本文為您介紹如何有效地查看和解讀Query Profile,進而利用Query Profile精準定位StarRocks執行個體中的查詢效能瓶頸,並針對這些瓶頸採取相應的最佳化措施以提升查詢效率。
Query Profile概覽
可視化Query Profile
StarRocks Manager支援對Query Profile進行可視化分析,關於Query Profile的詳細資料,請參見Query Profile介紹。
確認查詢瓶頸
Operator花費的時間比例越大,其對應顏色就越深(支援對執行耗時排名前三的節點標註顏色)。您可以藉此輕鬆確認查詢的瓶頸。
Query Profile最佳化案例
Bitmap索引
Bitmap索引是一種使用bitmap的特殊資料庫索引。bitmap即為一個bit數組,一個bit的取值有0和1兩種。每一個bit對應資料表中的一行,並根據該行的取值情況來決定bit的取值是0還是1。
對於基數較低且大量重複(例如,性別)的欄位值,可以使用Bitmap過濾器來提高查詢效率。
查詢是否命中了Bitmap filter索引,可查看該查詢的Profile中的BitmapIndexFilterRows欄位。
建立索引
建表時建立Bitmap索引
CREATE TABLE `student_info` ( `s_stukey` bigint(20) NULL COMMENT "", `s_name` varchar(65533) NULL COMMENT "", `s_gender` varchar(65533) NULL COMMENT "", INDEX index1 (s_gender) USING BITMAP COMMENT 'index1' ) ENGINE=OLAP DUPLICATE KEY(`s_stukey`) COMMENT "OLAP" DISTRIBUTED BY HASH(`s_stukey`); INSERT INTO student_info VALUES (001,'student#000000019','male'), (002,'student#000000020','male'), (003,'student#000000021','male'), (004,'student#000000022','female');建表後使用CREATE INDEX建立Bitmap索引
CREATE INDEX index_name ON table_name (column_name) [USING BITMAP] [COMMENT ''];
查看建立索引進度
SHOW ALTER TABLE COLUMN [FROM db_name];查看索引
SHOW {INDEX[ES] | KEY[S] } FROM [db_name.]table_name [FROM db_name];
刪除索引
DROP INDEX index_name ON [db_name.]table_name;單列查詢測試
執行Query,過濾s_gender列。
select * from student_info where s_gender='male';查看Profile。
單擊OLAP_SCAN,然後單擊右側的節點詳情頁簽,過濾Bitmap可以看到Bitmap索引已經生效。
Bloom filter索引
Bloom filter索引可以快速判斷表的資料檔案中是否可能包含要查詢的資料,如果不包含就跳過,從而減少掃描的資料量。Bloom Filter空間效率高,適用於高基數的列(例如,ID列)。
主鍵模型和明細模型中所有列都可以建立Bloom filter索引;彙總模型和更新模型中,只有維度列(即Key列)支援建立Bloom filter索引。
不支援為TINYINT、FLOAT、DOUBLE和DECIMAL類型的列建立Bloom filter索引。
Bloom filter索引只能提高包含
in和=過濾條件的查詢效率。例如Select xxx from table where xxx in ()和Select xxx from table where column = xxx。查詢是否命中了Bloom filter索引,可查看該查詢的Profile中的BloomFilterFilterRows欄位。
建立索引
建表時,通過在PROPERTIES中指定bloom_filter_columns來建立索引。樣本如下。
CREATE TABLE table1
(
k1 BIGINT,
k2 LARGEINT,
v1 VARCHAR(2048) REPLACE,
v2 SMALLINT DEFAULT "10"
)
ENGINE = olap
PRIMARY KEY(k1, k2)
DISTRIBUTED BY HASH (k1, k2) BUCKETS 10
PROPERTIES("bloom_filter_columns" = "k1,k2"); --多個索引列之間需用逗號(,)隔開;查看索引
SHOW CREATE TABLE table1;修改索引
樣本如下所示:
