如果您需要將RDS MySQL中的資料同步到Elasticsearch中,可使用阿里雲Logstash的logstash-input-jdbc外掛程式(預設已安裝,不可卸載),通過管道配置將全量或增量資料即時同步至Elasticsearch中。本文介紹具體的實現方法。
背景資訊
阿里雲Logstash是一款強大的資料收集和處理工具,提供了資料擷取、轉換、最佳化和輸出的能力。通過Logstash的logstash-input-jdbc外掛程式(預設已安裝,不可卸載),可批量查詢RDS MySQL中的資料並同步到Elasticsearch中。同時,logstash-input-jdbc外掛程式會定期對RDS中的資料進行輪詢查詢,並將自上次輪詢以來插入或更改的記錄同步到Elasticsearch。更多詳細資料,請參見官方文檔中的如何使用Logstash和JDBC確保Elasticsearch與關係型資料庫保持同步。本方案適用於同步全量資料且接受秒級延遲的情境或批量查詢特定條件的資料然後進行同步的情境。
前提條件
建議您在同一專用網路下建立以下執行個體:
您也可以使用公網環境的服務,前提是需要配置SNAT、開啟RDS MySQL的公網地址並取消白名單限制。SNAT的具體配置方法,請參見配置NAT公網資料轉送。設定白名單操作,請參見設定IP白名單。
建立RDS MySQL執行個體。具體操作請參見建立RDS MySQL執行個體。本文以MySQL 5.7版本為例。
建立Elasticsearch執行個體。具體操作請參見建立Elasticsearch執行個體。本文以7.10版本ES執行個體為例。
建立阿里雲Logstash執行個體。具體操作參見建立阿里雲Logstash執行個體。
使用限制
確保MySQL執行個體、Logstash執行個體、Elasticsearch執行個體在同一時區,否則當同步與時間相關的資料時,同步前後的資料可能存在時區差。
Elasticsearch中的_id欄位必須與MySQL中的id欄位相同。
該條件可以確保當您將MySQL中的記錄寫入Elasticsearch時,同步任務可在MySQL記錄與Elasticsearch文檔之間建立一個直接映射的關係。例如當您在MySQL中更新了某條記錄時,同步任務會覆蓋Elasticsearch中與更新記錄具有相同ID的文檔。
說明根據Elasticsearch內部原理,更新操作的本質是刪除舊文檔然後對新文檔進行索引,因此在Elasticsearch中覆蓋文檔的效率與更新操作的效率一樣高。
當您在MySQL中插入或者更新資料時,對應記錄必須有一個包含更新或插入時間的欄位。
Logstash每次對MySQL進行輪詢時,都會儲存其從MySQL所讀取的最後一條記錄的更新或插入時間。在讀取資料時,Logstash僅讀取合格記錄,即該記錄的更新或插入時間需要晚於上一次輪詢中最後一條記錄的更新或插入時間。
重要logstash-input-jdbc外掛程式無法實現同步刪除,需要在Elasticsearch中執行相關命令手動刪除。
操作步驟
步驟一:環境準備
在Elasticsearch執行個體中開啟自動建立索引功能。具體操作,請參見快速存取與配置。
