Hologres中的向量計算功能可以應用於相似性搜尋、映像檢索、情境識別等多種情境。通過靈活應用向量計算,可以提升資料處理和分析的效果,並實現更精準的搜尋和推薦功能。本文為您介紹在Hologres中使用Proxima進行向量計算的方法及完整樣本。
操作步驟
串連Hologres。
通過開發工具串連Hologres,詳情請參見串連開發工具。如果是JDBC串連,請使用Prepare Statement模式。
安裝Proxima外掛程式。
Proxima是以一個Extension的方式與Hologres連通,因此在使用之前需要Superuser執行如下命令安裝Proxima外掛程式。
--安裝Proxima外掛程式 CREATE EXTENSION proxima;Proxima外掛程式是針對資料庫層級使用的,一個資料庫僅需要安裝一次即可,如需卸載Extension請執行如下命令。
DROP EXTENSION proxima;重要不推薦使用
DROP EXTENSION <extension_name> CASCADE;命令級聯卸載Extension。CASCADE(級聯)刪除命令不僅會刪除指定擴充本身,還會一併清除擴充資料(例如PostGIS資料、RoaringBitmap資料、Proxima資料、Binlog資料、BSI資料等)以及依賴該擴充的對象(包括中繼資料、表、視圖、Server資料等)。建立向量表和向量索引。
向量在Hologres中一般用FLOAT4數組表示,建立向量表的文法如下。
說明僅列存、行列共存表支援向量索引,行存表不支援。
定義向量時,數組維度僅支援定義為
1,即array_ndims、array_length的第二入參都必須設定為1。Hologres V2.0.11版本起,支援先匯入資料、再建立向量索引,無需對compaction過程中的檔案構建向量索引,縮短索引建立時間。
先建立向量索引、再匯入資料:適用於即時資料情境。
--設定單個索引 BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) --定義向量 ); CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); --構建向量索引 COMMIT; --設定多個索引 BEGIN; CREATE TABLE t1 ( f1 INT PRIMARY KEY, f2 FLOAT4[] NOT NULL CHECK(array_ndims(f2) = 1 AND array_length(f2, 1) = 4), f3 FLOAT4[] NOT NULL CHECK(array_ndims(f3) = 1 AND array_length(f3, 1) = 4) ); CALL set_table_property( 't1', 'proxima_vectors', '{"f2":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}, "f3":{"algorithm":"Graph", "distance_method":"InnerProduct", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT;先匯入資料、再建立向量索引:適用於離線分析情境。
說明Hologres從V2.1.17版本起支援Serverless Computing能力,針對巨量資料量向量離線匯入、巨量資料量向量查詢等情境,使用Serverless Computing執行該類任務可以直接使用額外的Serverless資源,避免使用執行個體自身資源,無需為執行個體預留額外的計算資源,顯著提升執行個體穩定性、減少OOM機率,且僅需為任務單獨付費。Serverless Computing詳情請參見Serverless Computing,Serverless Computing使用方法請參見Serverless Computing使用指南。
--設定單個索引 BEGIN; CREATE TABLE feature_tb ( id BIGINT, feature_col FLOAT4[] CHECK(array_ndims(feature_col) = 1 AND array_length(feature_col, 1) = <value>) --定義向量 ); COMMIT; -- (可選)推薦使用Serverless Computing執行巨量資料量離線匯入和ETL作業 SET hg_computing_resource = 'serverless'; -- 匯入資料 INSERT INTO feature_tb ...; VACUUM feature_tb; -- 構建向量索引 CALL set_table_property( 'feature_tb', 'proxima_vectors', '{"<feature_col>":{"algorithm":"Graph", "distance_method":"<value>", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); -- 重設配置,保證非必要的SQL不會使用serverless資源。 RESET hg_computing_resource;
參數說明如下。
分類
參數
描述
樣本
向量基本屬性
feature_col
向量列名稱。
feature。
array_ndims
向量的維度,僅支援一維向量。
構建一維且長度為4的向量樣本如下。
feature float4[] check(array_ndims(feature) = 1 and array_length(feature, 1) = 4)array_length
向量的長度,最大不超過1000000。
向量索引
proxima_vectors
代表構建向量索引,其中:
algorithm:用於指定構建向量索引的演算法,目前僅支援
Graph。distance_method:用於定義構建向量索引使用的距離計算方法,目前支援三種距離計算函數:
(推薦使用)SquaredEuclidean:平方歐式距離, 查詢效率最高。適合查詢時使用
