當您需要查看並分析Apache日誌資料時,可以使用Filebeat採集日誌資料,並通過阿里雲Logstash過濾採集後的日誌資料,最終傳輸到Elasticsearch中進行分析。本文介紹如何通過Filebeat採集Apache日誌資料。
操作流程
步驟一:準備工作
建立Elasticsearch執行個體和Logstash執行個體,兩者版本相同,並且在同一Virtual Private Cloud(Virtual Private Cloud)下。
具體操作,請參見建立Elasticsearch執行個體和建立阿里雲Logstash執行個體。
開啟Elasticsearch執行個體的自動建立索引功能。
出於安全考慮,Elasticsearch預設不允許自動建立索引。但是Beats目前依賴該功能,因此如果採集器Output選擇為Elasticsearch,需要開啟自動建立索引功能。具體操作,請參見配置YML參數。
建立阿里雲ECS執行個體,並且該ECS執行個體與Elasticsearch執行個體和Logstash執行個體處於同一VPC下。
具體操作,請參見自訂購買執行個體。
重要Beats目前僅支援Alibaba Cloud Linux、RedHat和CentOS三種作業系統。
阿里雲Filebeat僅支援採集與Elasticsearch或Logstash同地區同VPC下ECS伺服器的日誌,不支援採集公網環境下的日誌。
在ECS執行個體上搭建Httpd服務。
為了便於通過視覺化檢視分析展示日誌,建議在httpd.conf中將Apache日誌格式定義為JSON格式,詳情請參見手動搭建Magento2電子商務網站(Ubuntu)。本文的測試環境配置如下。
LogFormat "{\"@timestamp\":\"%{%Y-%m-%dT%H:%M:%S%z}t\",\"client_ip\":\"%{X-Forwa rded-For}i\",\"direct_ip\": \"%a\",\"request_time\":%T,\"status\":%>s,\"url\":\"%U%q\",\"method\":\"%m\",\"http_host\":\"%{Host}i\",\"server_ip\":\"%A\",\"http_referer\":\"%{Referer}i\",\"http_user_agent\":\"%{User-agent}i\",\"body_bytes_sent\":\"%B\",\"total_bytes_sent\":\"%O\"}" access_log_json # 登出原有CustomLog修改為CustomLog "logs/access_log" access_log_json在目標ECS執行個體上安裝雲助手和Docker服務。
具體操作,請參見安裝雲助手Agent和安裝並使用Docker和Docker Compose。
步驟二:配置並安裝Filebeat採集器
進入Beats資料擷取中心。
在頂部功能表列處,選擇地區。
在左側導覽列,單擊Beats資料擷取中心。
可選:首次進入Beats資料擷取中心頁面,需要在服務授權對話方塊中查看提示資訊,無誤後單擊確認,授權系統建立服務關聯角色。
說明Beats採集不同資料來源中的資料時,依賴於服務關聯角色以及角色規則。使用過程中請勿刪除服務關聯角色,否則會影響Beats使用。詳細資料,請參見阿里雲ES服務關聯角色。
在建立採集器地區單擊ECS日誌。
配置並安裝採集器。
單擊下一步。
在採集器安裝設定精靈中,選擇安裝採集器的ECS執行個體。
說明選擇準備工作中建立和配置的ECS執行個體。
啟動採集器並查看採集器安裝情況。
單擊啟動。
