本文介紹YARN調度器。
簡介
Hadoop YARN的核心組件是ResourceManager,負責叢集資源管理與調度,而ResourceManager組件的核心是調度器,負責統籌叢集資源,滿足應用的資源需求。調度器不僅需要最佳化整個叢集的資源布局,避免熱點等問題對應用的影響,最大程度利用叢集資源;還要能協調好大量應用在叢集的運行,基於多租戶(隊列)公平性、應用優先順序等策略解決好資源競爭等問題;也要能滿足個別應用在節點依賴、放置策略等方面的特殊需求。
YARN調度器是可插拔的外掛程式,主要有FIFOScheduler、FairScheduler和CapacityScheduler三種。
FIFOScheduler:是最簡單的調度器,不支援多租戶(所有應用都提交到Default隊列),不考慮叢集的資源分布(節點上堆疊調度),只支援以FIFO(First In, First Out)策略依次調度應用,無其他控制與調度特性。只適用於極其簡單的情境,因此很少應用於正式生產。
FairScheduler:是CDH(Cloudera Distributed Hadoop)的預設調度器,與HDP(Hortonworks Data Platform)合并後的CDP(Cloudera Data Platform)不再使用(遷移到CapacityScheduler),Apache Hadoop社區也建議遷移到CapacityScheduler。FairScheduler支援較為完善的多租戶管理與資源調度能力,包括多級隊列、配額管理、ACL控制、彈性資源共用、租戶間公平性調度策略、租戶內應用調度策略、資源預留、搶佔、非同步調度等,然而在Apache Hadoop社區的發展相比CapacityScheduler仍稍顯落後,核心調度未考慮整個叢集的資源布局,也不支援Node Labels(分區調度)、Node Attributes(節點打標調度)、Placement Constraints(放置約束)等調度特性。
CapacityScheduler:是Apache Hadoop社區、HDP(Hortonworks Data Platform)及合并後CDP(Cloudera Data Platform)的預設調度器,具有最完善的多租戶管理與資源調度能力,不僅包含了FairScheduler的全部能力,還能協調整個叢集的資源布局(基於Global Scheduling),減少熱點機率,最大程度利用叢集資源,還支援Node Labels(分區調度)、Node Attributes(節點打標調度)、Placement Constraints(放置約束)等調度特性。
因此,EMR YARN推薦並預設使用CapacityScheduler,下面重點對CapacityScheduler進行介紹,其他調度器的使用說明請參考社區文檔。
基礎架構&核心流程
CapacityScheduler的主調度流程有三種觸發方式:
節點心跳驅動(Node-Heartbeat Driven):是面向節點的局部調度(當調度器收到每個節點心跳時觸發,為當前節點選擇可調度的應用),受限於心跳間隔時間與接近隨機調度,可能有較大比例的節點調度因資源不足、調度需求不滿足等原因未命中,調度效率較差。通常適用於調度效能和調度功能要求都不高的叢集。
非同步調度(Async Scheduling):由獨立的非同步調度線程觸發(支援多線程),每輪調度從節點列表中隨機挑選一個節點開始,調度效能較高。通常適用於調度效能要求較高、調度功能要求不高的叢集。
全域調度(Global Scheduling):由獨立的全域調度線程觸發,是面嚮應用的全域調度。每輪調度考慮多租戶公平性、應用優先順序等因素依次選擇應用,根據應用的資源大小、調度需求、資源分布等因素從叢集中挑選最合適的節點,從而作出相對更優的調度決策。適用於調度效能和調度功能要求都較高的叢集。
下圖是基於YARN v3.2+全域調度的基礎架構: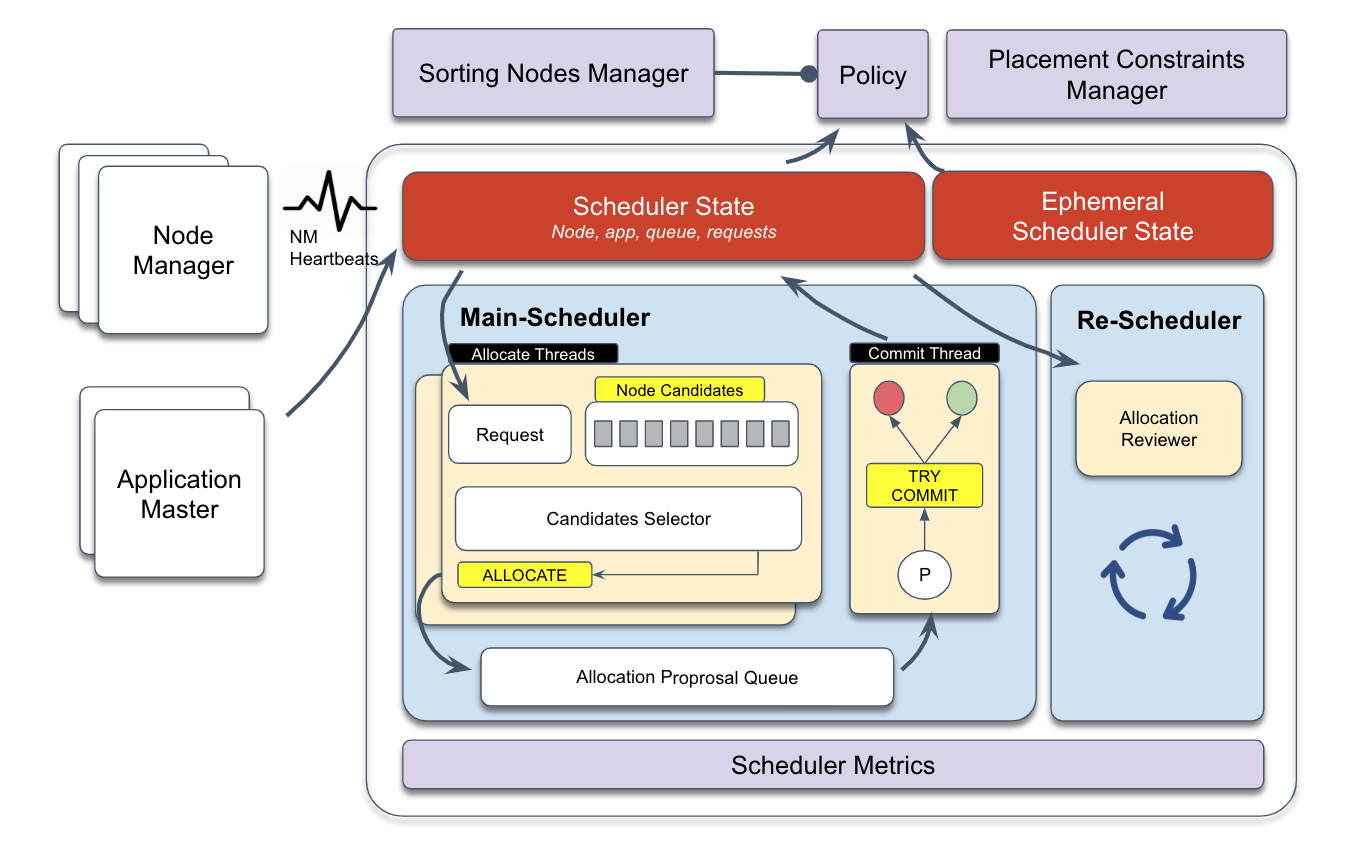
