公用鏡像可能存在一些已知的安全性漏洞或配置問題。通過查看公用鏡像的已知問題,可以協助您瞭解這些問題的潛在安全風險,並採取相應的措施來快速定位和解決問題。
Windows作業系統已知問題
Linux作業系統已知問題
CentOS問題
Debian問題
Fedora CoreOS問題
OpenSUSE問題
Red Hat Enterprise Linux問題
SUSE Linux Enterprise Server問題
其他問題
Windows作業系統已知問題
Windows系統在512 MB記憶體規格上部分功能異常
問題描述
Windows Server Version 2004 資料中心版 64位中文版(不含圖形化案頭)系統在記憶體為512 MB的執行個體規格上使用時,出現建立執行個體時設定的密碼不生效,運行時無法修改密碼以及執行命令失敗等問題。
問題原因
未開啟分頁檔導致虛擬記憶體無法分配,從而在執行程式時機率性出現異常。
解決方案
此類規格由於記憶體太小導致無法掛載PE,又因為執行個體建立時設定的密碼不生效而導致無法正常登入,所以只能藉助雲助手來設定分頁檔。
您可以通過以下方式使用雲助手來執行命令。
通過會話管理器免密登入執行個體執行命令。具體操作,請參見在控制台通過會話管理串連執行個體。
通過雲助手發送命令。具體操作,請參見發送遠程命令。
通過以下命令開啟分頁檔自動管理。
Wmic ComputerSystem set AutomaticManagedPagefile=True說明該命令在執行時可能會失敗,請您多嘗試幾次直至命令執行成功。
您也可以通過
Wmic ComputerSystem get AutomaticManagedPagefile命令查詢分頁檔是否成功開啟。如果顯示如下回顯資訊,表示開啟成功。AutomaticManagedPagefile TRUE
重啟執行個體使配置生效。
Windows Server 2016運行軟體安裝包沒有反應
問題描述
Windows Server 2016在系統內部運行下載的軟體安裝包時,沒有任何反應。
問題原因
出於安全考慮,Windows系統會在啟動過程中的sysprep階段開啟一個ProtectYourPC安全配置,此配置會使系統啟動後攜帶SmartScreen系統進程,主要用於保護您免受惡意網站和不安全下載的侵害。
當您嘗試從Internet下載或運行軟體包時,軟體包會帶有Web網路標誌,這會觸發系統的SmartScreen進程,SmartScreen識別到該軟體來源於互連網,且可能缺乏足夠的信譽資訊因此會被攔截。
解決方案
您可以通過以下任意一種方式來解決:
解除軟體包鎖定
在軟體包的屬性中選中解除鎖定。
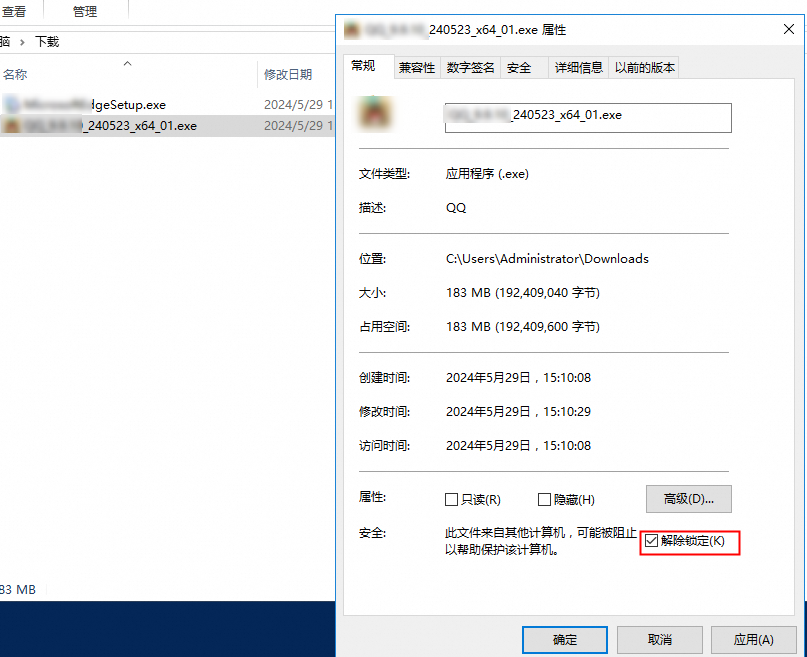
再次運行軟體包。
關閉SmartScreen篩選器
進入
C:\Windows\System32目錄。雙擊開啟
SmartScreenSettings.exe檔案。在Windows SmartScreen對話方塊中選擇不執行任何操作(關閉Windows SmartScreen篩選器),然後單擊確定。
再次運行軟體包。
修改組策略配置
開啟運行視窗,輸入
gpedit.msc。在本機群組原則編輯器中,依次選擇電腦配置 > Windows設定 > 安全設定 > 本地策略 > 安全選項。
找到使用者帳戶控制:用於內建系統管理員帳戶的管理員核准模式選項,然後按右鍵選擇屬性。
在本地安全設定頁簽選擇已啟用選項,然後單擊確定。
重啟系統使配置生效。
再次運行軟體包。
Windows Server 2022安裝KB5034439補丁失敗問題
問題描述
在Windows Server 2022系統上安裝KB5034439失敗。
問題原因
KB5034439是微軟官方2024年1月發布的恢複環境的更新,如果您配置使用的更新源是微軟官方的Windows Update(鏡像預設使用阿里雲的WSUS補救伺服器,不會更新到這個補丁),在進行更新時會搜尋安裝該補丁,可能導致安裝失敗。這種現象符合預期,不影響正常使用。更多資訊,請參見微軟官方文檔KB5034439: Windows Recovery Environment update for Windows Server 2022: January 9, 2024。
2022年06月補丁導致Windows伺服器網卡NAT、RRAS異常等問題
問題描述:根據微軟官方2022年6月23日的公告,Windows終端在安裝微軟官方2022年6月的安全補丁後,會出現網路介面上啟用了NAT、RRAS伺服器可能會失去串連、串連到伺服器的裝置也可能無法串連到Internet等風險。
影響範圍:
Windows Server 2022
Windows Server 2019
Windows Server 2016
Windows Server 2012 R2
Windows Server 2012
Windows Server 2012 R2和Windows Server 2012版本檢查系統更新時,請務必選擇①處的檢查更新。①處串連的更新源為阿里雲內部的Windows WSUS補救伺服器,②處串連的更新源為微軟官方的Internet Windows Update伺服器。因為在特殊情況下,安全更新可能會帶來潛在問題,為了預防發生此類情況,我們會檢查收到的微軟Windows安全更新,將通過檢查的更新發布到內部WSUS補救伺服器中。