增加一個Bloom filter索引列v1。
ALTER TABLE table1 SET ("bloom_filter_columns" = "k1,k2,v1");減少一個Bloom filter索引列k2。
ALTER TABLE table1 SET ("bloom_filter_columns" = "k1");刪除table1的所有Bloom filter索引。
ALTER TABLE table1 SET ("bloom_filter_columns" = "");
執行個體測試
以TPC_H中的customer表為例,在基數較高的列且非排序Key的列上增加Bloom filter索引,例如c_phone列。
ALTER TABLE tpc_h_sf100.customer SET ("bloom_filter_columns" = "c_custkey, c_phone");查看索引,確認Bloom filter索引已添加。
SHOW CREATE TABLE tpc_h_sf100.customer;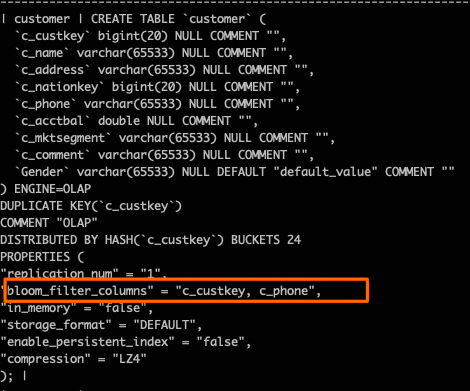
執行Query,過濾c_phone列。
select * from tpc_h_sf100.customer where c_phone = "10-334-921-5346";查看Profile。
單擊OLAP_SCAN,然後單擊右側的節點詳情頁簽,找到BloomFilterFilterRows指標,確認BloomFilter Index生效。
最佳化資料扭曲
以TPC_H中的lineitem表為例,選擇非均勻分布的key作為分桶鍵來測試資料扭曲問題。本樣本中l_tag欄位的value分布不均勻。
建立測試資料,在TPC_H中的lineitem表中新增一列,作為DISTRIBUTED欄位。
CREATE TABLE `lineitem_tag` ( `l_orderkey` bigint(20) NULL COMMENT "", `l_partkey` bigint(20) NULL COMMENT "", `l_suppkey` bigint(20) NULL COMMENT "", `l_linenumber` int(11) NULL COMMENT "", `l_quantity` double NULL COMMENT "", `l_extendedprice` double NULL COMMENT "", `l_discount` double NULL COMMENT "", `l_tax` double NULL COMMENT "", `l_returnflag` varchar(65533) NULL COMMENT "", `l_linestatus` varchar(65533) NULL COMMENT "", `l_shipdate` date NULL COMMENT "", `l_commitdate` date NULL COMMENT "", `l_receiptdate` date NULL COMMENT "", `l_shipinstruct` varchar(65533) NULL COMMENT "", `l_shipmode` varchar(65533) NULL COMMENT "", `l_comment` varchar(65533) NULL COMMENT "", `l_tag` varchar(65533) default 'false' COMMENT "" ) ENGINE=OLAP DUPLICATE KEY(`l_orderkey`) COMMENT "OLAP" DISTRIBUTED BY HASH(`l_tag`) BUCKETS 96 PROPERTIES ( "replication_num" = "1", "in_memory" = "false", "storage_format" = "DEFAULT", "enable_persistent_index" = "false" ); insert into lineitem_tag select *, 'false' as l_tag from tpc_h_sf100.lineitem;執行Query,進行全表查詢。
select count(1) from lineitem_tag;查看Profile。
單擊OLAP_SCAN,在右側的節點頁簽,對比MaxTime和MinTime下的SCAN,發現時間相差好幾個量級,可能發生了資料扭曲。
通過最佳化表結構重新定義DISTRIBUTED欄位。
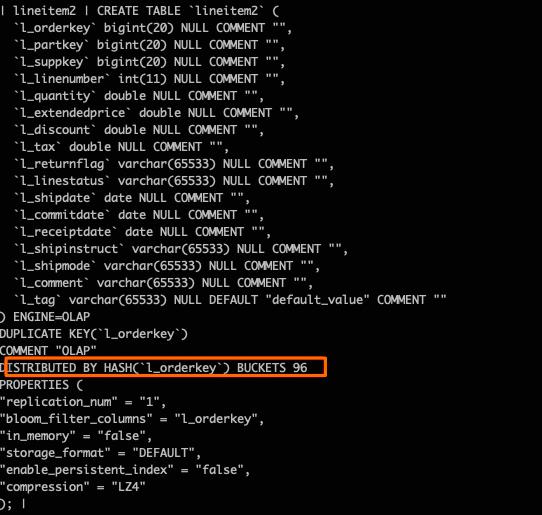
再次查看Profile,對比MaxTime和MinTime下的SCAN,可以探索資料傾斜問題得到最佳化。
單表物化視圖
StarRocks中的單表物化視圖(Rollup)是一種特殊的索引,無法直接查詢。如果您的資料倉儲中存在大量複雜或重複的查詢,您可以通過建立單表物化視圖加速查詢。
查詢測試