啟動成功後,系統彈出啟動成功對話方塊。
單擊前往採集中心查看,返回Beats資料擷取中心頁面,在採集器管理地區中,查看啟動成功的Filebeat採集器。
等待採集器狀態變為已生效後,單擊右側操作列下的查看運行執行個體。
在查看運行執行個體頁面,查看採集器安裝情況,當顯示為心跳正常時,說明採集器安裝成功。

步驟三:配置Logstash管道過濾並同步資料
在Elasticsearch控制台的左側導覽列,單擊LogStash執行個體。
單擊目標Logstash執行個體右側操作列下的管道管理。
在管道管理頁面,單擊建立管道。
配置管道。
參考如下樣本配置管道,詳細配置方法請參見通過設定檔管理管道。
input { beats { port => 8000 } } filter { json { source => "message" remove_field => "@version" remove_field => "prospector" remove_field => "beat" remove_field => "source" remove_field => "input" remove_field => "offset" remove_field => "fields" remove_field => "host" remove_field => "message" } } output { elasticsearch { hosts => ["http://es-cn-mp91cbxsm00******.elasticsearch.aliyuncs.com:9200"] user => "elastic" password => "<YOUR_PASSWORD>" index => "<YOUR_INDEX>" } }參數
說明
input
接收Beats採集的資料。
filter
過濾採集的資料。通過JSON外掛程式進行message資料解碼,使用remove_field刪除指定欄位。
說明本文中的filter配置只適用於當前測試情境,不適用於所有的業務情境。請根據自身業務情境修改filter配置,關於filter支援的外掛程式及每個外掛程式的使用說明,請參見filter plugin。
output
將資料轉送至Elasticsearch執行個體中。參數說明如下:
hosts:替換為您Elasticsearch執行個體的訪問地址,可在執行個體的基本資料頁面擷取,詳細資料請參見查看執行個體的基本資料。
<YOUR_PASSWORD>:替換為您Elasticsearch執行個體的訪問密碼。
<YOUR_INDEX>:替換為您定義的索引名稱。
步驟四:查看資料擷取結果
登入目標Elasticsearch執行個體的Kibana控制台,根據頁面提示進入Kibana首頁。
登入Kibana控制台的具體操作,請參見登入Kibana控制台。
說明本文以Elasticsearch 6.7.0版本為例,其他版本操作可能略有差別,請以實際介面為準。
在左側導覽列,單擊Dev Tools。
在Console中,執行如下命令查看採集成功的資料。
GET <YOUR_INDEX>/_search說明<YOUR_INDEX>需要替換為在配置阿里雲Logstash執行個體的管道時,output中所定義的索引名稱。
在左側導覽列,單擊Discover,選擇一段時間,查看採集的資料詳情。
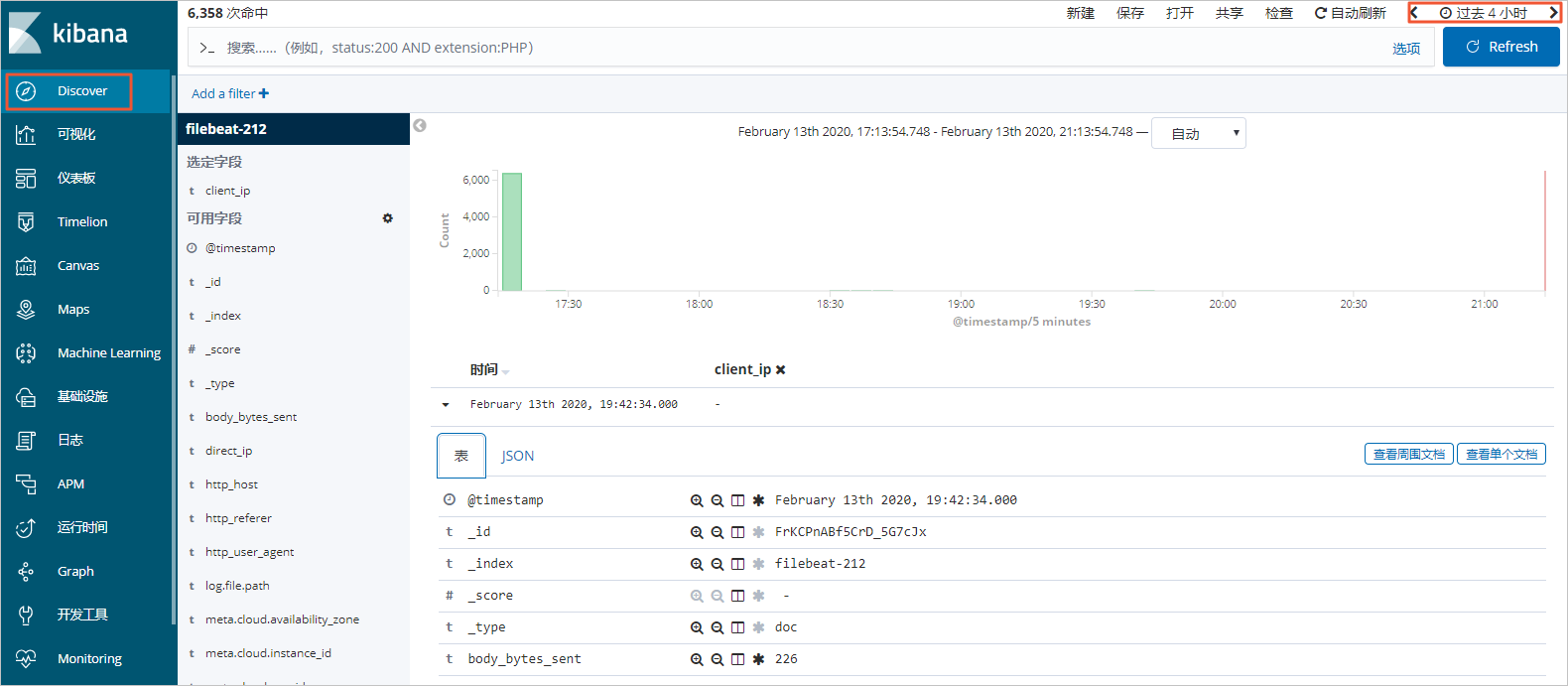 說明
說明在查詢前,請確保您已經建立了<YOUR_INDEX>的索引模式。否則需要在Kibana控制台中,單擊Management,再選擇Kibana地區中的,按照提示建立索引模式。