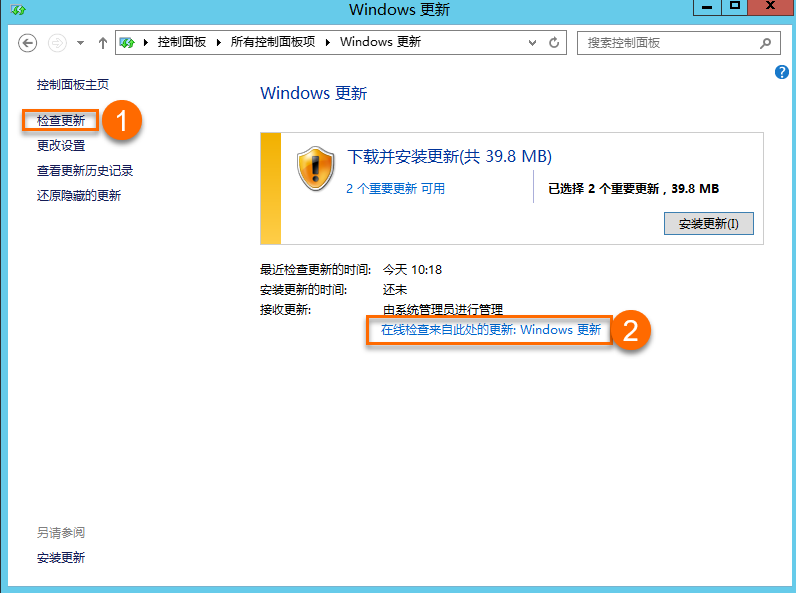
解決方案:阿里雲官方提供的WSUS服務中,已經將相關問題補丁剔除。為了確保您的作業系統不會受到相關影響,請您在Windows終端中檢測是否已經安裝了相關問題補丁。檢測補丁的CMD命令如下,您需要根據不同的Windows Server版本運行匹配的檢測命令。
Windows Server 2012 R2: wmic qfe get hotfixid | find "5014738" Windows Server 2019: wmic qfe get hotfixid | find "5014692" Windows Server 2016: wmic qfe get hotfixid | find "5014702" Windows Server 2012: wmic qfe get hotfixid | find "5014747" Windows Server 2022: wmic qfe get hotfixid | find "5014678"如果檢測結果中顯示您已經安裝了問題補丁,並且您的Windows伺服器出現網卡NAT、RRAS異常等問題。建議您卸載相關問題補丁,以恢複終端至正常狀態。卸載補丁的CMD命令如下,您需要根據不同的Windows Server版本運行匹配的卸載命令。
Windows Server 2012 R2: wusa /uninstall /kb:5014738 Windows Server 2019: wusa /uninstall /kb:5014692 Windows Server 2016: wusa /uninstall /kb:5014702 Windows Server 2012: wusa /uninstall /kb:5014747 Windows Server 2022: wusa /uninstall /kb:5014678說明關於該問題的進一步更新以及操作指導,請以微軟官方說明為準。更多資訊,請參見RRAS Servers can lose connectivity if NAT is enabled on the public interface。
2022年01月補丁導致Windows域控伺服器異常問題
問題描述:根據微軟官方2022年1月13日的公告,Windows終端在安裝微軟官方2022年1月的安全補丁後,會出現域控伺服器無法重啟(或無限重啟)問題、Hyper-V中的虛擬機器(VM)可能無法啟動、IPSec VPN串連可能失敗等風險。
影響範圍:
Windows Server 2022
Windows Server, version 20H2
Windows Server 2019
Windows Server 2016
Windows Server 2012 R2
Windows Server 2012
Windows Server 2012 R2和Windows Server 2012版本檢查系統更新時,請務必選擇①處的檢查更新。①處串連的更新源為阿里雲內部的Windows WSUS補救伺服器,②處串連的更新源為微軟官方的Internet Windows Update伺服器。因為在特殊情況下,安全更新可能會帶來潛在問題,為了預防發生此類情況,我們會檢查收到的微軟Windows安全更新,將通過檢查的更新發布到內部WSUS補救伺服器中。
解決方案:阿里雲官方提供的WSUS服務中,已經將相關問題補丁剔除。為了確保您的作業系統不會受到相關影響,請您在Windows終端中檢測是否已經安裝了相關問題補丁。檢測補丁的CMD命令如下,您需要根據不同的Windows Server版本運行匹配的檢測命令。
Windows Server 2012 R2: wmic qfe get hotfixid | find "5009624" Windows Server 2019: wmic qfe get hotfixid | find "5009557" Windows Server 2016: wmic qfe get hotfixid | find "5009546" Windows Server 2012: wmic qfe get hotfixid | find "5009586" Windows Server 2022: wmic qfe get hotfixid | find "5009555"如果檢測結果中顯示您已經安裝了問題補丁,並且您的Windows終端出現域控伺服器無法使用或者虛擬機器無法啟動的問題。建議您卸載相關問題補丁,以恢複終端至正常狀態。卸載補丁的CMD命令如下,您需要根據不同的Windows Server版本運行匹配的卸載命令。
Windows Server 2012 R2: wusa /uninstall /kb:5009624 Windows Server 2019: wusa /uninstall /kb:5009557 Windows Server 2016: wusa /uninstall /kb:5009546 Windows Server 2012: wusa /uninstall /kb:5009586 Windows Server 2022: wusa /uninstall /kb:5009555說明關於該問題的進一步更新以及操作指導,請以微軟官方說明為準。更多資訊,請參見RRAS Servers can lose connectivity if NAT is enabled on the public interface。
