本文為您介紹Delta Lake CDC功能的相關參數、Schema和使用樣本。
背景資訊
CDC(Change Data Capture)定義了一種情境,即識別並捕獲資料庫表中資料的變更,並交付給下遊進一步處理。Delta Lake CDC能夠將Delta Lake表作為Source,直接擷取變更的資料資訊。
Delta Lake CDC是通過Change Data Feed(CDF)來實現的。CDF允許Delta Lake表能夠追溯行級的變更資訊。開啟CDF後,Delta Lake將在必要的情況下持久化變更的資料資訊,並寫入到特定的表下的目錄檔案中。應用CDC,可以方便的構建增量數倉。
使用限制
僅EMR-3.41.0及後續版本(Delta Lake 0.6.1)和EMR-5.9.0及後續版本(Delta Lake 2.0)的叢集,支援使用Delta Lake CDC功能。
相關參數
SparkConf參數
參數 | 說明 |
spark.sql.externalTableValuedFunctions | EMR自訂Spark Config,用於拓展Spark 2.4.x的Table Valued Function。使用Spark SQL執行CDF查詢時需要配置為table_changes。 |
spark.databricks.delta.changeDataFeed.timestampOutOfRange.enabled | 取值如下:
說明 該參數僅在Delta 2.x版本生效。 |
CDC寫參數
參數 | 說明 |
delta.enableChangeDataFeed | 是否開啟CDF,取值如下:
|
CDC讀參數
僅DataFram和Spark Streaming模式需要設定以下參數。
參數 | 說明 |
readChangeFeed | 如果設定為true,則返回表的Change Data,且必須同時指定startingVersion或startingTimestamp任意一個參數搭配使用。 |
startingVersion | readChangeFeed為true時設定有效,表示從指定版本開始讀取表的Change Data。 |
endingVersion | readChangeFeed為true時設定有效,表示讀取表的Change Data的最後版本。 |
startingTimestamp | readChangeFeed為true時設定有效,表示從指定的時間戳記開始讀取表的Change Data。 |
endingTimestamp | readChangeFeed為true時設定有效,表示讀取表的Change Data的最後時間戳記。 |
Schema
Delta Lake CDF查詢返回的Schema是在原表的Schema基礎上追加以下三個額外欄位:
_change_type:引起變更的操作,取值如下:
insert:標識資料為新插入的。
delete:標識資料為剛刪除的。
update_preimage和update_postimage:標識資料為更新,分別記錄其變更前的記錄和變更後的記錄。
_commit_version:變更對應的Delta表版本。
_commit_timestamp:變更對應的Delta表版本提交的時間。
使用樣本
Spark SQL樣本
僅在EMR Spark2,Delta 0.6.1版本支援使用Spark SQL文法。
EMR Spark2上使用Spark SQL文法需要額外配置以下參數,代碼如下所示。
spark-sql --conf spark.sql.externalTableValuedFunctions=table_changesSQL文法如下所示。
-- Create Delta CDF-enabled Table
CREATE TABLE cdf_tbl (id int, name string, age int) USING delta
TBLPROPERTIES ("delta.enableChangeDataFeed" = "true");
-- Insert Into
INSERT INTO cdf_tbl VALUES (1, 'XUN', 32), (2, 'JING', 30);
-- Insert Overwrite
INSERT OVERWRITE TABLE cdf_tbl VALUES (1, 'a1', 30), (2, 'a2', 32), (3, "a3", 32);
-- Update
UPDATE cdf_tbl set age = age + 1;
-- Merge Into
CREATE TABLE merge_source (id int, name string, age int) USING delta;
INSERT INTO merge_source VALUES (1, "a1", 31), (2, "a2_new", 33), (4, "a4", 30);
MERGE INTO cdf_tbl target USING merge_source source
ON target.id = source.id
WHEN MATCHED AND target.id % 2 == 0 THEN UPDATE SET name = source.name
WHEN MATCHED THEN DELETE
WHEN NOT MATCHED THEN INSERT *;
-- Delete
DELETE FROM cdf_tbl WHERE age >= 32;
-- CDF Query
-- 查詢從版本0開始的所有的Change Data。
select * from table_changes("cdf_tbl", 0);
select * from table_changes("cdf_tbl", '2023-02-03 15:33:34'); --2023-02-03 15:33:34為commit0的提交時間戳記。
-- 查詢版本4對應的Change Data。
select * from table_changes("cdf_tbl", 4, 4);
select * from table_changes("cdf_tbl", '2023-02-03 15:34:06', '2023-02-03 15:34:06'); --2023-02-03 15:34:06為commit4的提交時間戳記。兩次查詢返回資訊如下所示。
圖 1. 查詢1結果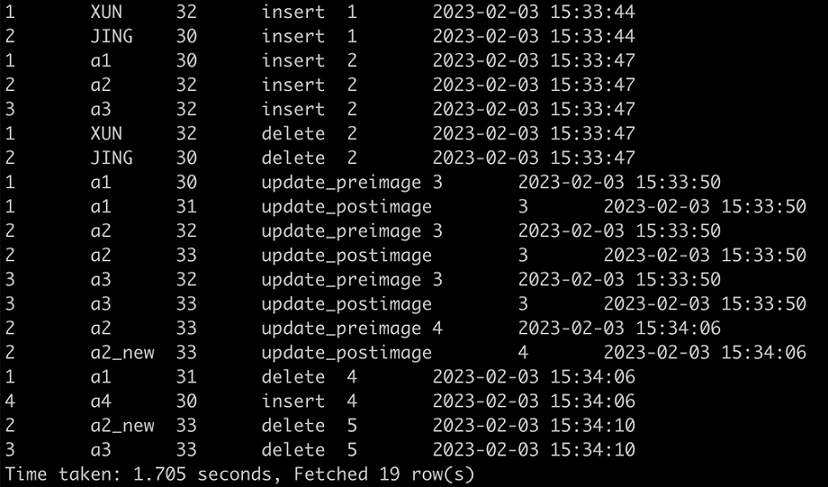
圖 2. 查詢2結果
DataFrame樣本
// Create and Write to Delta CDF-enabled Table
val df = Seq((1, "XUN", 32), (2, "JING", 30)).toDF("id", "name", "age")
df.write.format("delta").mode("append")
.option("delta.enableChangeDataFeed", "true") //首次寫入delta資料時開啟CDF,後續寫入無需設定。
.saveAsTable("cdf_table")
// CDF Query Using DataFrame
spark.read.format("delta")
.option("readChangeFeed", "true")
.option("startingVersion", 0)
.option("endingVersion", 4) //endingVersion可選。
.table("cdf_table")Spark Streaming樣本
// Streaming CDF Query Using Dats
spark.read.format("delta")
.option("readChangeFeed", "true")
.option("startingVersion", 0)
.option("endingVersion", 4) //endingVersion可選。
.table("cdf_table")