本文為您介紹如何在開發人員本地環境中運行和調試包含阿里雲Realtime ComputeFlink版連接器的作業,以便快速驗證代碼的正確性,快速定位和解決問題,並節省雲上成本。
背景資訊
當您在IntelliJ IDEA中運行和調試Flink作業,如果其包含了阿里雲Realtime ComputeFlink版的商業版連接器依賴,可能會遇到無法找到連接器相關類的運行錯誤。例如,運行含有MaxCompute連接器的作業時出現如下異常:
Caused by: java.lang.ClassNotFoundException: com.alibaba.ververica.connectors.odps.newsource.split.OdpsSourceSplitSerializer
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)該異常是由於連接器預設JAR包中缺少部分運行類,您可以通過執行下列步驟來添加這些缺失的類,從而能夠在IntelliJ IDEA中運行或調試作業。
本地調試問題繞行方案
步驟一:添加作業配置中的依賴
首先從Maven中央倉庫下載包含運行類的uber JAR包。例如對於MaxCompute使用的依賴ververica-connector-odps,以1.17-vvr-8.0.11-1版本為例,可以從Maven倉庫對應目錄下看到尾碼為uber.jar的ververica-connector-odps-1.17-vvr-8.0.11-1-uber.jar,將其下載到本地目錄。
其次在代碼中建立環境時增加配置pipeline.classpaths為uber jar路徑,若有多個連接器依賴,使用分號隔開,例如file:///path/to/a-uber.jar;file:///path/to/b-uber.jar(對於Windows需要加相應磁碟分割,例如file:///D:/path/to/a-uber.jar;file:///E:/path/to/b-uber.jar)。DataStream API作業通過如下代碼配置:
Configuration conf = new Configuration();