主調度(MainScheduler):是基於資源請求的非同步多執行緒架構,內部包含分配線程和提交線程,一個或多個分配線程負責定位優先順序最高的資源請求,根據其資源大小及擺放約束批量選擇合適的候選節點,產生分配提案放入中間隊列,由單個提交線程進行消費,重新檢查各種約束後成功提交或駁回,同時更新調度器狀態。
重調度(ReScheduler):是周期性啟動並執行動態資源監測架構,內部有多個資源監測策略,包括隊列間搶佔、隊列內搶佔和預留資源搶佔等。
節點排序管理器(Nodes Sorting Manager)與放置約束管理器(Placement Constraints Manager):是主調度架構中全域調度(Global Scheduling)的擴充外掛程式,針對主調度架構中的負載平衡和複雜擺放約束功能的擴充外掛程式。
CapacityScheduler全域調度模式的主要流程如下: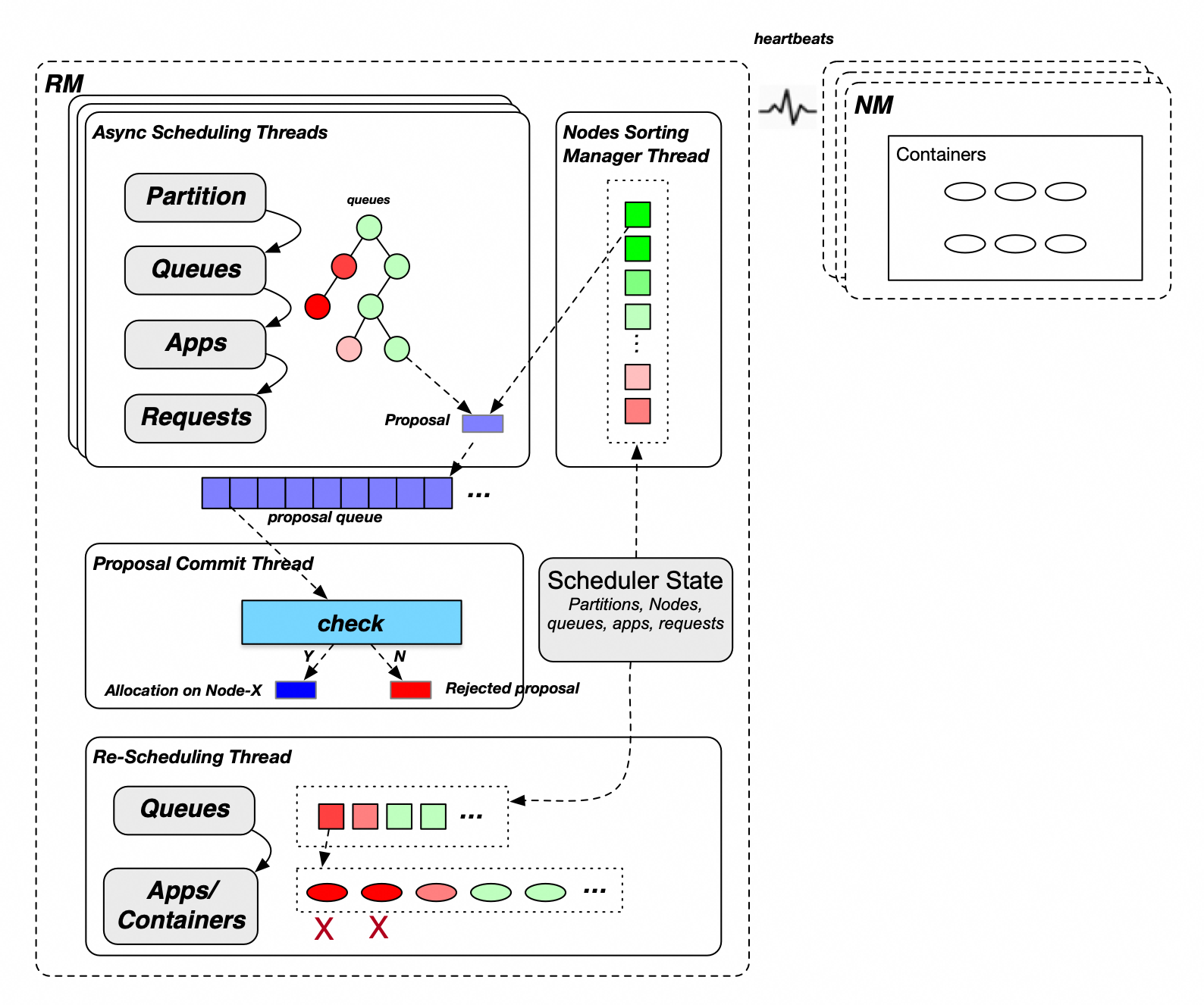
主調度分配流程:
選擇Partition(node label):叢集可能存在一個或多個Partition,多個Partition之間輪流進行分配。
選擇Leaf Queue:從頂層Root Queue開始逐層深入,同一層級的子Queue按保障資源使用比例從低到高順序依次遍曆,直到鎖定Leaf Queue。(如上圖中的樹狀圖,紅色表示GUARANTEED資源使用率較高,綠色表示GUARANTEED資源使用率較低,優先為綠色狀態的Queue分配資源)。
選擇App:Queue內部App選擇支援Fair與FIFO兩種策略,其中Fair策略支援按已指派記憶體資源(從小到大)的順序依次選擇,FIFO策略支援按應用優先順序(從高到低)和應用ID(從小到大)的順序依次選擇。
選擇Request:根據Request優先順序依次選擇。
選擇Sorted Candidate Nodes:根據Request擺放約束條件從排序好的全部Nodes篩選出符合資源請求需求的Candidate Nodes。
遍曆Candidate Nodes並試圖為每個Node分配一個Container,分配過程需檢查queue/node的allocated/used/unconfirmed資源,檢查通過後產生一個Allocation Proposal,放入Proposal Queue。
主調度提交流程:單獨的提交線程從Proposal Queue中取出Allocation Proposal進行最終校正,重新檢查應用需求、節點資源、放置約束條件等是否仍然滿足,不通過直接丟棄,通過後本次分配正式生效(應用或節點資源更新)。
重調度搶佔流程:當叢集整體資源緊張(超出一定水位)且有應用資源請求未滿足時,重調度流程將從多個維度考慮實施搶佔,包括:
隊列間搶佔:YARN允許隊列未用完的GUARANTEED資源(Capacity以內是GUARANTEED資源)被其他隊列共用使用(Capacity ~ max-capacity部分是共用資源),因此當GUARANTEED資源未滿足的隊列下面的應用有資源需求,但叢集無空閑資源時需要觸發隊列間搶佔。
隊列內搶佔:根據隊列的分配配置策略(FIFO或Fair)監測並調整應用資源公平性,當高優先順序應用有資源需求但隊列資源用滿時需要觸發隊列內搶佔。
預留任務搶佔:當預留任務滿足一定條件(例如逾時未分配完成)時釋放預留任務及被其佔用的資源。
主要特性
CapacityScheduler具備如下的特性:
多級隊列(樹形結構):支援多級租戶管理,父隊列資源配額能夠限制其下所有子隊列的資源使用,單個子隊列的資源配額也不能超過父隊列的資源配額,因此對於多租戶管理具備較高的可控性,能夠滿足各種複雜應用情境的需求。
資源配額:每個隊列都需配置Capacity與MaxCapacity資源,其中Capacity指的是保障資源,MaxCapacity是最大可用資源。 除了資源維度配額,還可以為隊列配置運行應用數上限、AM資源使用最大比例、使用者資源使用比例等,從應用、任務類型、使用者等多個維度進行控制。
彈性資源共用:隊列的彈性資源量=(MaxCapacity - Capacity),叢集與父隊列有空閑資源時,子隊列可以利用其他隊列的空閑(未被使用)保障資源,從而支援不同隊列資源分時複用,提升叢集的資源使用率。