在Logstash執行個體中上傳與RDS MySQL版本相容的SQL JDBC驅動(本文使用mysql-connector-java-5.1.48.jar)。具體操作,請參見配置擴充檔案。
準備測試資料,本文使用的建表語句如下。
CREATE table food ( id int PRIMARY key AUTO_INCREMENT, name VARCHAR (32), insert_time DATETIME, update_time DATETIME );插入資料語句如下。
INSERT INTO food values(null,'巧克力',now(),now()); INSERT INTO food values(null,'優酪乳',now(),now()); INSERT INTO food values(null,'火腿腸',now(),now());在RDS MySQL的白名單中加入阿里雲Logstash節點的IP地址(可在Logstash執行個體的基本資料頁面擷取)。
步驟二:配置Logstash管道
進入目標執行個體。
在頂部功能表列處,選擇地區。
在Logstash執行個體中單擊目標執行個體ID。
在左側導覽列,單擊管道管理。
單擊建立管道。
在建立管道任務頁面,輸入管道ID,並進行Config配置。
本文使用的Config配置如下。
input { jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_driver_library => "/ssd/1/share/<Logstash執行個體ID>/logstash/current/config/custom/mysql-connector-java-5.1.48.jar" jdbc_connection_string => "jdbc:mysql://rm-bp1xxxxx.mysql.rds.aliyuncs.com:3306/<資料庫名稱>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" jdbc_user => "xxxxx" jdbc_password => "xxxx" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select * from food where update_time >= :sql_last_value" schedule => "* * * * *" record_last_run => true last_run_metadata_path => "/ssd/1/<Logstash執行個體ID>/logstash/data/last_run_metadata_update_time.txt" clean_run => false tracking_column_type => "timestamp" use_column_value => true tracking_column => "update_time" } } filter { } output { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" index => "rds_es_dxhtest_datetime" user => "elastic" password => "xxxxxxx" document_id => "%{id}" } }說明代碼中
