本文以ECS串連EMR Serverless Spark為例,介紹如何通過EMR Serverless spark-submit命令列工具進行Spark任務開發。
前提條件
已安裝Java 1.8或以上版本。
如果使用RAM使用者(子帳號)提交Spark任務,需要將RAM使用者(子帳號)添加至Serverless Spark的工作空間中,並授予開發人員或開發人員以上的角色許可權,操作請參見系統管理使用者和角色。
操作流程
步驟一:下載並安裝EMR Serverless spark-submit工具
將安裝包上傳至ECS執行個體,詳情請參見上傳或下載檔案。
執行以下命令,解壓並安裝EMR Serverless spark-submit工具。
unzip emr-serverless-spark-tool-0.11.3-SNAPSHOT-bin.zip
步驟二:配置相關參數
在已安裝Spark的環境中,如果系統中設定了SPARK_CONF_DIR 環境變數,則需將設定檔放置在SPARK_CONF_DIR所指定的目錄下。例如,在EMR叢集中,該目錄通常為/etc/taihao-apps/spark-conf。否則,系統會報錯。
執行以下命令,修改
connection.properties中的配置。vim emr-serverless-spark-tool-0.11.3-SNAPSHOT/conf/connection.properties推薦按照如下內容對檔案進行配置,參數格式為
key=value,樣本如下。accessKeyId=<ALIBABA_CLOUD_ACCESS_KEY_ID> accessKeySecret=<ALIBABA_CLOUD_ACCESS_KEY_SECRET> regionId=cn-hangzhou endpoint=emr-serverless-spark.cn-hangzhou.aliyuncs.com workspaceId=w-xxxxxxxxxxxx重要該AccessKey對應的RAM使用者/角色帳號需要進行RAM授權並添加至對應的Serverless Spark工作空間中。
RAM授權,請參見RAM使用者授權。
Serverless Spark 工作空間使用者/角色管理,請參見系統管理使用者和角色。
涉及參數說明如下表所示。
參數
是否必填
說明
accessKeyId
是
執行Spark任務使用的阿里雲帳號或RAM使用者的AccessKey ID和AccessKey Secret。
重要在配置
accessKeyId和accessKeySecret參數時,請確保所使用的AccessKey所對應的使用者具有對工作空間綁定的OSS Bucket的讀寫權限。工作空間綁定的OSS Bucket,您可以在Spark頁面,單擊工作空間操作列的詳情進行查看。accessKeySecret
是
regionId
是
地區ID。本文以杭州地區為例。
endpoint
是
EMR Serverless Spark的Endpoint。地址詳情參見服務存取點。
本文以杭州地區公網訪問地址為例,參數值為
emr-serverless-spark.cn-hangzhou.aliyuncs.com。說明如果ECS執行個體沒有公網訪問能力,需要使用VPC地址。
workspaceId
是
EMR Serverless Spark工作空間ID。
步驟三:提交Spark任務
執行以下命令,進入EMR Serverless spark-submit工具目錄。
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT請根據任務類型選擇提交方式。
在提交任務時,需要指定任務依賴的檔案資源(如JAR包或Python指令碼)。這些檔案資源可以儲存在OSS上,也可以儲存在本地,具體選擇取決於您的使用情境和需求。本文均以OSS資源為例。
使用spark-submit方式
spark-submit是Spark提供的通用任務提交工具,適用於Java/Scala和PySpark類型的任務。Java/Scala類型任務
本文樣本使用的spark-examples_2.12-3.5.2.jar,您可以單擊spark-examples_2.12-3.5.2.jar,直接下載測試JAR包,然後上傳JAR包至OSS。該JAR包是Spark內建的一個簡單樣本,用於計算圓周率π的值。