pm_approx_squared_euclidean_distance。Euclidean:開方的歐式距離,僅適合查詢時使用
pm_approx_euclidean_distance,如果使用其他距離函數會利用不上索引。InnerProduct(避免使用):內積距離,會在底層轉換為開方的歐式距離的計算,所以構建索引和查詢索引都會多一層計算開銷,比較低效,盡量避免使用,除非業務有強需求。僅適合查詢時使用
pm_approx_inner_product_distance。
builder_params:控制索引構建的參數,是一個JSON格式的字串,包含以下參數。
min_flush_proxima_row_count:資料寫入到磁碟時建索引的最少行數,建議值為1000。
min_compaction_proxima_row_count:資料在磁碟做合并時建索引的最小行數,建議值為1000。
max_total_size_to_merge_mb: 資料在磁碟做合并時的最大檔案大小,單位MB,建議值為2000。
proxima_builder_thread_count:控制寫入時build向量索引的線程數,預設值為4,一般情境無需修改。
說明索引需要在一定的情境下使用才能發揮更好的作用。
使用平方歐式距離查詢,構建對應的向量索引樣本如下。
call set_table_property( 'feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph", "distance_method":"SquaredEuclidean", "builder_params":{"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}');向量匯入。
可以通過離線或者即時的方式將資料匯入至向量表,可以根據業務需求選擇合適的同步方式。但需要注意的是,在大量匯入後,需要執行VACUUM和Analyze命令以提升查詢效率。
VACUUM會讓後端的檔案compaction成更大的檔案,對查詢更高效。 但是VACUUM需要耗費一定的CPU資源,表的資料量越大,執行VACUUM的時間越久,當VACUUM還在執行中時,請耐心等待執行結果。
VACUUM <tablename>;Analyze是收集統計資訊,用於最佳化器QO(Query Optimizer)產生較優的執行計畫,提高查詢效能。
analyze <tablename>;
向量查詢。
Hologres支援精確和近似向量查詢,其中以
pm_開頭的UDF都為精準查詢,以pm_approx_開頭的UDF都為近似查詢。只有以pm_approx_開頭的非精確查詢才能命中向量索引,對於構建向量索引的情境,更建議使用近似查詢,查詢效率會更高。只有單表查詢時才能命中向量索引,優先推薦單表向量查詢,避免join操作。近似查詢(使用向量索引)
非精確查詢可以命中向量索引,更適用於掃描資料量大,要求執行效率更高的情境,預設召回精度99%以上。使用向量索引,只需要在對應的距離計算函數前加上
approx_首碼,對應的距離計算函數如下:說明平方歐式距離、歐式距離的非精確查詢,只支援
order by distance asc情境下命中向量索引,不支援倒序。內積距離的非精確查詢,只支援
order by distance desc情境下命中向量索引,不支援正序。
FLOAT4 pm_approx_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_approx_inner_product_distance(FLOAT4[], FLOAT4[])同時查詢時的函數需要和建表時的
proxima_vector參數中的distance_method一一對應,使用樣本如下。樣本使用如下的方式查詢Top N,且近似查詢中的第二個參數必須是常量值。說明索引查詢是有損查詢,會有一定的精度損失,預設召回精度一般在99%以上。
-- 計算平方歐式距離的TOPK,此時建表裡面的proxima_vector參數的distance_method需要為SquaredEuclidean SELECT pm_approx_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 計算歐式距離的TOPK,此時建表裡面的proxima_vector參數的distance_method需要為Euclidean SELECT pm_approx_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 計算內積距離的TOPK,此時建表裡面的proxima_vector參數的distance_method需要為InnerProduct SELECT pm_approx_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;精確查詢(不使用向量索引)
精確查詢更加適用於SQL掃描資料量少,且對召回率要求高的情境。歐式距離、平方歐式距離、內積距離三種距離計算方式分別對應以下三種距離計算函數。
FLOAT4 pm_squared_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_euclidean_distance(FLOAT4[], FLOAT4[]) FLOAT4 pm_inner_product_distance(FLOAT4[], FLOAT4[])如果召回和目標向量距離最近的TOP K個鄰居,可以使用以下SQL進行查詢。
說明樣本中是進行精確召回計算的SQL。執行過程為:掃描feature列的所有向量進行距離計算,最後將計算結果排序,取前10條輸出。這種SQL適合資料量小,對召回率要求特別高的情境。
-- 召回平方歐式距離最近的10個鄰居 SELECT pm_squared_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 召回歐式距離最近的10個鄰居 SELECT pm_euclidean_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance ASC limit 10 ; -- 召回內積距離最大的10個鄰居 SELECT pm_inner_product_distance(feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance DESC limit 10 ;