<Logstash執行個體ID>需要替換為您建立的Logstash執行個體的ID。擷取方式,請參見查看執行個體的基本資料。表 1. Config配置說明
配置
說明
input
指定輸入資料來源。支援的資料來源類型,請參見Input plugins。本文使用JDBC資料來源,具體參數說明請參見input參數說明。
filter
指定對輸入資料進行過濾的外掛程式。支援的外掛程式類型,請參見Filter plugins。
output
指定目標資料來源類型。支援的資料來源類型,請參見Output plugins。本文需要將MySQL中的資料同步至Elasticsearch中,因此output中需要指定目標Elasticsearch的資訊。具體參數說明,請參見步驟三:建立並運行管道任務。
重要如果output中使用了file_extend參數,需要先安裝logstash-output-file_extend外掛程式。具體操作,請參見安裝或卸載外掛程式。
表 2. input參數說明
參數
描述
jdbc_driver_class
JDBC Class配置。
jdbc_driver_library
指定JDBC串連MySQL驅動檔案,格式為/ssd/1/share/<Logstash執行個體ID>/logstash/current/config/custom/<驅動檔案名稱>。您需要提前在控制台中上傳驅動檔案,阿里雲Logstash支援的驅動檔案及其上傳方法,請參見配置擴充檔案。
jdbc_connection_string
設定資料庫串連的網域名稱、連接埠及資料庫,格式為
jdbc:mysql://<MySQL的串連地址>:<連接埠>/<資料庫名稱>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false。<MySQL的串連地址>:配置MySQL的內網地址。
<連接埠>:需要與MySQL的出方向連接埠保持一致,一般為3306。
說明如果使用外網地址,需要為Logstash配置NAT Gateway,將
jdbc:mysql://<MySQL的串連地址>:<連接埠>配置為公網網域名稱,實現公網資料轉送。具體操作,請參見配置NAT公網資料轉送。jdbc_user
資料庫使用者名稱。
jdbc_password
資料庫密碼。
jdbc_paging_enabled
是否啟用分頁,預設false。
jdbc_page_size
分頁大小。
statement
指定SQL語句,多表查詢可使用join語句。
說明sql_last_value用於計算要查詢哪一行,在運行任何查詢之前,此值設定為1970年1月1日星期四。詳細資料,請參見Jdbc input plugin。
schedule
