阿里雲GPU雲端服務器具有廣闊的覆蓋範圍、超強的計算能力、出色的網路效能和靈活的購買方式,神行工具包(DeepGPU)是專門為GPU雲端服務器搭配的具有GPU計算服務增強能力的免費工具集。本文主要介紹GPU雲端服務器和神行工具包(DeepGPU)的優勢。
GPU產品優勢
覆蓋範圍廣闊
阿里雲GPU雲端服務器在全球多個地區實現規模部署,覆蓋範圍廣,結合彈性供應、Auto Scaling等交付方式,能夠很好地滿足您業務的突發需求。
計算能力超強
阿里雲GPU雲端服務器配備業界超強算力的GPU計算卡,結合高效能CPU平台,單一實例可提供高達1000 TFLOPS的混合精度計算效能。
網路效能出色
阿里雲GPU雲端服務器執行個體的VPC網路最大支援450萬的PPS及32 Gbit/s的內網頻寬。在此基礎上,Super Computing Cluster產品中,節點間額外提供高達50 Gbit/s的RDMA網路,滿足節點間資料轉送的低延時高頻寬要求。
購買方式靈活
支援靈活的資源付費模式,包括訂用帳戶、隨用隨付、搶佔式執行個體、預留執行個體券、儲存容量單位包。您可以按需要購買,避免資源浪費。
神行工具包(DeepGPU)優勢
神行工具包中的組件主要包括叢集極速部署工具FastGPU以及GPU容器共用技術cGPU,其各自具有以下核心優勢。
叢集極速部署工具FastGPU
使用FastGPU構建人工智慧計算任務時,您無需關心IaaS層的計算、儲存、網路等資源部署操作,簡單適配即可一鍵部署,協助您節省時間成本以及經濟成本。
節省時間
一鍵部署叢集。無需分別進行IaaS層計算、儲存、網路等資源的部署操作,將部署叢集的時間縮短到5分鐘。
通過介面和命令列管理工作和資源,方便快捷。
節省成本
當資料集完成準備工作並觸發訓練或推理任務後,才會觸發GPU執行個體資源的購買。當訓練或推理任務結束後,將自動釋放GPU執行個體資源。實現了資源生命週期與任務同步,協助您節省成本。
支援建立搶佔式執行個體。
易用性好
所有資源均為IaaS層,可訪問、可調試。
滿足可視化和log管理需求,保證任務可回溯。
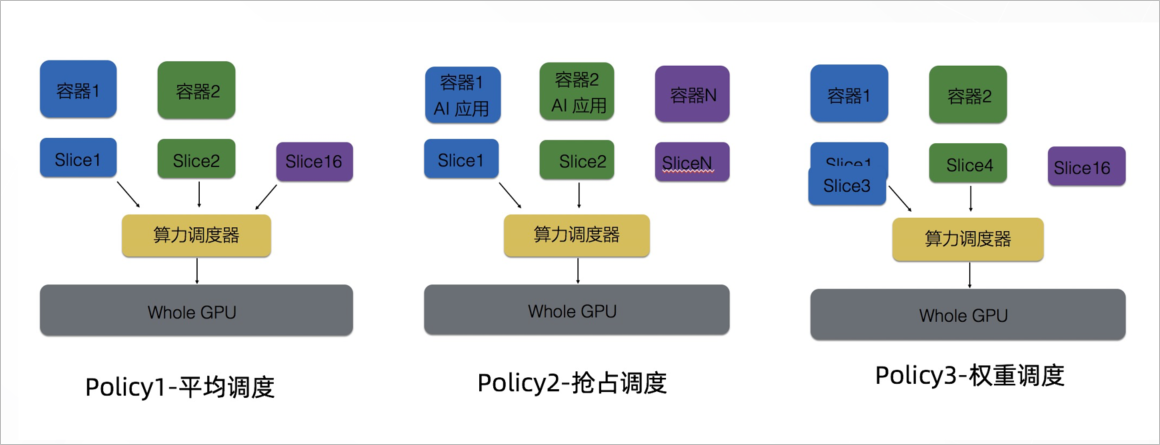
GPU容器共用技術cGPU
GPU容器共用技術cGPU擁有節約成本和靈活分配資源的優勢,從而實現您業務的安全隔離。
節約成本
隨著顯卡技術的不斷髮展和半導體製造工藝的進步,單張GPU卡的算力越來越強,同時價格也越來越高。但在很多的業務情境下,一個AI應用並不需要一整張的GPU卡。cGPU的出現讓多個容器共用一張GPU卡,從而實現業務的安全隔離,提升GPU利用率,節約使用者成本。
可靈活分配資源
cGPU實現了物理GPU的資源任意劃分,您可以按照不同比例靈活配置。
支援按照顯存和算力兩個維度劃分,您可以根據需要靈活分配。

cGPU擁有靈活可配置的算力分配策略,支援三種調度策略的即時切換,滿足了AI負載的峰穀能力的要求。