ACL控制:每個隊列均可以支援較為嚴格的許可權控制,可以指定允許提交和管理工作的使用者,可以配置相同使用者管理多個隊列。
租戶間公平性調度策略:租戶間公平性是指對處於同一層級的隊列(父隊列相同),調度時按各個隊列保障資源的使用比例從低到高的順序進行,優先滿足保障資源用量少的隊列的資源使用需求。如果配置了隊列優先順序,同一層級的隊列首先將分為兩組,保障組(已使用資源小於等於保障資源)與超用組(已使用資源大於保障資源),調度時優先為保障組分配資源,兩組內部的所有隊列再按優先順序從大到小、保障資源使用比例從小到大進行排序,依次為其分配資源。
租戶內應用調度策略:租戶內應用調度策略主要包括FIFO與Fair兩種,FIFO即先入先出調度,對所有應用按優先順序從高到低、提交時間從前往後的順序排序,Fair是公平調度,對所有應用按資源使用比例從小到大、提交時間從前往後的順序排序。
搶佔:運行時叢集的資源一直變化,為了保障彈性資源共用、租戶間公平性調度策略與租戶內應用調度策略的要求,需要依賴搶佔流程來平衡各隊列、各應用的資源使用。
配置與使用說明
全域配置
設定檔 | 配置項 | (推薦)配置值 | 說明 |
yarn-site.xml | yarn.resourcemanager.scheduler.class | 不配置(預設使用CapacityScheduler)。 | Scheduler外掛程式類,預設值:org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler。 |
capacity-scheduler.xml | yarn.scheduler.capacity.maximum-applications | 不配置(預設10000)。 | 叢集可同時啟動並執行最大應用數,預設值:10000。 |
yarn.scheduler.capacity.global-queue-max-application | 不配置 (按Capacity占叢集總資源的比例折算,如果有非常規需求的多個隊列,如Capacity配置很小但應用數很多,可以更新該配置項)。 | 隊列預設可同時啟動並執行最大應用數。如果未配置,則將叢集同時啟動並執行最大應用數按比例分配到每個隊列,即:每個隊列下可同時啟動並執行最大應用數 = queueCapacity/clusterResource * ${yarn.scheduler.capacity.maximum-applications}。 | |
yarn.scheduler.capacity.maximum-am-resource-percent | 0.25 | 隊列預設的AM可用比例,即隊列內所有應用的AM佔用資源量不得超過(該配置項值 * 隊列Max-Capacity),預設值:0.1(若隊列內小應用較多,AM Container佔比較高,會導致可運行應用數受限,因此可適當調大)。 | |
yarn.scheduler.capacity.resource-calculator | org.apache.hadoop.yarn.util.resource.DominantResourceCalculator | 資源計算類,用於隊列、節點、應用的各類資源運算(影響調度器的各個環節),預設為org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator,只考慮記憶體資源(不考慮CPU資源)。另外有org.apache.hadoop.yarn.util.resource.DominantResourceCalculator可選,預設同時考慮配置的全部資源類型(包括記憶體、CPU和其他自訂資源類型,使用最多的為主資源)。 說明 該配置項的更新需在ResourceManager重啟或HA切換主節點後生效。(執行refreshQueues操作將不產生效果。) | |