conf.setString("pipeline.classpaths", "file://" + "uber jar絕對路徑");
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment(conf);Table API作業通過如下代碼進行配置:
Configuration conf = new Configuration();
conf.setString("pipeline.classpaths", "file://" + "uber jar絕對路徑");
EnvironmentSettings envSettings =
EnvironmentSettings.newInstance().withConfiguration(conf).build();
TableEnvironment tEnv = TableEnvironment.create(envSettings);該新增的
pipeline.classpaths配置需要在作業打包上傳到阿里雲Realtime ComputeFlink版之前刪除。由於版本差異,低版本的ververica-connector-odps需要下載
1.17-vvr-8.0.11-1版本的uber包以進行本地調試。在打包作業時,除了需避免使用高版本的參數外,仍可使用低版本的Jar進行打包。如果您需要調試的為MySQL連接器,還需額外參考MySQL連接器DataStream調試配置相關的Maven依賴。
本地調試所需的上下遊儲存必須確保網路可用性。可以選擇使用本機存放區或相關雲產品,並開通公網訪問。同時,需要將本地的公網IP地址添加至相應上下遊的白名單中。
步驟二:配置運行所需要的ClassLoader JAR包
為了使Flink能夠載入連接器的運行類,還需添加ClassLoader JAR包。首先按照對應的VVR引擎版本下載依賴至本地,下載連結如下:
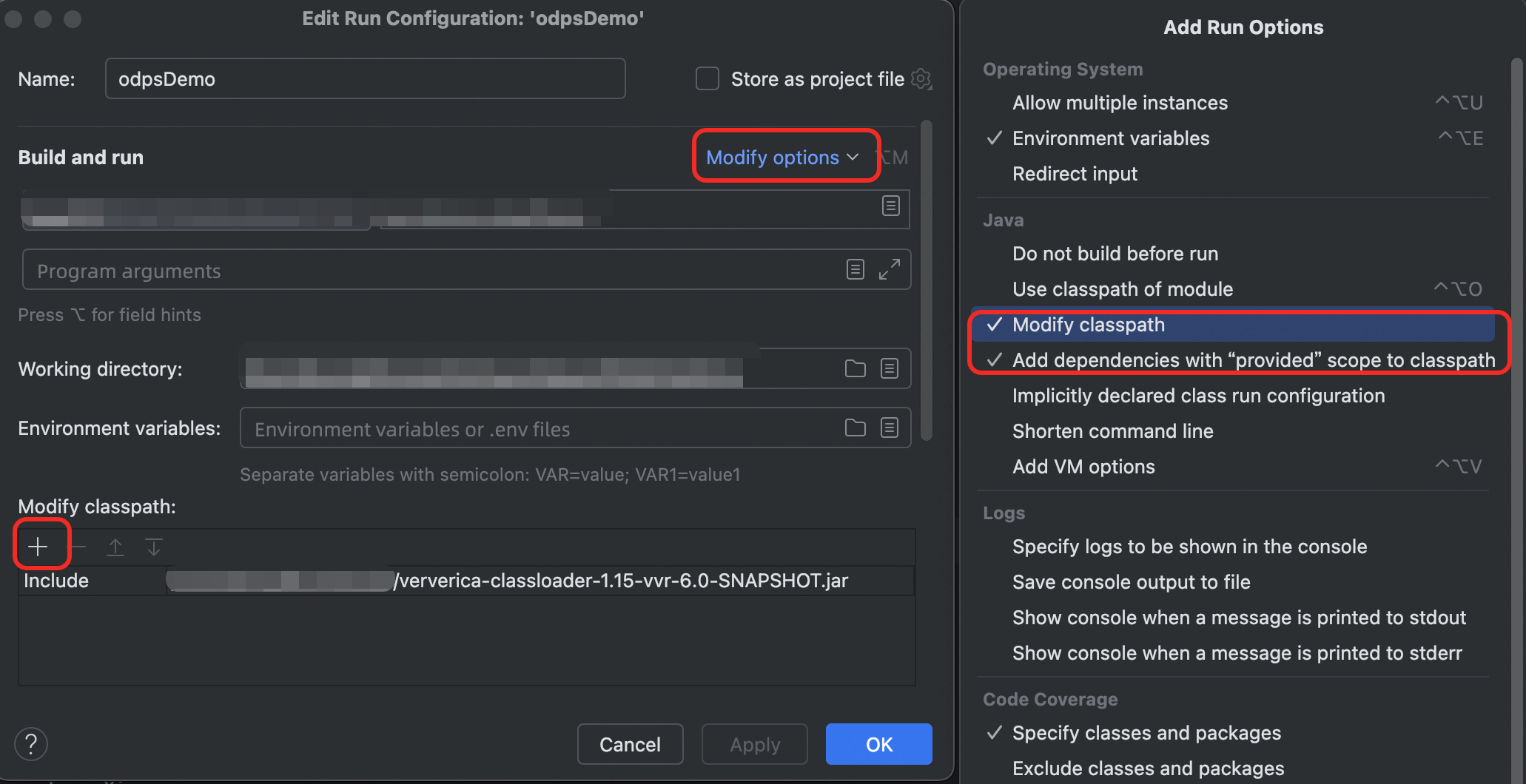
以IntelliJ IDEA為例,對作業的本地回合組態進行修改。點擊入口類左側的綠色表徵圖展開功能表列,並選擇“修改回合組態”:


