本文將為您介紹如何使用Analyze命令,以及更加簡單的Auto Analyze的相關機制。
Analyze
統計資訊決定是否能夠產生正確的執行計畫。Hologres需要收集資料的採樣統計資訊,包括資料的分布和特徵、表的統計資訊、列的統計資訊、行數、列數、欄位寬度、基數、頻度、最大值、最小值、高頻值、分桶分布特徵等資訊。這些資訊將為最佳化器更新運算元執行預估COST、搜尋空間裁剪、估算最優JOIN ORDER、估算記憶體開銷、估算並行度,從而產生更優的執行計畫。
Analyze命令用於收集資料庫中表內容的統計資訊,最佳化器會根據這些統計資訊產生最佳的查詢計劃,從而提高查詢效率。
使用文法
-- 更新某個表的統計資訊,預設會收集表中所有列的統計資訊 analyze <tablename>; -- 更新某個列的統計資訊,會比更新表時採樣的資料更多,更精準,主要用於更新管理條件的列 analyze <tablename>(<colname>, <colname>);參數說明
tablename為更新統計資料的表名稱,colname為更新統計資料的列名稱。
文法說明
兩個Analyze命令的說明如下。
相同點
對列統一收集包括行數、列寬、列的最常用值(Most Common Values)、列的長條圖(Histogram)資訊,列的非重複值的個數(Number of Distinct Value,NDV)在內的資訊。
兩個命令都會相互覆蓋指定列的統計資訊,但不會覆蓋其他列的資訊。例如
analyze <tablename>(<colname1>);命令會覆蓋(更新)之前colname1列收集的統計資訊,但並不會改變colname2列的統計資訊。
不同點
analyze <tablename>;基於採樣資料,計算得出統計資訊。analyze <tablename>(<colname>, <colname>);會對列的Number of Distinct Value(NDV)進行APPROX_COUNT_DISTINCT計算,在很多情況下,這樣計算的值相比採樣更準確,但開銷比採樣表更大,因此只適合對重點列進行指定ANALYZE。NDV以外的Histogram、Width等資訊,仍然通過採樣得到。
因此對於具有兩列的
table (colname1, colname2),analyze table;不完全等價於analyze table(colname1, colname2);。對於常用的Join列、Group By列,推薦使用
analyze <tablename>(<colname>, <colname>);命令進行額外的統計資訊收集。
需要執行Analyze的情況
推薦您在如下情況下運行
analyze <tablename>;命令。在表執行大量的INSERT、UPDATE以及DELETE操作之後,包括匯入資料。
在效能下降的情況下,多表Join查詢之前,對Join的列、Group by的列進行Analyze。
執行
CREATE FOREIGN TABLE命令後,通過Analyze收集當前外部表格統計資訊。執行
IMPORT FOREIGN SCHEMA後,對後續需要查詢的表進行Analyze。執行
CREATE EXTERNAL DATABASE後,通過Analyze收集當前外部表格統計資訊。
注意事項
在Hologres V0.10和V1.1版本中,如果有對父表的查詢,需要Analyze分區父表;如果直接對子表查詢,請對子表Analyze;如果兩者都有,建議兩者都進行Analyze,否則可能會有缺失統計資訊的情況。
如果遇到以下問題,您需要先執行Analyze,再運行匯入任務,可以系統地提升效率。
多表JOIN超出記憶體OOM:通常會產生
Query executor exceeded total memory limitation xxxxx: yyyy bytes used報錯。匯入效率較低:在Hologres查詢或匯入資料時,效率較低,啟動並執行任務長時間不結束。
如果有超寬列(例如Bitmap等Bytea資料,超過1KB的Text資料等),這些超寬列的統計資訊沒有作用,還會使採樣更消耗記憶體。因此對於具有上述超寬列的表,盡量避免執行