指定定時操作,"* * * * *"表示每分鐘定時同步資料。該參數使用的是Rufus版的Cron運算式。
record_last_run
是否記錄上次執行結果。如果為true,則會把上次執行到的tracking_column欄位的值記錄下來,儲存到last_run_metadata_path指定的檔案中。
last_run_metadata_path
指定最後已耗用時間檔案存放的地址。目前後端開放了
/ssd/1/<Logstash執行個體ID>/logstash/data/路徑來儲存檔案。指定參數路徑後,Logstash會在對應路徑下自動組建檔案,但不支援查看檔案內容。說明配置Logstash管道時,建議按照
/ssd/1/<Logstash執行個體ID>/logstash/data/路徑配置此參數。如果不按照該路徑配置,會導致同步的條件記錄因為許可權不足而無法存放在last_run_metadata_path路徑下的設定檔中。clean_run
是否清除last_run_metadata_path的記錄,預設為false。如果為true,那麼每次都要從頭開始查詢所有的資料庫記錄。
use_column_value
是否需要記錄某個column的值。當該值設定成true時,系統會記錄tracking_column參數所指定的列的最新的值,並在下一次管道執行時通過該列的值來判斷需要更新的記錄。
tracking_column_type
跟蹤列的類型,預設是numeric。
tracking_column
指定跟蹤列,該列必須是遞增的,一般是MySQL主鍵。
重要以上配置按照測試資料配置,在實際業務中,請按照業務需求進行合理配置。input外掛程式支援的其他配置選項,請參見官方Logstash Jdbc input plugin文檔。
如果配置中有類似last_run_metadata_path的參數,那麼需要阿里雲Logstash服務提供檔案路徑。目前後端開放了
/ssd/1/<Logstash執行個體ID>/logstash/data/路徑供您測試使用,且該目錄下的資料不會被刪除。因此在使用時,請確保磁碟有充足的使用空間。指定參數路徑後,Logstash會在對應路徑下自動組建檔案,但不支援查看檔案內容。為了提升安全性,如果在配置管道時使用了JDBC驅動,需要在jdbc_connection_string參數後面添加allowLoadLocalInfile=false&autoDeserialize=false,否則當您在添加Logstash設定檔時,調度系統會拋出校正失敗的提示,例如
jdbc_connection_string => "jdbc:mysql://xxx.drds.aliyuncs.com:3306/<資料庫名稱>?allowLoadLocalInfile=false&autoDeserialize=false"。
更多Config配置,請參見Logstash設定檔說明。
單擊下一步,配置管道參數。

參數
說明
管道背景工作執行緒
並存執行管道的Filter和Output的背景工作執行緒數量。當事件出現積壓或CPU未飽和時,請考慮增大線程數,更好地使用CPU處理能力。預設值:執行個體的CPU核心數。