說明spark-examples_2.12-3.5.2.jar必須與esr-4.x引擎版本結合使用以提交任務。如果您使用esr-5.x引擎版本提交任務,請下載spark-examples_2.13-4.0.1.jar以便進行本文的驗證。
./bin/spark-submit --name SparkPi \ --queue dev_queue \ --num-executors 5 \ --driver-memory 1g \ --executor-cores 2 \ --executor-memory 2g \ --class org.apache.spark.examples.SparkPi \ oss://<yourBucket>/path/to/spark-examples_2.12-3.5.2.jar \ 10000PySpark類型任務
本文樣本使用的DataFrame.py和employee.csv,您可以單擊DataFrame.py和employee.csv,直接下載測試檔案,然後上傳測試檔案至OSS。
說明DataFrame.py檔案是一段使用Apache Spark架構進行OSS上資料處理的代碼。
employee.csv檔案中定義了一個包含員工姓名、部門和薪水的資料列表。
./bin/spark-submit --name PySpark \ --queue dev_queue \ --num-executors 5 \ --driver-memory 1g \ --executor-cores 2 \ --executor-memory 2g \ --conf spark.tags.key=value \ oss://<yourBucket>/path/to/DataFrame.py \ oss://<yourBucket>/path/to/employee.csv相關參數說明如下:
相容的開源參數
參數名稱
樣本值
說明
--name
SparkPi
指定Spark任務的應用程式名稱,用於標識任務。
--class
org.apache.spark.examples.SparkPi
指定Spark任務的入口類名(Java或者Scala程式),Python程式無需此參數。
--num-executors
5
Spark任務的Executor數量。
--driver-cores
1
Spark任務的Driver核心數。
--driver-memory
1g
Spark任務的Driver記憶體大小。
--executor-cores
2
Spark任務的Executor核心數。
--executor-memory
2g
Spark任務的Executor記憶體大小。
--files
oss://<yourBucket>/file1,oss://<yourBucket>/file2
Spark任務需要引用的資源檔,可以是OSS資源,也可以是本地檔案,多個檔案使用逗號(,)分隔。
--py-files
oss://<yourBucket>/file1.py,oss://<yourBucket>/file2.py
Spark任務需要引用的Python指令碼,可以是OSS資源,也可以是本地檔案,多個檔案使用逗號(,)分隔。該參數僅對PySpark程式生效。
--jars
oss://<yourBucket>/file1.jar,oss://<yourBucket>/file2.jar
Spark任務需要引用的JAR包資源,可以是OSS資源,也可以是本地檔案,多個檔案使用逗號(,)分隔。
--archives
oss://<yourBucket>/archive.tar.gz#env,oss://<yourBucket>/archive2.zip
Spark任務需要引用的archive包資源,可以是OSS資源,也可以是本地檔案,多個檔案使用逗號(,)分隔。
--queue
root_queue
Spark任務啟動並執行隊列名稱,需與EMR Serverless Spark工作空間隊列管理中的隊列名稱保持一致。
--proxy-user
test
設定的值將覆蓋
HADOOP_USER_NAME環境變數,其行為與開源版本一致。--conf
spark.tags.key=value
Spark任務自訂參數。
--status
jr-8598aa9f459d****
查看Spark任務狀態。
--kill
jr-8598aa9f459d****
終止Spark任務。
非開源增強參數