Windows Server 2012 R2安裝.NET Framework 3.5失敗的問題
問題描述:Windows Server 2012 R2系統使用以下版本的鏡像預設已安裝2023年06月補丁KB5027141、7月補丁KB5028872、8月份補丁KB5028970或者9月份補丁KB5029915,再安裝.NET Framework 3.5會出現失敗的情況。
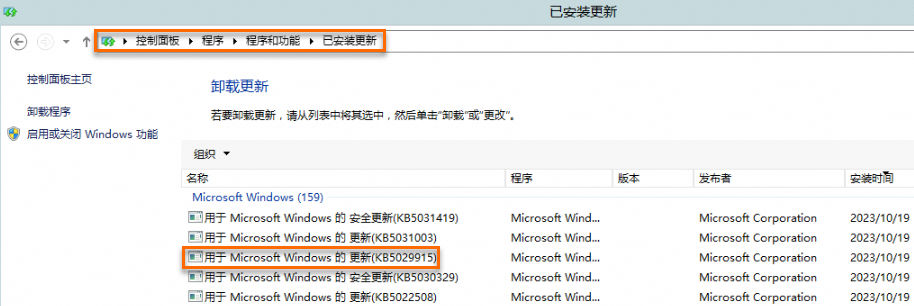
解決方案:
在控制台找到KB5027141、KB5028872、KB5028970或者KB5029915補丁,單擊右鍵選擇卸載,手動卸載補丁。例如在如下圖所示的路徑下,卸載KB5029915補丁。
重啟ECS執行個體。
具體操作,請參見重啟執行個體。
通過以下任意一種方式,安裝.NET Framework 3.5。
伺服器管理員UI介面安裝
在服務管理員中單擊添加角色和功能。
按照嚮導預設配置進行操作,在功能欄中選中.NET Framework 3.5功能。
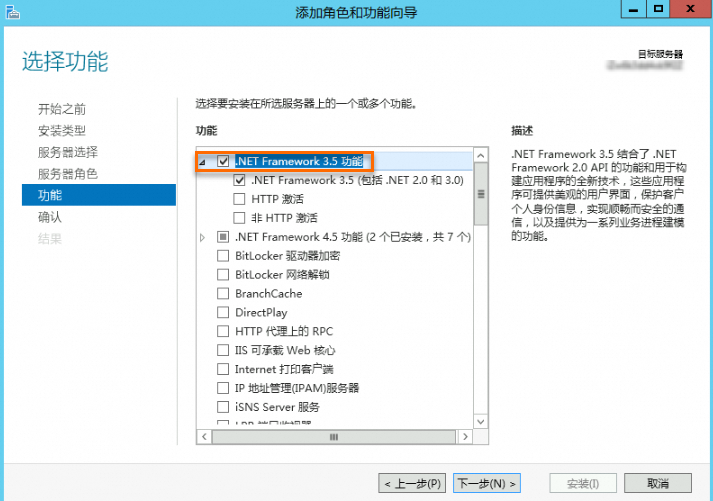
繼續按照嚮導確認結果,直至安裝完成。
執行PowerShell命令安裝
您可以運行以下任意一條命令:
Dism /Online /Enable-Feature /FeatureName:NetFX3 /All
Install-WindowsFeature -Name NET-Framework-Features
Windows Server 2025安裝.NET Framework 3.5失敗的問題
問題描述:在Windows Server 2025系統上安裝.NET Framework 3.5失敗。

解決方案:目前Windows Server 2025系統採用的是阿里雲WSUS更新源,該更新源暫不支援Windows Server 2025系統的功能更新。具體解決方案,請參見如何解決Windows Server 2012 R2及以上執行個體無法安裝.NET Framework 3.5或語言套件的問題?。
Windows系統SSD磁碟顯示為HDD
現象說明:
在控制台購買一台Windows執行個體,掛載SSD雲端硬碟,系統內工作管理員識別SSD盤為HDD。
問題原因:

Windows 判斷磁碟類型主要依據 INQUIRY 命令擷取的 MEDIUM ROTATION RATE,驅動需正確上報 MEDIUM ROTATION RATE,才能讓系統識別為 SSD 或 HDD,若 MEDIUM ROTATION RATE 未上報,系統會顯示為 Unspecified,會顯示為初始化值HDD。之前Windows Server 2025 工作管理員顯示 SSD 是微軟補丁的一個 bug,微軟已在 2025 年 6 月補丁修複。
解決方案:
此問題是底層協議限制導致。對於virtio blk就是無法擷取到底是SSD還是HDD的,OS對於這種情況是顯示為HDD。實際執行個體內部使用的是SSD雲端硬碟,雲端硬碟效能及使用不受影響
Linux作業系統已知問題
CentOS問題
CentOS 8.0公用鏡像命名問題
問題描述:使用centos_8_0_x64_20G_alibase_20200218.vhd公用鏡像建立了CentOS系統執行個體,遠端連線執行個體後檢查系統版本,您發現實際為CentOS 8.1。
testuser@ecshost:~$ lsb_release -a LSB Version: :core-4.1-amd64:core-4.1-noarch Distributor ID: CentOS Description: CentOS Linux release 8.1.1911 (Core) Release: 8.1.1911 Codename: Core問題原因:該鏡像出現在公用鏡像列表中,已更新最新社區更新包,同時也升級了版本到8.1,所以實際版本是8.1。
涉及鏡像ID:centos_8_0_x64_20G_alibase_20200218.vhd。
修複方案:如果您需要使用CentOS 8.0的系統版本,可以通過RunInstances等介面,設定
ImageId=centos_8_0_x64_20G_alibase_20191225.vhd建立ECS執行個體。
CentOS 7部分鏡像ID變更可能引發的問題說明
問題描述:部分CentOS 7公用鏡像更新了鏡像ID,可能會影響到您自動化營運過程中擷取鏡像ID的策略。
涉及鏡像:CentOS 7.5、CentOS 7.6
原因分析:CentOS 7.5和CentOS 7.6公用鏡像在最新版本中使用的鏡像ID格式為
%OS類型%_%大版本號碼%_%小版本號碼%_%特殊欄位%_alibase_%日期%.%格式%。例如,CentOS 7.5的鏡像ID首碼由原centos_7_05_64更新為centos_7_5_x64。您需要根據鏡像ID的變更自行調整可能受影響的自動化營運策略。關於鏡像ID的更多資訊,請參見2023年。