以TPC_H中lineitem表為例,執行Query。
select l_returnflag,l_linestatus,l_shipmode,sum(l_extendedprice) from lineitem group by l_returnflag,l_linestatus,l_shipmode;初次查詢,未建立物化視圖查詢耗時1115毫秒。
查看Profile。
單擊OLAP_SCAN,在右側的節點頁簽,可以看到Rollup掃描的是lineitem表本身。
建立物化視圖
CREATE MATERIALIZED VIEW material_test AS select l_returnflag,l_linestatus ,l_shipmode,sum(l_extendedprice) from lineitem group by l_returnflag,l_linestatus,l_shipmode;驗證查詢是否命中單表物化視圖
您可以使用EXPLAIN命令查看該查詢是否命中單表物化視圖。
explain select l_returnflag,l_linestatus ,l_shipmode,sum(l_extendedprice) from lineitem group by l_returnflag,l_linestatus,l_shipmode;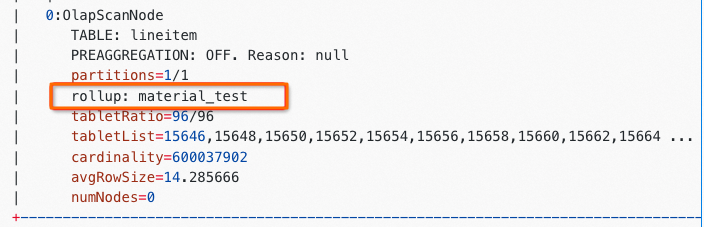
查看Profile。
單擊OLAP_SCAN,在右側的節點頁簽,可以看到命中物化視,同時Query用時也更短,耗時0.05毫秒。
確認JoinRuntimeFilter是否生效
當Join的右表構建Hash Table時,會構建Runtime Filter,該Runtime Filter會被投遞到左子樹,並儘可能地下推到Scan Operator。您可以在Scan Operator的節點詳情選項卡上查看與JoinRuntimeFilter相關的指標。
以TPC_DH中的query72.sql為例,。
select i_item_desc, w_warehouse_name, d1.d_week_seq, sum(case when p_promo_sk is null then 1 else 0 end) no_promo, sum(case when p_promo_sk is not null then 1 else 0 end) promo, count(*) total_cnt from inventory join catalog_sales on (cs_item_sk = inv_item_sk) join warehouse on (w_warehouse_sk=inv_warehouse_sk) join item on (i_item_sk = cs_item_sk) join customer_demographics on (cs_bill_cdemo_sk = cd_demo_sk) join household_demographics on (cs_bill_hdemo_sk = hd_demo_sk) join date_dim d1 on (cs_sold_date_sk = d1.d_date_sk) join date_dim d2 on (inv_date_sk = d2.d_date_sk) join date_dim d3 on (cs_ship_date_sk = d3.d_date_sk) left outer join promotion on (cs_promo_sk=p_promo_sk) left outer join catalog_returns on (cr_item_sk = cs_item_sk and cr_order_number = cs_order_number) where d1.d_week_seq = d2.d_week_seq and inv_quantity_on_hand < cs_quantity and d3.d_date > (cast(d1.d_date AS DATE) + interval '5' day) and hd_buy_potential = '>10000' and d1.d_year = 1999 and cd_marital_status = 'D' group by i_item_desc,w_warehouse_name,d1.d_week_seq order by total_cnt desc, i_item_desc, w_warehouse_name, d1.d_week_seq limit 100;查看Profile。
單擊OLAP_SCAN,單擊右側的節點詳情頁簽,可以看到在Scan Operator運算元掃描inventory表時觸發了JoinRuntimeFilter。
Colocate Join