yarn.scheduler.capacity.node-locality-delay | -1 | 考慮節點本地化而延遲調度的次數,預設值:40,通常用於Hadoop早期調度時重度依賴本機存放區的情境(將任務分配到依賴資料所在的節點),隨著網路與儲存的發展,磁碟與網路不再是主要瓶頸,因此一般應用都不需再考慮本地化問題,建議配置為-1,可大幅提升調度效能。 |
節點調度配置
節點心跳驅動模式
配置集 | 配置項 | (推薦)配置值 | 說明 |
capacity-scheduler.xml | yarn.scheduler.capacity.per-node-heartbeat.multiple-assignments-enabled | false | 開啟一次心跳可分配多個Container,預設值為true。鑒於其對整個叢集負載平衡的顯著影響(容易導致熱點問題),建議關閉此功能。 |
yarn.scheduler.capacity.per-node-heartbeat.maximum-container-assignments | 不配置 | 一次心跳可分配的最大數量為100,預設值為100,僅在啟用一次心跳分配多個Container時有效。 | |
yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments | 不配置 | 一次心跳所分配的最大非局部性分配數量,僅在啟用一次心跳分配多個Container時有效。 |
非同步調度
配置集 | 配置項 | (推薦)配置值 | 說明 |
capacity-scheduler.xml | yarn.scheduler.capacity.schedule-asynchronously.enable | true | 非同步調度是否開啟,預設值為false。建議開啟此功能以提升調度效能。 |
yarn.scheduler.capacity.schedule-asynchronously.maximum-threads | 1 (或不配置) | 獨立的非同步調度線程數,預設值為1。多個分配線程可能會導致大量重複的proposal,通常情況下,一個分配線程已經能夠提供較高的調度效能,因此不建議進行額外配置。 | |
yarn.scheduler.capacity.schedule-asynchronously.maximum-pending-backlogs | 不配置 | 非同步調度隊列中等待提交的分配提案最大數量,預設值為100。在叢集規模較大時,可以適當增加此配置值。 |
全域調度
全域調度的配置應包含上述所有非同步調度配置項,下面的表格中將不再重複列出。
配置集 | 配置項 | (推薦)配置值 | 說明 |
capacity-scheduler.xml | yarn.scheduler.capacity.multi-node-placement-enabled | true | 是否啟用全域調度(面向多節點分配),預設值為false。對於調度效能和調度功能要求較高的叢集,可以選擇啟用該功能。 |
yarn.scheduler.capacity.multi-node-sorting.policy | default | 全域調度預設策略名稱。 | |
yarn.scheduler.capacity.multi-node-sorting.policy.names | default | 全域調度策略名稱稱集合。支援多個名稱,以逗號分隔。 | |
yarn.scheduler.capacity.multi-node-sorting.policy.default.class | org.apache.hadoop.yarn.server.resourcemanager.scheduler.placement.ResourceUsageMultiNodeLookupPolicy | 全域調度預設策略default的節點排序策略實作類別(社區唯一實作類別,基於節點已指派的資源絕對值從小到大排序)。 | |
yarn.scheduler.capacity.multi-node-sorting.policy.default.sorting-interval.ms |