CentOS 7重啟系統後主機名稱大寫字母被修改
問題描述:第一次重啟ECS執行個體後,部分CentOS 7執行個體的主機名稱(hostname)存在大寫字母變成小寫字母的現象,如下表所示。
執行個體hostname樣本
第一次重啟後樣本
後續是否保持小寫不變
iZm5e1qe*****sxx1ps5zX
izm5e1qe*****sxx1ps5zx
是
ZZHost
zzhost
是
NetworkNode
networknode
是
涉及鏡像:以下CentOS公用鏡像,和基於以下公用鏡像建立的自訂鏡像。
centos_7_2_64_40G_base_20170222.vhd
centos_7_3_64_40G_base_20170322.vhd
centos_7_03_64_40G_alibase_20170503.vhd
centos_7_03_64_40G_alibase_20170523.vhd
centos_7_03_64_40G_alibase_20170625.vhd
centos_7_03_64_40G_alibase_20170710.vhd
centos_7_02_64_20G_alibase_20170818.vhd
centos_7_03_64_20G_alibase_20170818.vhd
centos_7_04_64_20G_alibase_201701015.vhd
涉及Hostname類型:如果您的應用有hostname大小寫敏感現象,重啟執行個體後會影響業務。您可根據下面的修複方案修複以下類型的hostname。
hostname類型
是否受影響
何時受影響
是否繼續閱讀文檔
在控制台或通過API建立執行個體時,hostname中有大寫字母
是
第一次重啟執行個體
是
在控制台或通過API建立執行個體時,hostname中全是小寫字母
否
不適用
否
hostname中有大寫字母,您登入執行個體後自行修改了hostname
否
不適用
是
修複方案:如果重啟執行個體後需要保留帶大寫字母的hostname時,可按如下步驟操作。
遠端連線執行個體。
具體操作,請參見選擇ECS遠端連線方式。
查看現有的hostname。
[testuser@izbp193*****3i161uynzzx ~]# hostname izbp193*****3i161uynzzx運行以下命令固化hostname。
hostnamectl set-hostname --static iZbp193*****3i161uynzzX運行以下命令查看更新後的hostname。
[testuser@izbp193*****3i161uynzzx ~]# hostname iZbp193*****3i161uynzzX
下一步:如果您使用的是自訂鏡像,請更新cloud-init軟體至最新版本後,再次建立自訂鏡像。避免使用存在該問題的自訂鏡像建立新執行個體後發生同樣的問題。更多資訊,請參見安裝cloud-init和使用執行個體建立自訂鏡像。
CentOS 6.8裝有NFS Client的執行個體異常崩潰的問題
問題描述:載入了NFS用戶端(NFS Client)的CentOS 6.8執行個體出現超長等待狀態,只能通過重啟執行個體解決該問題。
問題原因:在2.6.32-696~2.6.32-696.10的核心版本上使用NFS服務時,如果通訊延遲出現毛刺(glitch,電子脈衝),核心nfsclient會主動斷開TCP串連。若NFS服務端(Server)響應慢,nfsclient發起的串連可能會卡頓在FIN_WAIT2狀態。正常情況下,FIN_WAIT2狀態的串連預設在一分鐘後逾時並被回收,nfsclient可以發起重連。但是,由於此類核心版本的TCP實現有缺陷,FIN_WAIT2狀態的串連永遠不會逾時,因此nfsclient的TCP串連永遠無法關閉,無法發起新的串連,造成使用者請求卡死(hang死),永遠無法恢複,只能通過重啟ECS執行個體進行修複。
涉及鏡像ID:centos_6_08_32_40G_alibase_20170710.vhd和centos_6_08_64_20G_alibase_20170824.vhd。
修複方案:您可以運行yum update命令升級系統核心至2.6.32-696.11及以上版本。
重要操作執行個體時,請確保您已經提前建立了快照備份資料。具體操作,請參見建立快照。
Debian問題
Debian 9.6傳統網路配置問題
問題描述:無法Ping通使用Debian 9公用鏡像建立的傳統網路類型執行個體。
問題原因:因為Debian系統預設禁用了systemd-networkd服務,傳統網路類型執行個體無法通過DHCP(Dynamic Host Configuration Protocol)模式自動分配IP。
涉及鏡像ID:debian_9_06_64_20G_alibase_20181212.vhd。
修複方案:您需要依次運行下列命令解決該問題。
systemctl enable systemd-networkdsystemctl start systemd-networkd
Fedora CoreOS問題
通過Fedora CoreOS自訂鏡像建立的ECS執行個體中主機名稱不生效問題
