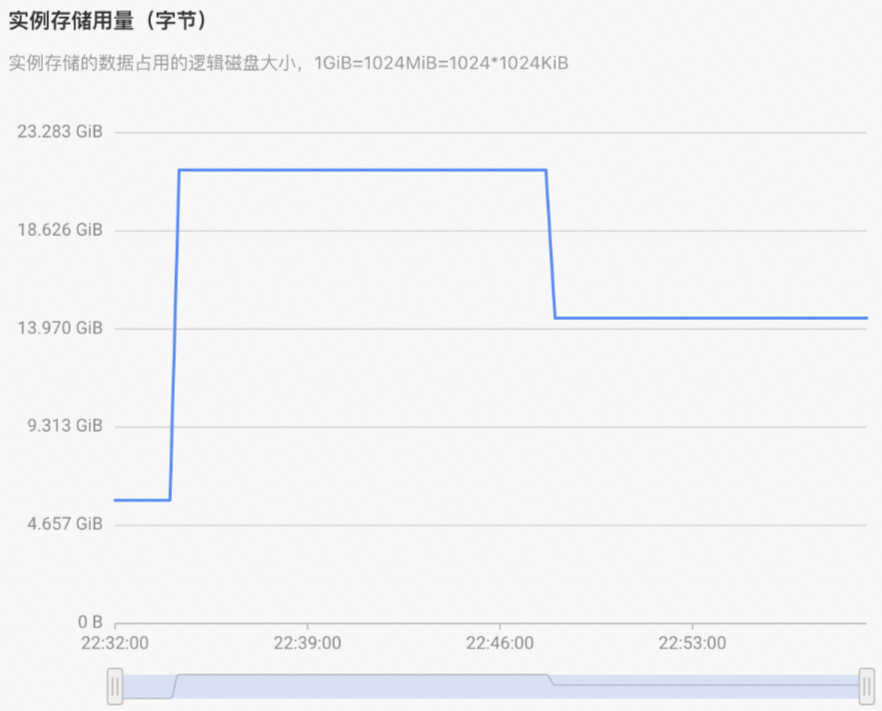
根據寫入的技術原理,為了儘可能快地寫入資料,後台會先將資料寫完,待非同步Compaction時再執行壓縮和整理,因此會看到在資料寫入過程中,資料的儲存會一定的膨脹,等資料寫入之後,Compaction完成後儲存會下降。
問題三:同一張表並存執行
insert命令時,延遲增加。沒有走Fixed Plan的
insert是表鎖,並存執行insert會導致等鎖時間增加,從而造成延遲增加。問題四:資料寫入分區父表報錯:
ERROR: no partition of relation "<table_name>" found for row。報錯資訊:
ERROR: no partition of relation "<table_name>" found for row。問題原因:分區子表不存在。
解決方案:寫入資料前,需建立對應的分區子表,命令樣本如下。
CREATE TABLE <child_table_name> partition of <parent_table_name> for values in (<value>);
問題五:在匯入資料的時候報錯:
Currently inserting into parent table is not supported。報錯資訊:匯入資料時報錯:
Currently inserting into parent table is not supported。問題原因:當前Insert的表,是一張分區父表,Hologres不支援直接寫入分區父表。
解決方案:需要寫入對應的分區子表。