| 全域調度預設策略 default 的緩衝重新整理間隔。 根據叢集規模決定是否啟用節點緩衝:
預設值:1000 (配置值必須大於等於0,配置為0時等於同步排序,大規模叢集時同步排序對效能影響大) |
節點分區配置
更多內容,請參見Node Labels特性使用。
隊列基礎配置
隊列基礎配置包括隊列的層級關係、Capacity與MaxCapacity配置。假如一個YARN叢集同時被公司多個組織、團隊共用使用,我們可以根據具體的組織方式及預期資源佔比來規劃YARN隊列,如下圖所示,一級隊列包括dev、test、support、default四個隊列,保障資源比例分別是50%、30%、10%和10%,最大資源比例分別是100%、50%、30%、100%,其中dev隊列下級分為training和services,保障資源比例分別是40%和60%,最大資源比例都是100%。
相關配置如下表。
配置集 | 配置項 | (樣本)配置值 | 說明 |
capacity-scheduler.xml | yarn.scheduler.capacity.root.queues | dev,test,support,default | Root子隊列,多個隊列時以英文半形逗號(,)分隔。 |
yarn.scheduler.capacity.root.dev.capacity | 50 | Root.dev隊列保障資源百分比(相對於叢集資源)。 | |
yarn.scheduler.capacity.root.dev.maximum-capacity | 100 | Root.dev隊列最大可用資源百分比(相對於叢集資源)。 | |
yarn.scheduler.capacity.root.dev.queues | training,services | Root.dev隊列的子隊列。 | |
yarn.scheduler.capacity.root.dev.training.capacity | 40 | Root.dev.training隊列保障資源百分比(相對於Root.dev保障資源)。 | |
yarn.scheduler.capacity.root.dev.training.maximum-capacity | 100 | Root.dev.training隊列最大資源百分比(相對於Root.dev最大資源)。 | |
yarn.scheduler.capacity.root.dev.services.capacity | 60 | Root.dev.services隊列保障資源百分比(相對於Root.dev保障資源)。 | |
yarn.scheduler.capacity.root.dev.services.maximum-capacity | 100 | Root.dev.services隊列最大資源百分比(相對於Root.dev最大資源)。 | |
yarn.scheduler.capacity.root.test.capacity | 30 | Root.test隊列保障資源百分比(相對於叢集資源)。 | |
yarn.scheduler.capacity.root.test.maximum-capacity | 50 | Root.test隊列最大可用資源百分比(相對於叢集資源)。 | |
yarn.scheduler.capacity.root.support.capacity | 10 | Root.support隊列保障資源百分比(相對於叢集資源)。 | |
yarn.scheduler.capacity.root.support.maximum-capacity | 30 | Root.support隊列最大可用資源百分比(相對於叢集資源)。 | |
yarn.scheduler.capacity.root.default.capacity | 10 | Root.default隊列保障資源百分比(相對於叢集資源)。 | |
yarn.scheduler.capacity.root.default.maximum-capacity | 100 | Root.default隊列最大可用資源百分比(相對於叢集資源)。 |