問題描述:當您選擇Fedora CoreOS鏡像建立了一台ECS執行個體A,通過執行個體A建立了一個自訂鏡像,然後通過該自訂鏡像建立了一台ECS執行個體B時,您為執行個體B設定的主機名稱不生效(登入執行個體B查看時,執行個體B的主機名稱與執行個體A的主機名稱相同)。
例如,您有一台Fedora CoreOS作業系統的ECS執行個體(
執行個體A),主機名稱為test001,然後您使用該執行個體對應的自訂鏡像建立了一台ECS執行個體(執行個體B),並且在建立執行個體的過程中,將執行個體B的主機名稱設定為了test002。當您成功建立並遠端連線執行個體B後,執行個體B的主機名稱仍然為test001。問題原因:阿里雲公用鏡像提供的Fedora CoreOS鏡像採用作業系統官方的Ignition服務進行執行個體初始化配置。Ignition服務是指Fedora CoreOS與Red Hat Enterprise Linux CoreOS在系統啟動時進入initramfs期間用來操作磁碟的程式。ECS執行個體在初次開機時,Ignition中的
coreos-ignition-firstboot-complete.service會根據/boot/ignition.firstboot檔案(該檔案為空白檔案)是否存在,判斷是否進行執行個體的初始化配置。如果檔案存在,則進行初始化配置(其中包括配置主機名稱),並刪除/boot/ignition.firstboot檔案。由於建立Fedora CoreOS執行個體後至少啟動了一次,則對應自訂鏡像中的/boot/ignition.firstboot檔案已被刪除。當您使用該自訂鏡像建立ECS執行個體時,執行個體初次開機並不會進行初始化配置,對應的主機名稱也不會發生變化。
修複方案:
說明為確保執行個體中資料安全,建議您在操作前先為執行個體建立快照。如果執行個體發生資料異常,可通過快照將雲端硬碟復原至正常狀態。具體操作,請參見建立快照。
當您基於Fedora CoreOS執行個體建立自訂鏡像前,先使用
root許可權(管理員權限)在/boot目錄下建立/ignition.firstboot檔案。命令列操作說明如下:以讀寫方式重新掛載/boot。
sudo mount /boot -o rw,remount建立/ignition.firstboot檔案。
sudo touch /boot/ignition.firstboot以唯讀方式重新掛載/boot。
sudo mount /boot -o ro,remount
關於Ignition相關的配置說明,請參見Ignition配置說明參考。
OpenSUSE問題
OpenSUSE 15核心升級可能導致啟動hang的問題
問題描述:OpenSUSE核心版本升級到
4.12.14-lp151.28.52-default後,執行個體可能在某些CPU規格上啟動hang,現已知的CPU規格為Intel® Xeon® CPU E5-2682 v4 @ 2.50GHz。對應的calltrace調試結果如下:[ 0.901281] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 0.901281] CR2: ffffc90000d68000 CR3: 000000000200a001 CR4: 00000000003606e0 [ 0.901281] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 0.901281] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [ 0.901281] Call Trace: [ 0.901281] cpuidle_enter_state+0x6f/0x2e0 [ 0.901281] do_idle+0x183/0x1e0 [ 0.901281] cpu_startup_entry+0x5d/0x60 [ 0.901281] start_secondary+0x1b0/0x200 [ 0.901281] secondary_startup_64+0xa5/0xb0 [ 0.901281] Code: 6c 01 00 0f ae 38 0f ae f0 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 90 31 d2 65 48 8b 34 25 40 6c 01 00 48 89 d1 48 89 f0 <0f> 01 c8 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 ** **問題原因:新核心版本與CPU Microcode不相容,更多資訊,請參見啟動hang問題。
涉及鏡像:opensuse_15_1_x64_20G_alibase_20200520.vhd。
修複方案:在/boot/grub2/grub.cfg檔案中,以