analyze <tablename>;命令,而是採用analyze <tablename>(<colname>, <colname>);避開超寬列,轉為Analyze必要的列(例如上面推薦的Join的列、Group by的列和Filter列等)。說明1KB是經驗值,寬度標準可以根據業務情況自行決定。
Auto Analyze
為了減少重複、手動的Analyze,從Hologres V0.10版本開始,支援Auto Analyze機制。開啟auto analyze後,系統會根據使用者的建表、資料寫入和修改情況等來判斷是否需要對相關的表在後台自動Analyze,無需再手動對錶進行Analyze,降低操作複雜度,同時減少遺漏Analyze而導致缺失統計資訊的情況。
使用文法
查看是否開啟Auto Analyze
SHOW hg_enable_start_auto_analyze_worker; -- V1.1及以上版本文法,查看當前開啟/關閉狀態 SHOW hg_experimental_enable_start_auto_analyze_worker; -- V0.10文法,查看當前開啟/關閉狀態開啟/關閉文法如下,需要Superuser執行。
-- DB層級,執行後整個DB生效,V1.1及以上版本開啟/關閉文法 ALTER DATABASE dbname SET hg_enable_start_auto_analyze_worker = ON; -- 開啟(預設) ALTER DATABASE dbname SET hg_enable_start_auto_analyze_worker = OFF; -- 關閉 -- DB層級,執行後整個DB生效,V0.10開啟/關閉文法 ALTER DATABASE dbname SET hg_experimental_enable_start_auto_analyze_worker = ON; -- 開啟(預設) ALTER DATABASE dbname SET hg_experimental_enable_start_auto_analyze_worker = OFF; -- 關閉 -- DB層級,對External Database開啟Auto Analyze ALTER EXTERNAL DATABASE dbname WITH enable_auto_analyze 'true';
使用限制
在Hologres中使用Auto Analyze,具體限制如下:
Auto Analyze功能僅Hologres V0.10及以上版本支援,請在Hologres管理主控台的執行個體詳情頁查看目前的版本,如果您的執行個體是V0.10以下版本,請您使用常見升級準備失敗報錯或加入HologresDingTalk交流群反饋,詳情請參見如何擷取更多的線上支援?。
僅支援Superuser執行開啟或關閉Auto Analyze操作。
Auto Analyze對分區表的限制如下。
分區子表發生改變,需要Auto Analyze時,會統一Analyze其父表。
分區表有掃描行數限制,採樣資料時預設掃描的最大記錄數是224條(16,777,216條),即若所有分區子表的記錄數總和超過16,777,216條,會做一定的分區裁剪,只對其中若干分區(總和不超過16,777,216條)進行採樣。
說明分區列統計資訊總是全的,不受裁剪影響,但是這可能會影響與分區列同分布的列(例如極端情況是,與分區列資料一樣的列)的統計資訊,即一部分值採樣不到,行數估計可能不準確。如果有需求可以搜尋(DingTalk群號:32314975)加入即時數倉Hologres交流群聯絡支援人員,技術側根據執行個體情況評估調整掃描的最大記錄數。
Auto Analyze預設最大收集256列的統計資訊,如表超過256列,取前256列。可通過調整
hg_experimental_auto_analyze_max_columns_count改變此值。Auto Analyze預設單個Worker限制的記憶體是4 GB,如果存在超寬的列,採樣可能超出記憶體而導致Analyze失敗。可調整