完整使用樣本
對4維x10萬的向量表,使用Proxima索引召回平方歐式距離最近的40條資料樣本如下。
建立向量表。
CREATE EXTENSION proxima; BEGIN; -- 建立一個shard_count = 4 的table group CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE feature_tb ( id BIGINT, feature FLOAT4[] CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = 4) ); CALL set_table_property ('feature_tb', 'table_group', 'test_tg_shard_4'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params": {"min_flush_proxima_row_count" : 1000, "min_compaction_proxima_row_count" : 1000, "max_total_size_to_merge_mb" : 2000}}}'); COMMIT;資料匯入。
-- (可選)推薦使用Serverless Computing執行巨量資料量離線匯入和ETL作業 SET hg_computing_resource = 'serverless'; INSERT INTO feature_tb SELECT i, ARRAY[random(), random(), random(), random()]::FLOAT4[] FROM generate_series(1, 100000) i; ANALYZE feature_tb; VACUUM feature_tb; -- 重設配置,保證非必要的SQL不會使用serverless資源。 RESET hg_computing_resource;查詢。
-- (可選)使用Serverless Computing執行巨量資料量向量查詢作業 SET hg_computing_resource = 'serverless'; SELECT pm_approx_squared_euclidean_distance (feature, '{0.1,0.2,0.3,0.4}') AS distance FROM feature_tb ORDER BY distance LIMIT 40; -- 重設配置,保證非必要的SQL不會使用serverless資源。 RESET hg_computing_resource;
效能調優
設定向量索引的情境
資料量較小,比如幾萬條資料情況下,建議不設定索引直接計算即可。 或者執行個體資源較多的情況下但查詢的資料量較少,也可以直接計算。 當直接計算滿足不了需求(如延遲、吞吐等要求)時,可以考慮使用Proxima索引, 原因如下。
Proxima本身是有損索引,不保證結果的準確性,即計算出來的距離可能是有偏差的。
Proxima索引有可能導致召回的條數不足,如
limit 1000情況下,只返回了500條。Proxima索引使用有一定難度。
設定合適的Shard Count
Shard Count越多, 實際構建Proxima索引的檔案就越多, 查詢吞吐就越差。所以在實際使用中,根據執行個體資源建議設定合理的Shard Count,一般可以將Shard Count設定為Worker的數量,例如64 Core的執行個體建議設定Shard Count為4。同時如果想減少單條查詢的延時,可以減小Shard Count,但是這會降低寫入效能。
-- 建立向量表,並且放於shard_count = 4 的table group中 BEGIN; CALL HG_CREATE_TABLE_GROUP ('test_tg_shard_4', 4); CREATE TABLE proxima_test ( id BIGINT NOT NULL, vectors FLOAT4[] CHECK (array_ndims(vectors) = 1 AND array_length(vectors, 1) = 128), PRIMARY KEY (id) ); CALL set_table_property ('proxima_test', 'proxima_vectors', '{"vectors":{"algorithm":"Graph","distance_method":"SquaredEuclidean","builder_params":{}, "searcher_init_params":{}}}'); CALL set_table_property ('proxima_test', 'table_group', 'test_tg_shard_4'); COMMIT;(推薦)不帶過濾條件的查詢情境
在有
where過濾條件的情況下,會影響索引使用,效能可能更差,所以推薦不帶過濾條件的查詢情境。對於不帶過濾條件的向量檢索,最極致的狀態就是一個Shard上只有一個向量索引檔案,這樣查詢就能直接落在一個Shard上。因此對於不帶過濾條件的查詢情境通常建表如下。
BEGIN; CREATE TABLE feature_tb ( uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) --定義向量 ); CALL set_table_property ('feature_tb', 'shard_count', '?'); --指定shard count,根據業務情況合理設定,若有可以不設定 CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}'); --構建向量索引 END;帶過濾條件的查詢情境
對於帶過濾條件的向量檢索,情況細分為如下常見的過濾情境。
查詢情境1:字串列為過濾條件
樣本查詢如下,常見的情境為在某個組織內尋找對應的向量資料,例如尋找班級內的人臉資料。
