Celeborn是一個處理中間資料的服務,能夠提升巨量資料引擎的穩定性、靈活性和效能。本文為您介紹如何使用Celeborn服務。
背景資訊
目前Shuffle方案的缺點如下:
Shuffle Write在巨量資料量情境下會溢出,導致寫放大。
Shuffle Read過程中存在大量的網路小包導致的Connection reset問題。
Shuffle Read過程中存在大量小資料量的IO請求和隨機讀,對磁碟和CPU造成高負載。
對於M*N次的串連數,在M和N數千的規模下,作業基本無法完成。
NodeManager和Spark Shuffle Service是同一進程,當Shuffle的資料量特別大時,通常會導致NodeManager重啟,從而影響YARN調度的穩定性。
Celeborn服務可以最佳化目前Shuffle方案的問題。Celeborn優勢如下:
使用Push-Style Shuffle代替Pull-Style,減少Mapper的記憶體壓力。
支援IO彙總,Shuffle Read的串連數從M*N降到N,同時將隨機讀更改為順序讀。
支援兩副本機制,降低Fetch Fail機率。
支援計算與儲存分離架構,可以部署Shuffle Service至特殊硬體環境中,與計算叢集分離。
解決Spark on Kubernetes時對本地磁碟的依賴。
Celeborn設計架構圖如下。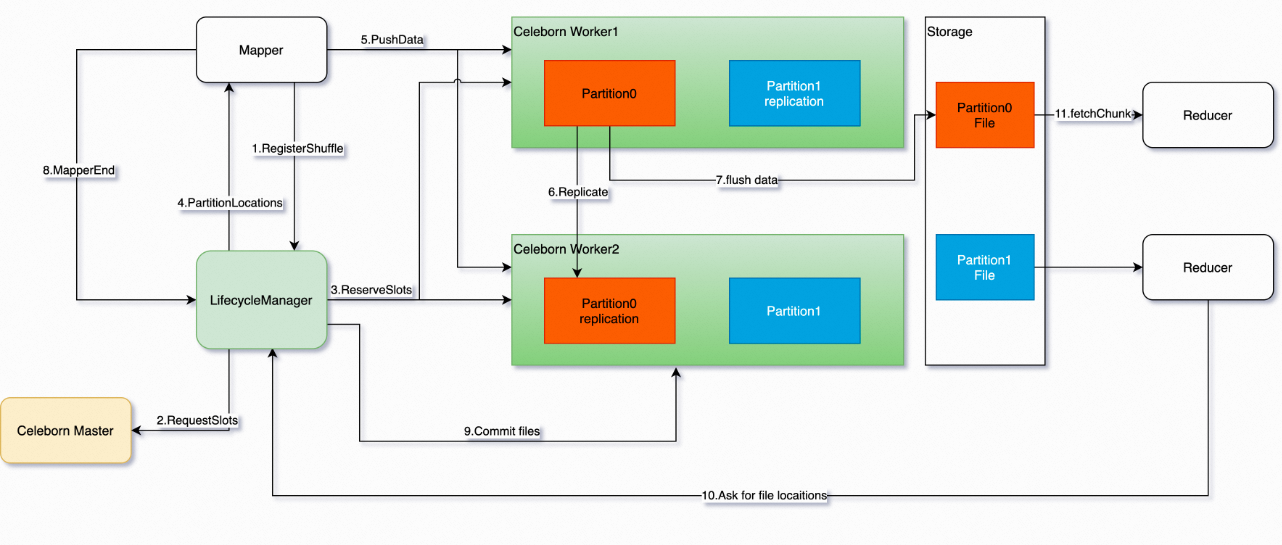
前提條件
已建立E-MapReduce的DataLake叢集或自訂叢集,並選擇Celeborn服務。建立叢集詳情請參見建立叢集。
使用限制
此文檔僅適用於以下版本的叢集。
叢集 | 版本 |
DataLake叢集 | EMR-3.45.0及後續版本,EMR-5.11.0及後續版本。 |
自訂叢集 | EMR-3.45.0及後續版本,EMR-5.11.0及後續版本。 |
操作步驟
Spark配置
參數 | 描述 |
spark.shuffle.manager |
|
spark.serializer | 固定值為org.apache.spark.serializer.KryoSerializer。 |
spark.celeborn.push.replicate.enabled | 是否開啟兩副本。取值如下:
|
spark.shuffle.service.enabled | 需修改為false,才會使用Celeborn。 使用Celeborn時需要關閉原有的External Shuffle Service。在使用Celeborn的情況下,是可以正常使用Spark的Dynamic Allocation的。 說明
|
spark.celeborn.shuffle.writer | Celeborn的wirter支援的模式:
|
spark.celeborn.master.endpoints | 填寫格式<celeborn-master-ip>:<celeborn-master-port>。 涉及參數如下:
高可用叢集時配置所有Master節點的IP地址。 |
spark.sql.adaptive.enabled | Celeborn支援Adaptive Execution,關閉Local Shuffle Reader可以獲得最佳的Shuffle效能。 各參數值需要修改為true、false和true。 |
spark.sql.adaptive.localShuffleReader.enabled | |
spark.sql.adaptive.skewJoin.enabled |
Spark服務支援一鍵配置使用Celeborn服務。
EMR-5.11.1及之後版本,EMR-3.45.1及之後版本
可以在Spark服務狀態頁面的服務概述地區,開啟或關閉enableCeleborn開關。
EMR-5.11.0版本,EMR-3.45.0版本
可以在Spark服務狀態頁面的組件列表地區,選擇SparkThriftServer操作列的
 > enableCeleborn或 > disableCeleborn。選擇後會自動修改上文表格中的Spark配置項並重啟SparkThriftServer,同時會修改spark-defaults.conf和spark-thriftserver.conf兩個設定檔。
> enableCeleborn或 > disableCeleborn。選擇後會自動修改上文表格中的Spark配置項並重啟SparkThriftServer,同時會修改spark-defaults.conf和spark-thriftserver.conf兩個設定檔。選擇
> enableCeleborn,所有的Spark任務都使用Celeborn服務。選擇
> disableCeleborn,所有的Spark任務都不使用Celeborn服務。
Celeborn配置
您可以在Celeborn服務配置頁面,修改或查看Celeborn所有的配置項。
針對不同的節點群組(例如CORE或TASK)各配置項的值是不同的。
參數 | 描述 | 預設值 |
celeborn.worker.flusher.threads | 磁碟(HDD或者SSD)的刷盤線程數。 |
|
CELEBORN_WORKER_OFFHEAP_MEMORY | Worker堆外記憶體大小。 | 根據叢集配置自動計算。 |
celeborn.application.heartbeat.timeout | Application心跳逾時時間,逾時會清理Application相關資源。 | 120s |
celeborn.worker.flusher.buffer.size | Flush buffer大小,超過最大值會觸發刷盤。 | 256K |
celeborn.metrics.enabled | 是否開啟監控。取值如下:
| true |
CELEBORN_WORKER_MEMORY | Worker堆內記憶體大小。 | 1g |
CELEBORN_MASTER_MEMORY | Master堆內記憶體大小。 | 2g |
重啟Celeborn組件
在Celeborn服務的狀態頁面,選擇CelebornMaster組件操作列的
> restart_clean_meta。說明如果是非高可用叢集,您也可以單擊CelebornMaster組件操作列的重啟。
在彈出的對話方塊中,關閉滾動執行開關,輸入執行原因,單擊確定。
在彈出的對話方塊中,單擊確定。