在開啟的回合組態視窗中,點擊“Modify options”,勾選“Modify classpath”,在視窗下方會增加“Modify classpath”一欄,點擊“+”號選擇上文下載的ClassLoader JAR包,並儲存該回合組態。如果提示缺少一些常見的Flink類無法執行,例如org.apache.flink.configuration.Configuration,需要在“Modify options”處勾選“Add dependencies with provided scope to classpath”。
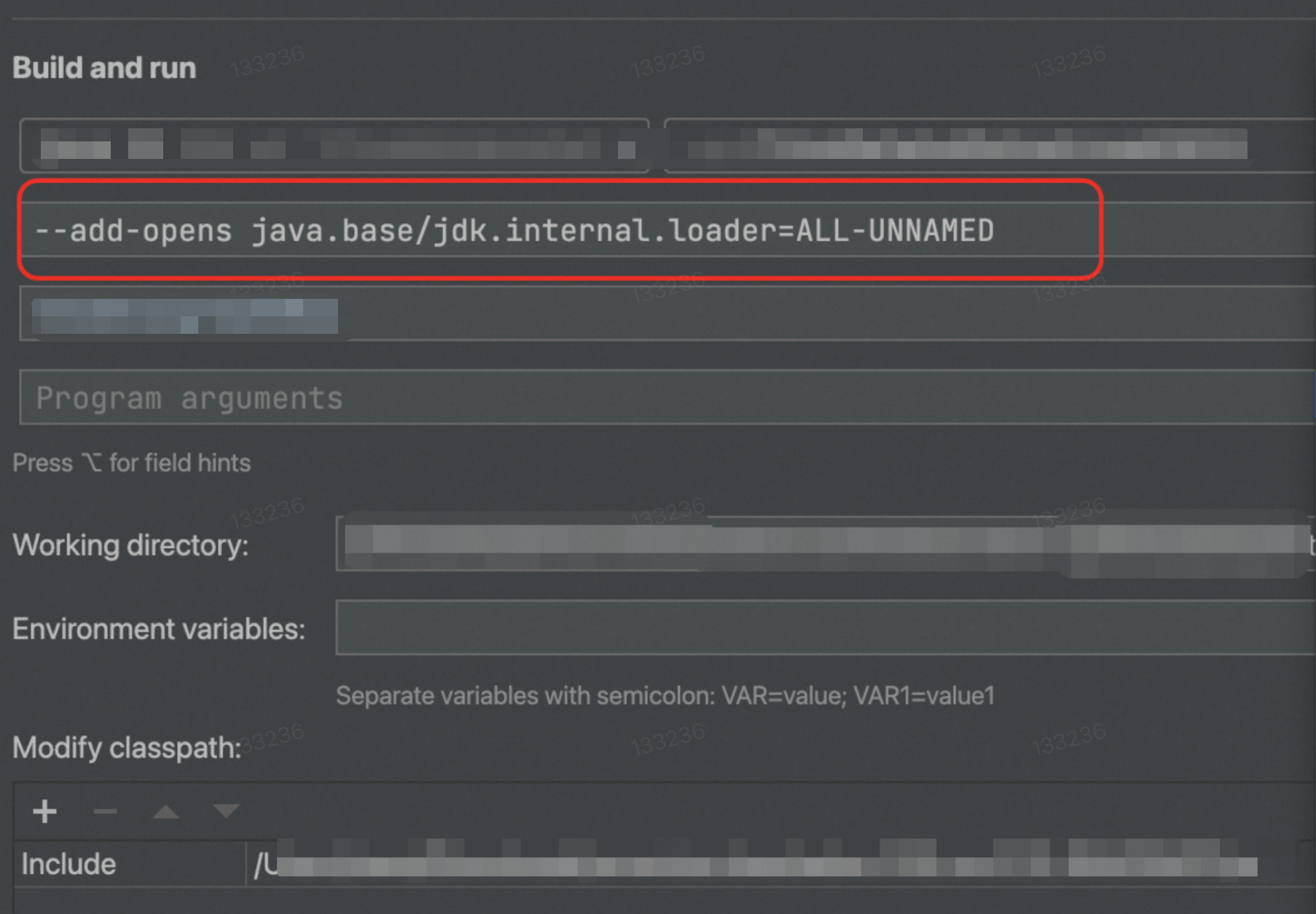
自 VVR 11.1 版本開始, VVR 引擎升級到了 JDK11,您需要在 JVM Options 裡添加選項“--add-opens java.base/jdk.internal.loader=ALL-UNNAMED”,如下所示:
本地調試使用Table API作業的方案
自 VVR 11.1 版本開始,Ververica 連接器不再與社區版本的 flink-table-common 包保持完全相容,您可能在運行時遇到不限於如下報錯:
java.lang.ClassNotFoundException: org.apache.flink.table.factories.OptionUpgradabaleTableFactory您需要將 pom.xml 檔案中 org.apache.flink:flink-table-common 依賴修改為對應版本的 com.alibaba.ververica:flink-table-common,即可解決問題。
相關文檔
本地調試MySQL連接器,詳情請參見MySQL連接器DataStream調試。
通過DataStream的方式讀寫資料,需要使用對應的DataStream連接器串連Realtime ComputeFlink版,DataStream連接器的使用方法和注意事項,詳情請參見JAR作業開發。
Python作業的開發和調試方法,詳情請參見Python作業開發。