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE uuid = 'x' ORDER BY d limit 10;建議進行如下最佳化。
將uuid設定為Distribution Key,這樣相同的過濾資料會儲存在同一個Shard,查詢時一次查詢只會落到一個Shard上。
將uuid設定為表的Clustering Key,資料將會在檔案內根據Clustering Key排序。
查詢情境2:時間欄位為過濾條件
樣本查詢如下,一般是根據時間欄位過濾出對應的向量資料。建議將時間欄位time_field設定為表的segment_key,可以快速的定位到資料所在的檔案。
SELECT pm_xx_distance(feature, '{1,2,3,4}') AS d FROM feature_tb WHERE time_field BETWEEN '2020-08-30 00:00:00' AND '2020-08-30 12:00:00' ORDER BY d limit 10;
因此對於帶過濾條件的向量檢索而言,其建表語句通常如下。
BEGIN; CREATE TABLE feature_tb ( time_field timestamptz NOT NULL, uuid text, feature FLOAT4[] NOT NULL CHECK (array_ndims(feature) = 1 AND array_length(feature, 1) = N) ); CALL set_table_property ('feature_tb', 'distribution_key', 'uuid'); CALL set_table_property ('feature_tb', 'segment_key', 'time_field'); CALL set_table_property ('feature_tb', 'clustering_key', 'uuid'); CALL set_table_property ('feature_tb', 'proxima_vectors', '{"feature":{"algorithm":"Graph","distance_method":"InnerProduct"}}'); COMMIT; -- 如果沒有按照時間過濾的話,則time_field相關的索引可以刪除。
常見問題
報錯
ERROR: function pm_approx_inner_product_distance(real[], unknown) does not exist。原因:通常是因為未在資料庫中執行
create extension proxima;語句來初始化Proxima外掛程式。解決方案:執行
create extension proxima;語句初始化Proxima外掛程式。報錯
Writing column: feature with array size: 5 violates fixed size list (4) constraint declared in schema。原因:由於寫入到特徵向量列的資料維度與表中定義的維度數不一致,導致出現該報錯。
解決方案:可以排查下是否有髒資料。
報錯
The size of two arrays must be the same in DistanceFunction, size of left array: 4, size of right array:。原因:由於
pm_xx_distance(left, right)中,left的維度與right的維度不一致所致。調整
pm_xx_distance(left, right)中,left的維度與right的維度一致。即時寫入報錯
BackPressure Exceed Reject Limit ctxId: XXXXXXXX, tableId: YY, shardId: ZZ。原因:即時寫入作業遇到了瓶頸,產生了反壓的異常,說明寫入作業開銷大,寫入慢,通常是由於min_flush_proxima_row_count較小,而即時寫入速度較大,造成寫入作業即時構建索引開銷大,阻塞了即時寫入。
調整min_flush_proxima_row_count為更大值。
如何通過Java寫入向量資料?
通過Java寫入向量資料的樣本如下。
private static void insertIntoVector(Connection conn) throws Exception { try (PreparedStatement stmt = conn.prepareStatement("insert into feature_tb values(?,?);")) { for (int i = 0; i < 100; ++i) { stmt.setInt(1, i); Float[] featureVector = {0.1f,0.2f,0.3f,0.4f}; Array array = conn.createArrayOf("FLOAT4", featureVector); stmt.setArray(2, array); stmt.execute(); } } }如何通過執行計畫檢查是否利用上Proxima索引?
如果執行計畫中存在
Proxima filter: xxxx表明使用了索引,如下圖所示;如果沒有,則索引沒有使用上,一般是建表語句與查詢語句不匹配。
距離函數說明
Hologres支援的三種向量距離評估函數如下:
不開方的歐式距離(SquaredEuclidean),計算公式如下。
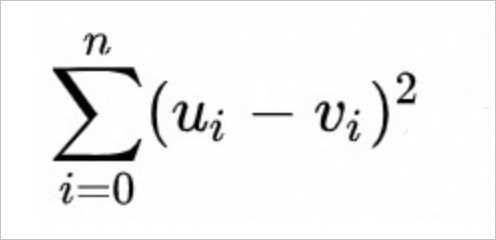
開方的歐氏距離(Euclidean),計算公式如下。
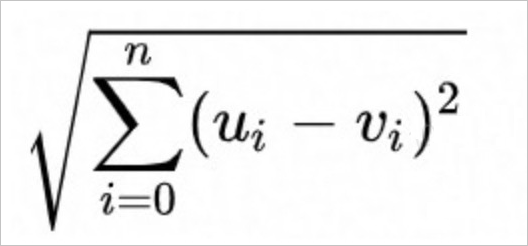
內積距離(InnerProduct),計算公式如下。
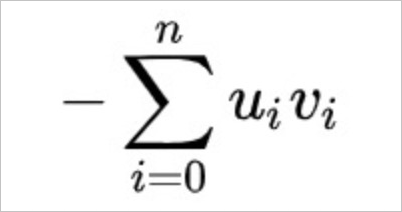
如果您選用歐式距離進行向量計算,不開方的歐式距離與開方的歐式距離相比,可以少一個開方的計算,並且計算出的Top K記錄一致。因此,不開方的歐式距離效能更好,在滿足功能需求的情況下,一般建議您使用不開方的歐式距離。