管道批大小
單個背景工作執行緒在嘗試執行Filter和Output前,可以從Input收集的最大事件數目。較大的管道批大小可能會帶來較大的記憶體開銷。您可以設定LS_HEAP_SIZE變數,來增大JVM堆大小,從而有效使用該值。預設值:125。
管道批延遲
建立管道事件批時,將過小的批指派給管道背景工作執行緒之前,要等候每個事件的時間長度,單位為毫秒。預設值:50ms。
隊列類型
用於事件緩衝的內部排隊模型。可選值:
MEMORY:預設值。基於記憶體的傳統隊列。
PERSISTED:基於磁碟的ACKed隊列(持久隊列)。
隊列最大位元組數
請確保該值小於您的磁碟總容量。預設值:1024 MB。
隊列檢查點寫入數
啟用持久性隊列時,在強制執行檢查點之前已寫入事件的最大數目。設定為0,表示無限制。預設值:1024。
警告配置完成後,需要儲存並部署才會生效。儲存並部署操作會觸發執行個體重啟,請在不影響業務的前提下,繼續執行以下步驟。
單擊儲存或者儲存並部署。
儲存:將管道資訊儲存在Logstash裡並觸發執行個體變更,配置不會生效。儲存後,系統會返回管道管理頁面。可在管道列表地區,單擊操作列下的立即部署,觸發執行個體重啟,使配置生效。
儲存並部署:儲存並且部署後,會觸發執行個體重啟,使配置生效。
步驟三:驗證結果
登入Elasticsearch執行個體的Kibana控制台。
具體操作,請參見登入Kibana控制台。
在Kibana頁面的左上方,選擇
 > Management > Dev Tools
> Management > Dev Tools在Console中,執行如下命令,查看同步成功的索引數量。
GET rds_es_dxhtest_datetime/_count { "query": {"match_all": {}} }預期結果如下。
{ "count" : 3, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 } }更新MySQL表資料並插入表資料。
UPDATE food SET name='Chocolates',update_time=now() where id = 1; INSERT INTO food values(null,'雞蛋',now(),now());在Kibana控制台,查看更新後的資料。
查詢name為Chocolates的資料。
GET rds_es_dxhtest_datetime/_search { "query": { "match": { "name": "Chocolates" }} }預期結果如下。
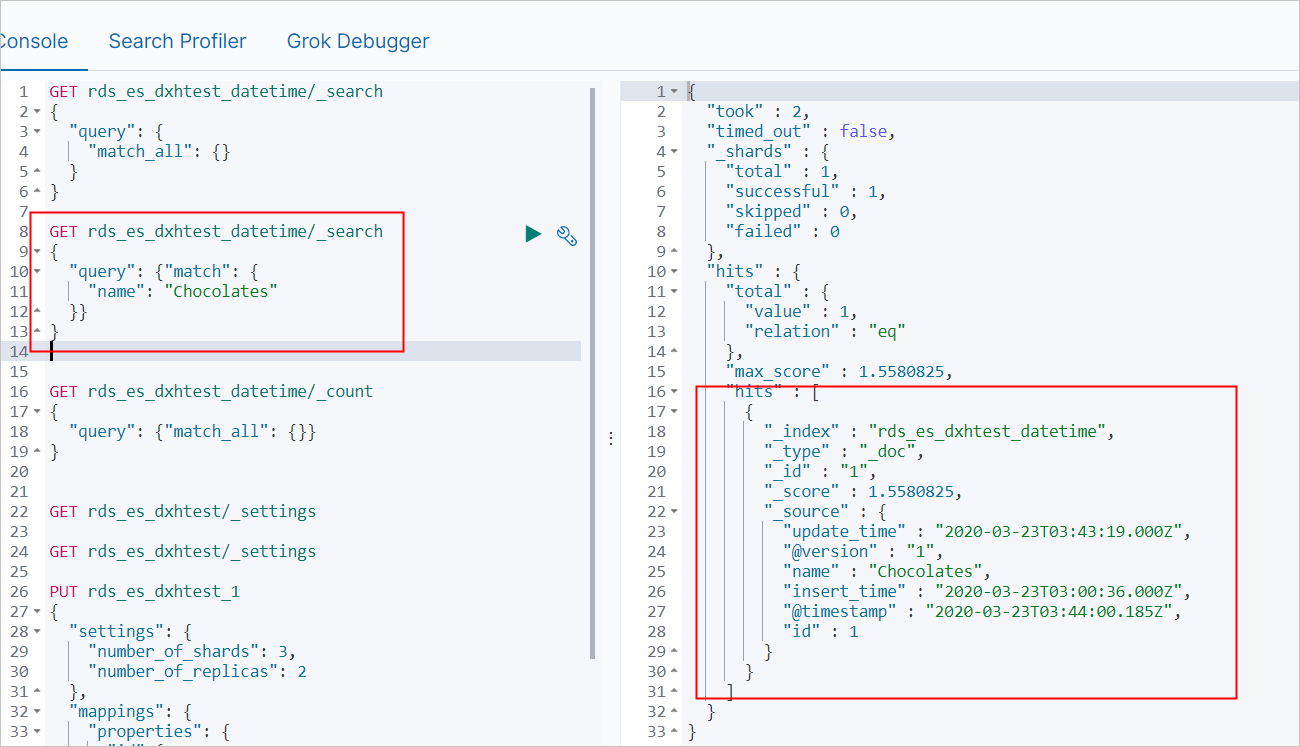
查詢所有資料。
GET rds_es_dxhtest_datetime/_search { "query": { "match_all": {} } }預期結果如下。
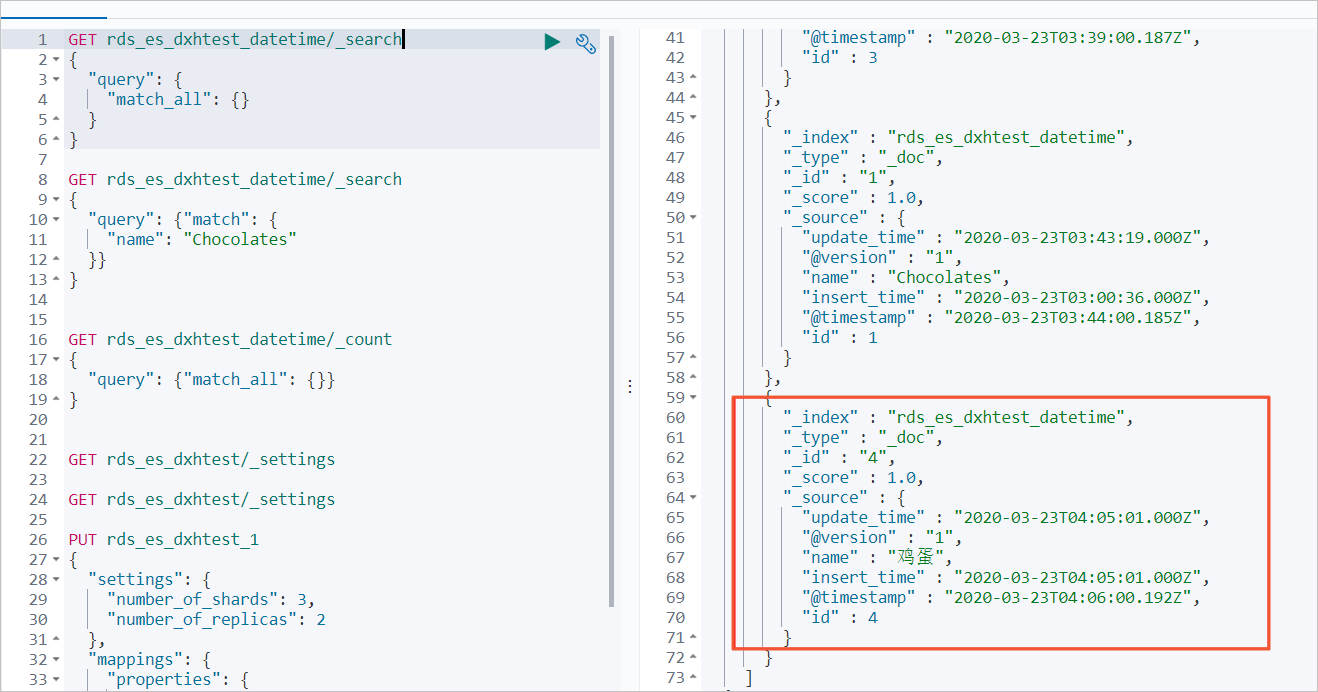
常見問題
Q:同步任務失敗(例如管道一直在生效中、前後資料不一致、資料庫連接不成功),如何解決?