auto_analyze_work_memory_mb參數改變其大小,但是要注意對系統記憶體的影響。執行個體規格越大,Worker數越多,Auto Analyze可用記憶體限制越大。僅Hologres V3.1.0版本起,支援使用Analyze和Auto Analyze對External Database下的外部表格收集統計資訊。
不支援對HMS外部表格執行Analyze和Auto Analyze。
Auto Analyze工作原理
當開始Auto Analyze後,系統後台會定期巡檢是否有表需要執行Analyze。
普通表(內部表,包括單表和分區表)
每隔1分鐘巡檢是否有表的最新動作(主要是INSERT、UPDATE、DELETE等DML操作,可能改變了資料量)。滿足以下條件,系統後台觸發表的Analyze,收集表的統計資訊。
表有DML執行完成且資料條數變化超過當前表的資料條數的10%。若表是分區子表,則是指變化條數超過此分區資料條數的10%。
TRUNCATE TABLE清空表。
表的DDL發生變更。例如CREATE TABLE建立表,ALTER TABLE修改表結構等,不包括CALL SET_TABLE_PROPERTY修改表屬性。
每隔10分鐘檢測所有內部表的資料變化,如果滿足資料條數變化超過上一次檢測的10%,則後台觸發該表的Analyze。
說明這一步驟是為了檢測到非顯式DML(例如通過Flink、Data Integration、HoloClient即時寫入)更新的資料。
外部表格
每隔4小時定期巡檢外部表格中繼資料或資料變化情況。滿足以下條件,系統後台觸發表的Analyze,收集統計資訊。
外部表格對應的外部系統的表(例如MaxCompute外部表格和DLF外部表格)在兩次巡檢間隔(例如4小時內)改變過,改變的標準是對應MaxCompute表的
last_modify_time處於巡檢間隔之間。
說明巡檢和執行在同一個調度任務中,所以下一次巡檢調度開始依賴Analyze執行結束,只要離上一次開始巡檢的時間滿足調度周期,就可以進入下一次巡檢。
配置參數
開啟Auto Analyze後,系統預設會自動周期性巡檢,決定需要執行Analyze的表,並進行採樣計算,收集統計資訊,對系統資源有一定的消耗。
在某些業務情境下,預設的機制可能不適用於業務情境,例如資料寫入更新不頻繁情境,可以通過修改預設參數來減少自動Analyze的頻率。諸如此類可以根據業務情況更改預設參數,以此達到部分效能調優的目的。
說明只有Superuser能調整Auto Analyze的預設行為,且都需要資料庫層級設定參數,且在下一分鐘後生效。
使用文法
--Superuser修改Auto Analyze參數的預設值 ALTER DATABASE <dbname> SET <GUC>=<values>;dbname為資料庫名稱;GUC為參數名稱;values為參數值。
參數列表
參數
參數描述
支援版本
預設值
使用樣本
autovacuum_naptime
巡檢是否有表的最新動作的周期,單位是秒(s)。
V1.1.0及以上版本
說明需後台調整,如需調整請搜尋(DingTalk群號:32314975)加入即時數倉Hologres交流群申請。
60s
ALTER DATABASE <dbname> SET autovacuum_naptime = 60;ALTER DATABASE <dbname> SET autovacuum_naptime = '60s';ALTER DATABASE <dbname> SET autovacuum_naptime = '10min';
hg_auto_check_table_changes_interval
檢查所有內部表的資料變化的周期,單位是秒(s)。
V1.1.0及以上版本
600s(10min)