linux開頭一行中增加核心參數idle=nomwait。檔案修改的樣本內容如下:menuentry 'openSUSE Leap 15.1' --class opensuse --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-20f5f35a-fbab-4c9c-8532-bb6c66ce****' { load_video set gfxpayload=keep insmod gzio insmod part_msdos insmod ext2 set root='hd0,msdos1' if [ x$feature_platform_search_hint = xy ]; then search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' 20f5f35a-fbab-4c9c-8532-bb6c66ce**** else search --no-floppy --fs-uuid --set=root 20f5f35a-fbab-4c9c-8532-bb6c66ce**** fi echo 'Loading Linux 4.12.14-lp151.28.52-default ...' linux /boot/vmlinuz-4.12.14-lp151.28.52-default root=UUID=20f5f35a-fbab-4c9c-8532-bb6c66ce**** net.ifnames=0 console=tty0 console=ttyS0,115200n8 splash=silent mitigations=auto quiet idle=nomwait echo 'Loading initial ramdisk ...' initrd /boot/initrd-4.12.14-lp151.28.52-default }
Red Hat Enterprise Linux問題
Red Hat Enterprise Linux 8 64位通過yum update命令更新核心版本不生效問題
問題描述:在Red Hat Enterprise Linux 8 64位作業系統的ECS執行個體中,運行yum update更新核心版本並重啟執行個體後,發現核心版本仍為舊的核心版本。
問題原因:RHEL 8 64位作業系統中儲存GRUB2環境變數的檔案/boot/grub2/grubenv大小異常,該檔案大小不是標準的1024位元組,從而導致更新核心版本失敗。
修複方案:您需要在更新核心版本後,將新的核心版本設定為預設啟動版本。完整的操作說明如下所述:
運行以下命令,更新核心版本。
yum update kernel -y運行以下命令,擷取當前作業系統的核心啟動參數。
grub2-editenv list | grep kernelopts運行以下命令,備份舊的/grubenv檔案。
mv /boot/grub2/grubenv /home/grubenv.bak運行以下命令,產生一個新的/grubenv檔案。
grub2-editenv /boot/grub2/grubenv create運行以下命令,把新的核心版本設定為預設啟動版本。
本樣本中,更新後的新核心版本以
/boot/vmlinuz-4.18.0-305.19.1.el8_4.x86_64為例。grubby --set-default /boot/vmlinuz-4.18.0-305.19.1.el8_4.x86_64運行以下命令,設定核心啟動參數。
其中,參數
- set kernelopts需要手動設定,取值為步驟2中擷取到的當前作業系統核心啟動參數資訊。grub2-editenv - set kernelopts="root=UUID=0dd6268d-9bde-40e1-b010-0d3574b4**** ro crashkernel=auto net.ifnames=0 vga=792 console=tty0 console=ttyS0,115200n8 noibrs nosmt"運行以下命令,重啟ECS執行個體至新的核心版本。
reboot警告重啟執行個體會造成您的執行個體停止工作,可能導致業務中斷,建議您在非業務高峰期時執行該操作。
SUSE Linux Enterprise Server問題
SUSE Linux Enterprise Server SMT Server串連失敗問題
問題描述:您購買並使用阿里雲付費鏡像SUSE Linux Enterprise Server或SUSE Linux Enterprise Server for SAP時,會遇到SMT Server連線逾時或異常的情況。當您嘗試下載或更新群組件時,返回類似於如下所示的報錯資訊:
Registration server returned 'This server could not verify that you are authorized to access this service.' (500)
Problem retrieving the respository index file for service 'SMT-http_mirrors_cloud_aliyuncs_com' location ****
涉及鏡像:SUSE Linux Enterprise Server、SUSE Linux Enterprise Server for SAP
解決方案:您需要重新註冊並啟用SMT服務。
依次運行以下命令,重新註冊並啟用SMT服務。