YARN Scheduler頁面的樹狀列表能夠顯示各個隊列的層級結構及其保障資源與最大資源。如下圖所示,灰色框代表各隊列的最大資源百分比,其中的虛線框代表隊列的保障資源百分比(均相對於叢集總資源),葉子隊列展開能看到它的詳細資料,如隊列狀態、各種資源資訊(所有Application Master跟User的已使用、配置、實際生效、資源、百分比等)、應用資訊(應用數、任務數等)與配置資訊(最大應用數、使用者最大應用數、NodeLabels、是否開啟搶佔、預設應用優先順序等)。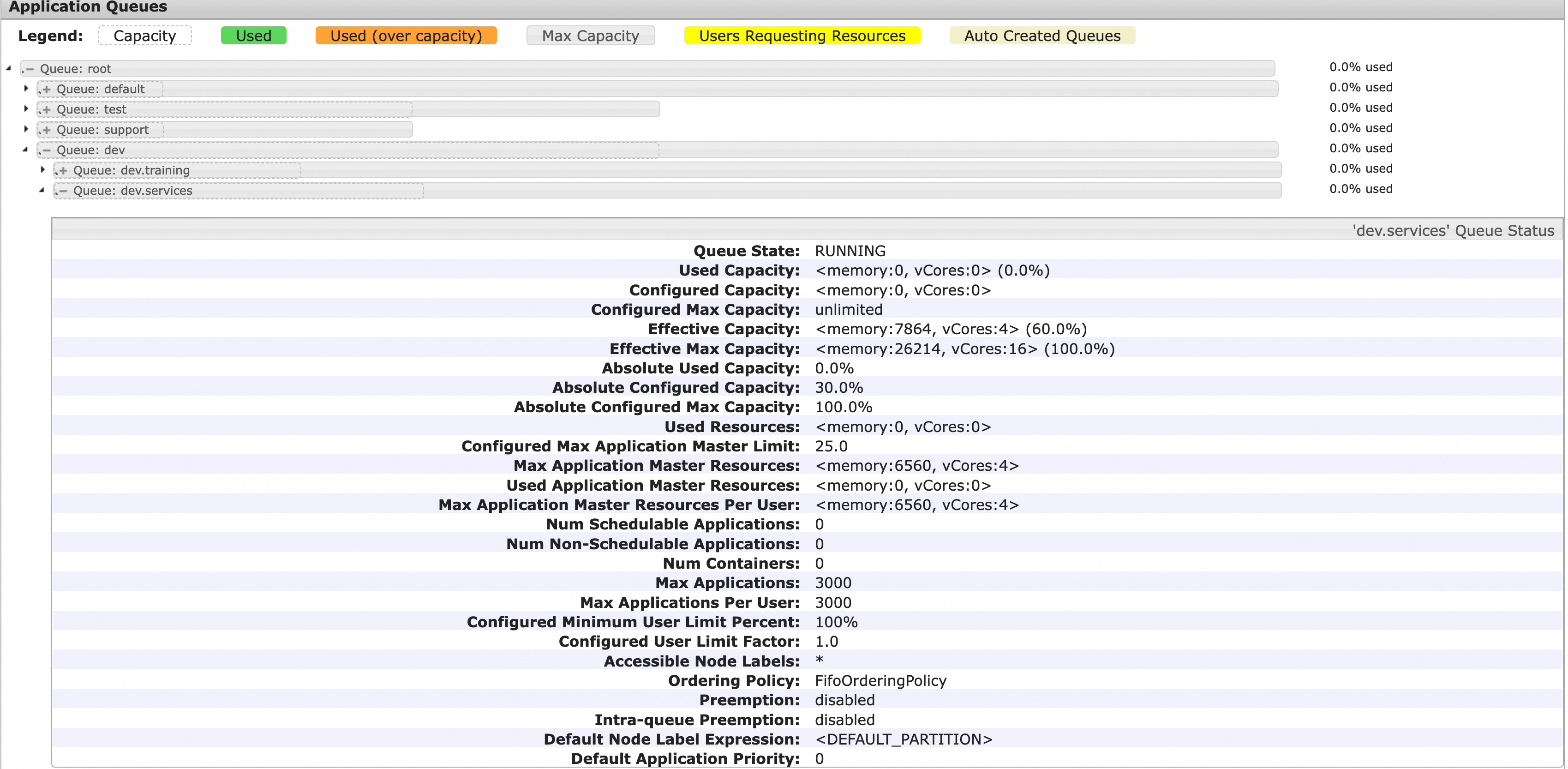
隊列進階配置
配置集 | 配置項 | (推薦)配置值 | 說明 |
capacity-scheduler.xml | yarn.scheduler.capacity.<queue_path>.ordering-policy | fair | 指定隊列內應用調度策略,包括fifo與fair兩種,fifo即先入先出調度,對所有應用按優先順序從高到低、提交時間從前往後的順序排序,fair是公平調度,對所有應用按資源使用比例從小到大、提交時間從前往後的順序排序。預設值:fifo, 一般應用情境配置成fair更合適。 |
yarn.scheduler.capacity.<queue-path>.ordering-policy.fair.enable-size-based-weight | 不配置 | 基於權重的fair調度策略(啟用fair調度策略時是否考慮應用需求),預設值:false。false表示按Used資源值從小到大排序, true表示按照(used/demand)計算值從小到大排序,可在資源競爭時盡量避免資源較多的大應用資源告急。 | |
yarn.scheduler.capacity.<queue_path>.state | 不配置 | 指定隊列狀態,預設值:RUNNING。通常不需要配置,只有在需要刪除隊列的時候,修改指定隊列的狀態為STOPPED,待隊列下應用全部結束後隊列將會被自動刪除。 | |
yarn.scheduler.capacity.<queue_path>.maximum-am-resource-percent | 不配置 | 隊列預設的AM可用比例,即隊列內所有應用的AM佔用資源量不得超過(該配置項值 * 隊列max-capacity),預設值:${yarn.scheduler.capacity.maximum-am-resource-percent}。 | |
yarn.scheduler.capacity.<queue_path>.user-limit-factor | 不配置 | 指定隊列內單個使用者的資源上限因子,隊列內單個使用者最大可用資源=min(隊列最大資源, 隊列保障資源 * userLimitFactor),預設值:1.0。 | |
yarn.scheduler.capacity.<queue_path>.minimum-user-limit-percent | 不配置 | 指定隊列內單個使用者的最小資源比例(相對於隊列保障資源),隊列內單個使用者的資源限制=max(隊列保障資源/使用者數, 隊列保障資源 * minimumUserLimitPercent / 100), 預設值:100。 | |
yarn.scheduler.capacity.<queue_path>.maximum-applications | 不配置 | 指定隊列最大運行應用數,若不配置,則隊列最大運行應用數 = 隊列保障資源比例 * ${yarn.scheduler.capacity.maximum-applications}。 | |
yarn.scheduler.capacity.<queue_path>.acl_submit_applications | 不配置 | 指定隊列的應用提交ACL,不配置則繼承上級隊列的配置,Root隊列預設允許全部使用者。 | |
yarn.scheduler.capacity.<queue_path>.acl_administer_queue | 不配置 | 指定隊列的管理ACL,不配置則繼承上級隊列的配置,Root隊列預設允許全部使用者。 |