A:查看Logstash執行個體的主日誌是否有報錯,根據報錯判斷原因,具體操作請參見查詢日誌。常見的原因及解決方案如下。
說明執行以下操作時,如果叢集正在變更中,可參見查看執行個體任務進度詳情先中斷變更,操作完成後再觸發重啟恢複。
原因
解決方案
MySQL白名單中沒有加入Logstash的IP地址。
參見通過用戶端、命令列串連RDS MySQL執行個體,在MySQL白名單中加入Logstash節點的IP地址。
說明擷取Logstash的IP地址的具體操作,請參見查看執行個體的基本資料。
Logstash的IP地址沒有添加到對應ECS伺服器的安全性群組中(ECS自建MySQL)。
參見添加安全性群組規則,在ECS安全性群組中添加Logstash的IP地址和連接埠號碼。
說明擷取Logstash的IP地址和連接埠號碼的具體操作,請參見查看執行個體的基本資料。
Logstash和Elasticsearch不在同一VPC下。
選擇以下任意一種方式處理:
參見建立Elasticsearch執行個體,重新購買同一VPC下的Elasticsearch執行個體。購買後,修改現有管道配置。
參見配置NAT公網資料轉送,配置NAT Gateway實現公網資料轉送。
MySQL地址不正確,連接埠不是3306。
參見查看和管理執行個體串連地址和連接埠,擷取正確的地址和連接埠。使用正確的地址和連接埠,按照指令碼格式替換管道配置中的jdbc_connection_string參數值。
重要<MySQL的串連地址>:需要配置MySQL的內網地址。如果使用外網地址,需要為Logstash配置NAT Gateway實現公網資料轉送,具體操作請參見配置NAT公網資料轉送。
Elasticsearch未開啟自動建立索引。
參見配置YML參數,開啟Elasticsearch執行個體的自動建立索引功能。
Elasticsearch或Logstash的負載太高。
參見升配叢集,升級執行個體規格。
說明Elasticsearch負載情況可參見指標含義與異常處理建議,通過控制台監控指標查看。Logstash負載情況可參見配置X-Pack監控,通過Kibana X-Pack監控查看。
沒有上傳JDBC串連MySQL的驅動檔案。
參見配置擴充檔案,下載並上傳驅動檔案。
管道配置中包含了file_extend,但沒有安裝logstash-output-file_extend外掛程式。
選擇以下任意一種方式處理:
參見安裝或卸載外掛程式,安裝logstash-output-file_extend外掛程式。
在管道配置中,去掉file_extend配置。
更多問題原因及解決方案,請參見Logstash資料寫入問題排查方案。
Q:管道input配置中,如何在一個管道中配置多個源端JDBC?
A:您可以在管道input配置中定義多個jdbc資料來源,並在statement中指定對應表的查詢語句,實現一個管道中配置多個源端JDBC,參考樣本如下。
input { jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_driver_library => "/ssd/1/share/<Logstash執行個體ID>/logstash/current/config/custom/mysql-connector-java-5.1.48.jar" jdbc_connection_string => "jdbc:mysql://rm-bp1xxxxx.mysql.rds.aliyuncs.com:3306/<資料庫名稱>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" jdbc_user => "xxxxx" jdbc_password => "xxxx" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select * from tableA where update_time >= :sql_last_value" schedule => "* * * * *" record_last_run => true last_run_metadata_path => "/ssd/1/<Logstash執行個體ID>/logstash/data/last_run_metadata_update_time.txt" clean_run => false tracking_column_type => "timestamp" use_column_value => true tracking_column => "update_time" type => "A" } jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_driver_library => "/ssd/1/share/<Logstash執行個體ID>/logstash/current/config/custom/mysql-connector-java-5.1.48.jar" jdbc_connection_string => "jdbc:mysql://rm-bp1xxxxx.mysql.rds.aliyuncs.com:3306/<資料庫名稱>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" jdbc_user => "xxxxx" jdbc_password => "xxxx" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select * from tableB where update_time >= :sql_last_value" schedule => "* * * * *" record_last_run => true last_run_metadata_path => "/ssd/1/<Logstash執行個體ID>/logstash/data/last_run_metadata_update_time.txt" clean_run => false tracking_column_type => "timestamp" use_column_value => true tracking_column => "update_time" type => "B" } } output { if[type] == "A" { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" index => "rds_es_dxhtest_datetime_A" user => "elastic" password => "xxxxxxx" document_id => "%{id}" } } if[type] == "B" { elasticsearch { hosts => "http://es-cn-0h****dd0hcbnl.elasticsearch.aliyuncs.com:9200" index => "rds_es_dxhtest_datetime_B" user => "elastic" password => "xxxxxxx" document_id => "%{id}" } } }以上樣本在jdbc中,新增了一個屬性type,用來在output中進行判斷,將不同表的資料同步至不同的索引中。