SUSEConnect -d SUSEConnect --cleanup systemctl restart guestregister運行以下命令,驗證SMT服務的啟用狀態。
SUSEConnect -s命令列返回樣本如下,表示成功啟用SMT服務。
[{"identifier":"SLES_SAP","version":"12.5","arch":"x86_64","status":"Registered"}]
SUSE Linux Enterprise Server 12 SP5 核心升級可能導致啟動hang的問題
問題描述:SLES(SUSE Linux Enterprise Server)12 SP5之前的核心版本在升級至SLES 12 SP5,或SLES 12 SP5內部核心版本升級後,執行個體可能在某些CPU規格上啟動hang。現已知的CPU規格為
Intel® Xeon® CPU E5-2682 v4 @ 2.50GHz與Intel® Xeon® CPU E7-8880 v4 @ 2.20GHz。對應的calltrace調試結果如下:[ 0.901281] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 0.901281] CR2: ffffc90000d68000 CR3: 000000000200a001 CR4: 00000000003606e0 [ 0.901281] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 0.901281] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [ 0.901281] Call Trace: [ 0.901281] cpuidle_enter_state+0x6f/0x2e0 [ 0.901281] do_idle+0x183/0x1e0 [ 0.901281] cpu_startup_entry+0x5d/0x60 [ 0.901281] start_secondary+0x1b0/0x200 [ 0.901281] secondary_startup_64+0xa5/0xb0 [ 0.901281] Code: 6c 01 00 0f ae 38 0f ae f0 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 90 31 d2 65 48 8b 34 25 40 6c 01 00 48 89 d1 48 89 f0 <0f> 01 c8 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 ** **問題原因:新核心版本與CPU Microcode不相容。
修複方案:在
/boot/grub2/grub.cfg檔案中,以linux開頭一行中增加核心參數idle=nomwait。檔案修改的樣本內容如下:menuentry 'SLES 12-SP5' --class sles --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-fd7bda55-42d3-4fe9-a2b0-45efdced****' { load_video set gfxpayload=keep insmod gzio insmod part_msdos insmod ext2 set root='hd0,msdos1' if [ x$feature_platform_search_hint = xy ]; then search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' fd7bda55-42d3-4fe9-a2b0-45efdced**** else search --no-floppy --fs-uuid --set=root fd7bda55-42d3-4fe9-a2b0-45efdced**** fi echo 'Loading Linux 4.12.14-122.26-default ...' linux /boot/vmlinuz-4.12.14-122.26-default root=UUID=fd7bda55-42d3-4fe9-a2b0-45efdced**** net.ifnames=0 console=tty0 console=ttyS0,115200n8 mitigations=auto splash=silent quiet showopts idle=nomwait echo 'Loading initial ramdisk ...' initrd /boot/initrd-4.12.14-122.26-default }
其他問題
部分高版本核心系統在部分執行個體規格上啟動時可能出現Call Trace
問題描述:部分高版本核心系統(例如