參數名稱
樣本值
說明
--detach
無需填充
使用此參數,spark-submit將在提交任務後立即退出,不再等待或查詢任務狀態。
--detail
jr-8598aa9f459d****
查看Spark任務詳情。
--release-version
esr-4.1.1 (Spark 3.5.2, Scala 2.12)
指定Spark版本,請根據控制台展示的引擎版本號碼填寫。
--enable-template
無需填充
啟用模板功能,任務將使用工作空間的預設配置模板。
如果您在組態管理中建立了配置模板,可以通過在
--conf中指定spark.emr.serverless.templateId參數來指定模板ID,任務將直接應用指定的模板ID。有關建立模板的更多資訊,請參見組態管理。僅指定
--enable-template,任務將自動應用工作空間的預設配置模板。僅通過
--conf指定模板ID:任務將直接應用指定的模板ID。同時指定
--enable-template和--conf:如果同時指定了--enable-template和--conf spark.emr.serverless.templateId,則--conf中的模板ID會覆蓋預設範本。未指定任何參數:如果既未使用
--enable-template,也未指定--conf spark.emr.serverless.templateId,任務將不會應用任何模板配置。
--timeout
60
任務逾時時間,單位為秒。
--workspace-id
w-4b4d7925a797****
任務層級指定工作空間ID,可以覆蓋
connection.properties檔案中的workspaceId參數。不支援的開源參數
--deploy-mode
--master
--repositories
--keytab
--principal
--total-executor-cores
--driver-library-path
--driver-class-path
--supervise
--verbose
使用spark-sql方式
spark-sql是專門用於運行SQL查詢或指令碼的工具,適用於直接執行SQL的情境。樣本1:直接運行SQL語句
spark-sql -e "SHOW TABLES"該命令可以列出當前資料庫中的所有表。
樣本 2:運行SQL指令檔
spark-sql -f oss://<yourBucketname>/path/to/your/example.sql本文樣本使用的example.sql,您可以單擊example.sql,直接下載測試檔案,然後上傳測試檔案至OSS。
相關參數說明如下表所示。
參數名稱
樣本值
說明
-e "<sql>"-e "SELECT * FROM table"直接在命令列中內聯執行SQL語句。
-f <path>-f oss://path/script.sql執行指定路徑的SQL指令檔。
步驟四:查詢Spark任務
CLI方式
查詢Spark任務狀態
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --status <jr-8598aa9f459d****>查詢Spark任務詳情
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --detail <jr-8598aa9f459d****>UI方式
在EMR Serverless Spark頁面,單擊左側導覽列中的任務歷史。
在任務歷史的開發工作單位頁簽,您可以查看提交的任務。
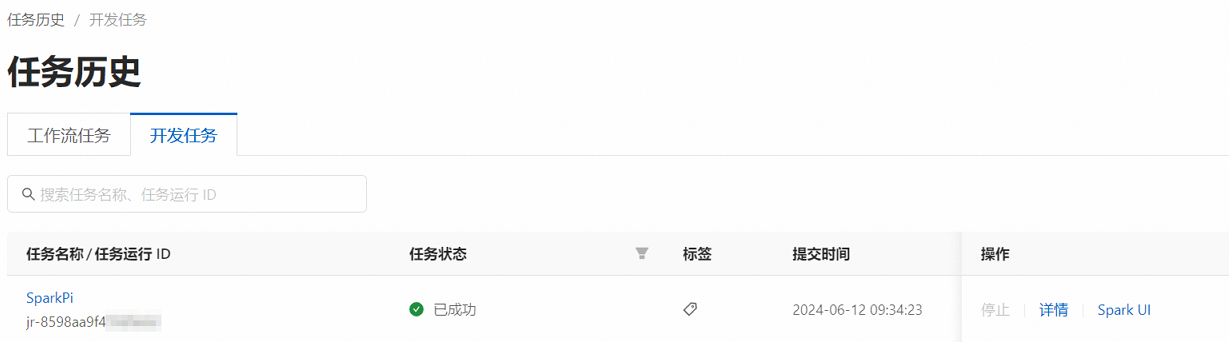
(可選)步驟五:終止Spark任務
cd emr-serverless-spark-tool-0.11.3-SNAPSHOT
./bin/spark-submit --kill <jr-8598aa9f459d****>僅能終止處於運行狀態(running)的任務。
常見問題
使用Spark-Submit工具提交批任務時,如何指定網路連接?
先準備網路連接,詳情見新增網路連接。
在spark-submit命令中通過
--conf指定網路連接。--conf spark.emr.serverless.network.service.name=<networkname><networkname>替換為您的實際串連名稱即可。