隊列ACL配置
隊列ACL相關配置如下,一般情況可以不開啟ACL控制,後續有相應的情境需求再開啟。
配置集 | 配置項 | (推薦)配置值 | 說明 |
yarn-site.xml | yarn.acl.enabled | 不配置 | 是否開啟ACL,預設值:false。 |
capacity-scheduler.xml | yarn.scheduler.capacity.<queue_path>.acl_submit_applications | 不配置 | 指定隊列的應用提交ACL,不配置則繼承上級隊列的配置,Root隊列預設允許全部使用者。 |
yarn.scheduler.capacity.<queue_path>.acl_administer_queue | 不配置 | 指定隊列的管理ACL,不配置則繼承上級隊列的配置,Root隊列預設允許全部使用者。 |
父隊列的ACL配置能對所有子隊列生效。例如,只配置了root.default隊列允許hadoop使用者提交作業,其他使用者仍然能夠向root.default隊列提交應用,因為Root預設允許所有使用者提交與管理隊列,因此使用隊列的ACL,必須先將Root隊列的ACL配置設定都不允許:yarn.scheduler.capacity.root.acl_submit_applications=<space>, yarn.scheduler.capacity.root.acl_administer_queue=<space> 。
提交應用和轉移應用(到其他Queue)的ACL許可權不是只由配置項yarn.scheduler.capacity.<queue_path>.acl_submit_applications管理,在yarn.scheduler.capacity.<queue_path>.acl_administer_queue中配置的相關組或使用者也具備提交應用(轉移應用)許可權。
搶佔配置
搶佔是為了保證多租戶公平性、應用優先順序等需求的運行時重調度,對調度要求較高的叢集可以選擇開啟搶佔(v2.8.0+版本支援),相關配置項如下:
配置集 | 配置項 | (推薦)配置值 | 說明 |
yarn-site.xml | yarn.resourcemanager.scheduler.monitor.enable | true | 搶佔功能總開關。 |
capacity-scheduler.xml | yarn.resourcemanager.monitor.capacity.preemption.intra-queue-preemption.enabled | true | 隊列內搶佔開關(隊列間搶佔無開關,預設開啟)。 |
yarn.resourcemanager.monitor.capacity.preemption.intra-queue-preemption.preemption-order-policy | priority_first | 搶佔策略優先考慮應用優先順序,預設值:userlimit_first。 | |
yarn.scheduler.capacity.<queue-path>.disable_preemption | true | 指定隊列不可被搶佔,不配置則預設使用上級隊列的配置,例如給root隊列配置為true,則所有子隊列均不可搶佔(root隊列不配置則預設為false,即可以被搶佔)。 | |
yarn.scheduler.capacity.<queue-path>.intra-queue-preemption.disable_preemption | true | 指定隊列禁用隊列內搶佔,不配置則預設使用上級隊列的配置,例如給root隊列配置為true,則所有子隊列均禁用隊列內搶佔。 |
REST API管理capacity-scheduler.xml配置