在StarRocks中使用Colocate Join功能,需要在建表時為其指定一個Colocation Group(CG),同一CG內的表需遵循相同的Colocation Group Schema(CGS),可以保證同一CG內所有表的資料分布在相同一組BE節點上。當Join列為分桶鍵時,計算節點只需做本地Join,從而減少資料在節點間的傳輸耗時,提高查詢效能。因此,Colocate Join相對於其他Join,例如Shuffle Join和Broadcast Join,可以有效避免資料網路傳輸開銷,提高查詢效能。
建立Colocation表
StarRocks僅支援對同一Database中的表進行Colocate Join操作。
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);刪除Colocation Group
當Group中最後一張表徹底刪除後,該Group也會被自動刪除。徹底刪除是指從資源回收筒中刪除。通常,一張表通過DROP TABLE命令被刪除後,會在資源回收筒預設停留一天的時間後,再被徹底刪除。
查看Group資訊
例如,執行以下命令,查看Group資訊。
SHOW PROC '/colocation_group';返回資訊如下。
+-------------+--------------+----------+------------+----------------+----------+----------+
| GroupId | GroupName | TableIds | BucketsNum | ReplicationNum | DistCols | IsStable |
+-------------+--------------+----------+------------+----------------+----------+----------+
| 11912.11916 | 11912_group1 | 11914 | 8 | 3 | int(11) | true |
+-------------+--------------+----------+------------+----------------+----------+----------+各參數含義如下表所示。
列名 | 描述 |
GroupId | 一個Group的全叢集唯一標識。前半部分為DataBase ID,後半部分為Group ID。 |
GroupName | Group的全名。 |
TabletIds | 該Group包含的表的ID列表。 |
BucketsNum | 分桶數。 |
ReplicationNum | 副本數。 |
DistCols | Distribution columns,即分桶列類型。 |
IsStable | 該Group是否穩定。 |
您可以通過以下命令進一步查看特定Group的資料分布情況。
SHOW PROC '/colocation_group/GroupId';
SHOW PROC '/colocation_group/11912.11916';返回資訊如下。
+-------------+---------------------+
| BucketIndex | BackendIds |
+-------------+---------------------+
| 0 | 10002, 10004, 10003 |
| 1 | 10002, 10004, 10003 |
| 2 | 10002, 10004, 10003 |
| 3 | 10002, 10004, 10003 |
| 4 | 10002, 10004, 10003 |
| 5 | 10002, 10004, 10003 |
| 6 | 10002, 10004, 10003 |
| 7 | 10002, 10004, 10003 |
+-------------+---------------------+
8 rows in set (0.00 sec)修改Group屬性
ALTER TABLE tbl SET ("colocate_with" = "group_name");以TPC_H中資料為例,執行以下操作。
use tpc_h_sf100; ALTER TABLE orders SET ("colocate_with" = "cg_tpc_orders"); ALTER TABLE lineitem SET ("colocate_with" = "cg_tpc_orders");執行以下Query查詢。
select count(1) from orders as o join lineitem as l on o.o_orderkey = l.l_orderkey;您可以在EMR StarRocks Manager頁面查詢的查詢計劃頁簽,查看Colocate Join是否生效。
當
colocate顯示為true時,表示Colocate Join生效。
確認分桶或分區裁剪是否生效
您可以在EMR StarRocks Manager頁面查詢的查詢計劃頁簽,查看參數partition或tabletRatio,確認分區或分桶裁剪是否生效。