--V1.1及以上版本命令文法 ALTER DATABASE <dbname> SET hg_auto_check_table_changes_interval = '600s'; --V0.10版本命令文法 ALTER DATABASE <dbname> SET hg_experimental_auto_check_table_changes_interval = '600s';hg_auto_check_foreign_table_changes_interval
檢查所有外部表格的資料變化的周期,單位是秒(s)。
V1.1.0及以上版本
14400s(4小時)
--V1.1及以上版本命令文法 ALTER DATABASE <dbname> SET hg_auto_check_foreign_table_changes_interval = '14400s'; --V0.10版本命令文法 ALTER DATABASE <dbname> SET hg_experimental_auto_check_foreign_table_changes_interval = '14400s';hg_experimental_auto_analyze_max_columns_count
自動收集統計資訊的列數,單位是個。
V1.1.0及以上版本
256個
ALTER DATABASE <dbname> SET hg_experimental_auto_analyze_max_columns_count =300;auto_analyze_work_memory_mb
Auto Analyze單個表的記憶體限制,單位是MB。
V1.1.54及以上版本
預設單個Worker 4096 MB,即4GB,執行個體規格越大,Worker越多,真實記憶體限制越大。
Auto Analyze單個表的記憶體限制修改為9GB。
ALTER DATABASE <dbname> SETauto_analyze_work_memory_mb =9216;hg_experimental_auto_analyze_start_time
Auto-Analyze在每天啟動並執行開始時間
說明需要與end_time是同一時區,並且start time要小於等於end_time。
V1.1.54及以上版本
00:00 +0800
修改為僅需要在0~6點執行Auto-Analyze,白天內外部表格資料不變,無需Analyze的情況。
ALTER DATABASE <dbname> SET hg_experimental_auto_analyze_start_time = '00:00 +0800';ALTER DATABASE <dbname> SET hg_experimental_auto_analyze_end_time = '06:00 +0800';
hg_experimental_auto_analyze_end_time
Auto Analyze在每天啟動並執行結束時間。
V1.1.54及以上版本
23:59 +0800
autovacuum_enabled
表Auto Analyze的開啟狀態。
V1.1.54及以上版本
true,即預設全部開啟。
關閉某表的Auto Analyze,以後Analyze將跳過此表。
說明僅支援使用如下命令為Hologres內部表關閉Auto Analyze。
ALTER TABLE <tablename> SET (autovacuum_enabled = false);
其他最佳化
自Hologres V3.1版本開始,新增了Fast Rows功能,即當Hologres發現執行查詢的SQL中表缺少統計資訊時,會直接通過儲存引擎擷取該表的行數,擷取行數的COST在10 ms左右。命令如下。
-- DB層級,執行後整個DB生效,開啟文法
ALTER DATABASE dbname SET hg_experimental_get_fast_num_of_rows = ON; -- 開啟(預設關閉)
-- DB層級,執行後整個DB生效,開啟文法
ALTER DATABASE dbname SET hg_experimental_get_fast_num_of_rows = OFF; -- 關閉(預設關閉)當未開啟Fast Rows功能,在以下情況下,可有效減少計劃不正確的機率。