capacity-scheduler.xml組態管理原本只支援RPC調用RefreshQueues介面,每次調用需基於全量配置內容,且無法擷取當前更新生效的配置項,從v3.2.0版本開始支援REST API介面累加式更新和查看capacity-scheduler.xml當前已生效的全部配置,極大地方便了隊列管理。
如需啟用,可參考以下配置項:
配置集 | 配置項 | (推薦)配置值 | 說明 |
yarn-site.xml | yarn.scheduler.configuration.store.class | fs | 使用FileSystem類型儲存。 |
yarn.scheduler.configuration.max.version | 100 | 保留歷史版本的最大數量(超出自動清理:FIFO)。 | |
yarn.scheduler.configuration.fs.path | /yarn/<叢集名>/scheduler/conf | Capacity-scheduler.xml檔案儲存體路徑(不存在則自動建立,不指定首碼則預設DefaultFs相對路徑)。 重要 將<叢集名>替換為叢集名稱以便區分(可能有多個YARN叢集對應同一分布式儲存)。 |
啟用後查看capacity-scheduler.xml配置的方式:
REST API:http://<rm-address>/ws/v1/cluster/scheduler-conf。
HDFS檔案:${yarn.scheduler.configuration.fs.path}/capacity-scheduler.xml.<timestamp>,<timestamp>最大的是最新配置。
更新配置樣本:
更新一個配置項yarn.scheduler.capacity.maximum-am-resource-percent=0.2,並刪除一個配置項yarn.scheduler.capacity.xxx,刪除某配置項只需去掉參數值。
curl -X PUT -H "Content-type: application/json" 'http://<rm-address>/ws/v1/cluster/scheduler-conf' -d ' { "global-updates": [ { "entry": [{ "key":"yarn.scheduler.capacity.maximum-am-resource-percent", "value":"0.2" },{ "key":"yarn.scheduler.capacity.xxx" }] } ] }'
單任務/容器(Container)資源限制
單任務/容器(Container)的資源限制由以下調度器或隊列配置項決定:
配置集 | 配置項 | 配置說明 | 預設值/規則 |
yarn-site.xml | yarn.scheduler.maximum-allocation-mb | 叢集級最大可調度記憶體資源,單位MiB。 | EMR預設值為:建立叢集時最大非Master執行個體組的可用記憶體(與最大執行個體組的 yarn.nodemanager.resource.memory-mb配置值相同)。 |
yarn.scheduler.maximum-allocation-vcores | 叢集級最大可調度CPU資源,單位VCore。 | EMR預設值為32。 | |
capacity-scheduler.xml | yarn.scheduler.capacity.<queue-path>.maximum-allocation-mb | 指定隊列的最大可調度記憶體資源,單位MiB。 | 預設未配置,配置則覆蓋叢集級配置,僅對指定隊列生效。 |
yarn.scheduler.capacity.<queue-path>.maximum-allocation-vcores | 指定隊列的最大可調度CPU資源,單位VCore。 | 預設未配置,配置則覆蓋叢集級配置,僅對指定隊列生效。 |
如果申請資源超過單任務/容器(Container)最大可用資源配置,則在應用日誌中能夠發現以下異常資訊:InvalidResourceRequestException: Invalid resource request… 。