若表沒有統計資訊,在查看查詢計劃時rows=1000行(表示沒有統計資訊,根據1000行預估產生計劃)。
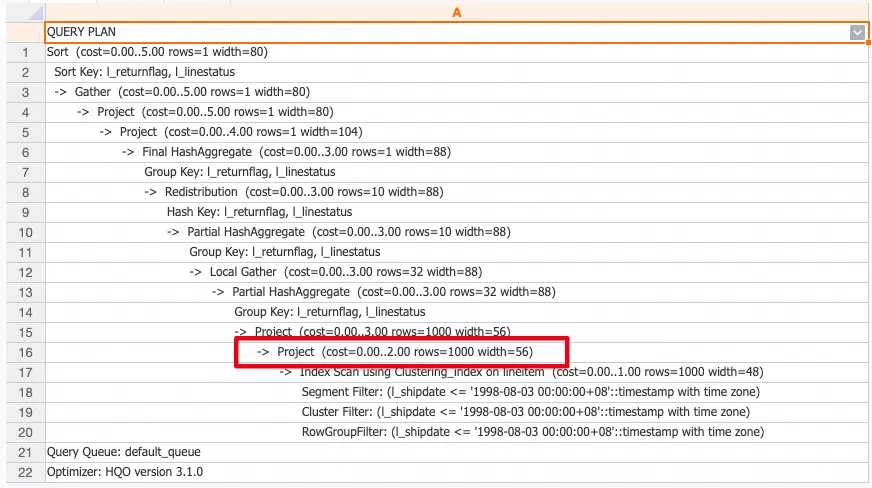
當開啟Fast Rows功能且表沒有統計資訊,查看查詢計劃時rows不等於1000行(系統調用了儲存引擎的結果,擷取了表的行數)。
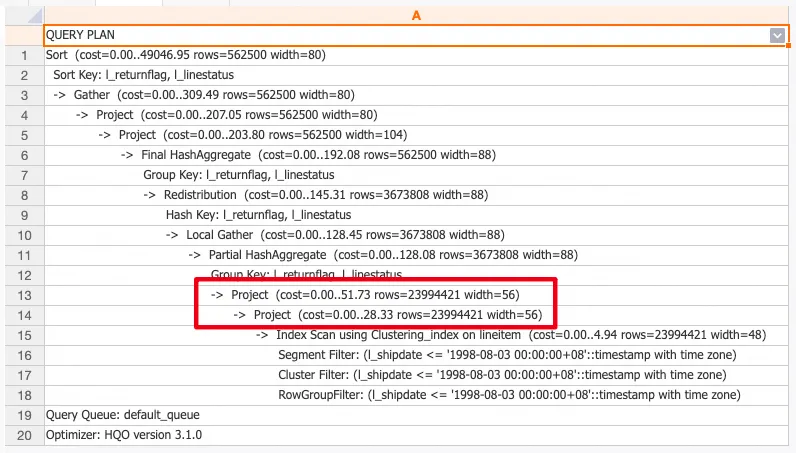
查詢統計資訊
表的統計資訊被記錄在hologres_statistic.hg_table_statistic表中,可以通過檢查該表資訊瞭解Analyze的狀態,命令如下。
如果需要查最近一次Analyze的資訊,根據analyze_timestamp排序即可。
SELECT schema_name, -- 表的Schema
table_name, -- 表名稱
schema_version, -- 表的版本
statistic_version, -- 最近一次ANALYZE的統計資訊版本
total_rows, -- 最近一次ANALYZE的行數
analyze_timestamp -- 最近一次ANALYZE的結束時間
FROM hologres_statistic.hg_table_statistic
WHERE table_name = '<tablename>'
ORDER BY analyze_timestamp DESC;每個表在hologres_statistic.hg_table_statistic表中有
0~n條記錄。0條表示從未進行過Analyze,1條及以上表示運行過Analyze。若出現兩條及以上的情況,兩條記錄的schema_version一定不一樣,因為表的Schema變化了(例如執行
ADD COLUMN等命令會產生新的版本),會增加一條統計資訊記錄,老的schema_version對應的記錄不再被使用。樣本查詢結果如下,同一個表有兩條記錄,而第二條記錄的schema_version低於第一條,那麼第二條將作廢,不會被使用,也無需關注。
schema_name | table_name | schema_version | statistic_version | total_rows | analyze_timestamp -------------+------------------+----------------+-------------------+------------+--------------------- public | tbl_name_example | 13 | 8580 | 10002 | 2022-04-29 16:03:18 public | tbl_name_example | 10 | 8576 | 10002 | 2022-04-29 15:41:20 (2 rows)Hologres V0.10和V1.1版本暫不會清理hg_table_statistic表中的歷史到期記錄,同時不用關心老的資料。
查看缺失統計資訊的表
通過HG_STATS_MISSING視圖,可以查看當前資料庫中缺失統計資訊的表,詳情請參見HG_STATS_MISSING View。
常見問題
出現如下情況,代表Auto Analyze工作未正常,請參照解決方案進行處理。
表的統計資訊是0條
問題現象:通過hologres_statistic.hg_table_statistic表查看錶的統計資訊,沒有資料。
可能原因:
Auto Analyze沒有工作,或者該表不符合Auto Analyze觸發條件。
Auto Analyze本身的問題導致,需要提交工單具體排查原因。
解決方案:手動觸發一次Analyze。
analyze_timestamp過小問題現象:查詢結果中
analyze_timestamp過小(即比目前時間小很多),代表長時間沒有進行過Analyze。可能原因:
某種原因未能正常執行Auto Analyze。
手動關閉過Auto Analyze。
解決方案:先手動觸發Analyze,再提交工單排查原因。