4.18.0-240.1.1.el8_3.x86_64核心版本的RHEL 8.3、CentOS 8.3系統等),在部分執行個體規格(例如ecs.i2.4xlarge)上啟動時可能出現如下所示的Call Trace:Dec 28 17:43:45 localhost SELinux: Initializing. Dec 28 17:43:45 localhost kernel: Dentry cache hash table entries: 8388608 (order: 14, 67108864 bytes) Dec 28 17:43:45 localhost kernel: Inode-cache hash table entries: 4194304 (order: 13, 33554432 bytes) Dec 28 17:43:45 localhost kernel: Mount-cache hash table entries: 131072 (order: 8, 1048576 bytes) Dec 28 17:43:45 localhost kernel: Mountpoint-cache hash table entries: 131072 (order: 8, 1048576 bytes) Dec 28 17:43:45 localhost kernel: unchecked MSR access error: WRMSR to 0x3a (tried to write 0x000000000000****) at rIP: 0xffffffff8f26**** (native_write_msr+0x4/0x20) Dec 28 17:43:45 localhost kernel: Call Trace: Dec 28 17:43:45 localhost kernel: init_ia32_feat_ctl+0x73/0x28b Dec 28 17:43:45 localhost kernel: init_intel+0xdf/0x400 Dec 28 17:43:45 localhost kernel: identify_cpu+0x1f1/0x510 Dec 28 17:43:45 localhost kernel: identify_boot_cpu+0xc/0x77 Dec 28 17:43:45 localhost kernel: check_bugs+0x28/0xa9a Dec 28 17:43:45 localhost kernel: ? __slab_alloc+0x29/0x30 Dec 28 17:43:45 localhost kernel: ? kmem_cache_alloc+0x1aa/0x1b0 Dec 28 17:43:45 localhost kernel: start_kernel+0x4fa/0x53e Dec 28 17:43:45 localhost kernel: secondary_startup_64+0xb7/0xc0 Dec 28 17:43:45 localhost kernel: Last level iTLB entries: 4KB 64, 2MB 8, 4MB 8 Dec 28 17:43:45 localhost kernel: Last level dTLB entries: 4KB 64, 2MB 0, 4MB 0, 1GB 4 Dec 28 17:43:45 localhost kernel: FEATURE SPEC_CTRL Present Dec 28 17:43:45 localhost kernel: FEATURE IBPB_SUPPORT Present問題原因:這部分核心版本社區更新合入了嘗試Write MSR的PATCH,但部分執行個體規格(例如ecs.i2.4xlarge)由於虛擬化版本不支援Write MSR,導致出現該Call Trace。
修複方案:該Call Trace不影響系統正常使用及穩定性,您可以忽略該報錯。
高主頻通用型執行個體規格類型系列hfg6與部分Linux核心版本存在相容性問題導致panic
問題描述:目前Linux社區的部分系統,例如CentOS 8、SUSE Linux Enterprise Server 15 SP2、OpenSUSE 15.2等系統。在高主頻通用型執行個體規格類型系列hfg6的執行個體中升級新版本核心可能出現核心錯誤(Kernel panic)。calltrace調試樣本如下:
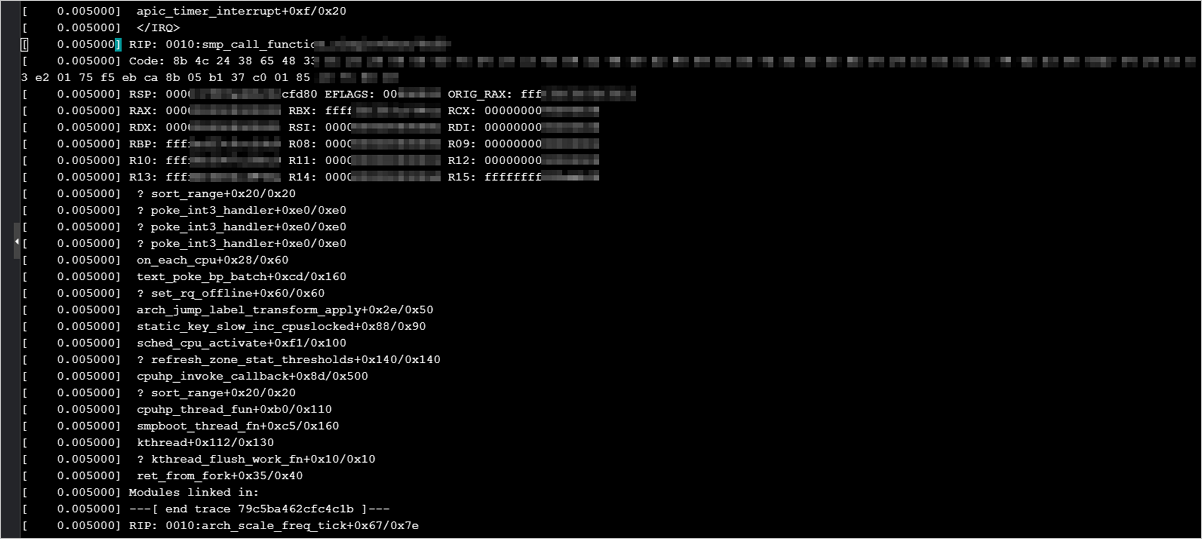
問題原因:高主頻通用型執行個體規格類型系列hfg6與部分Linux核心版本存在相容性問題。
修複方案:
SUSE Linux Enterprise Server 15 SP2和OpenSUSE 15.2系統目前最新版核心已經修複。變更提交(commit)內容如下,如果您升級的最新版核心包含此內容,則已相容執行個體規格類型系列hfg6。
commit 1e33d5975b49472e286bd7002ad0f689af33fab8 Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:51:09 2020 +0200 x86, sched: Bail out of frequency invariance if turbo_freq/base_freq gives 0 (bsc#1176925). suse-commit: a66109f44265ff3f3278fb34646152bc2b3224a5 commit dafb858aa4c0e6b0ce6a7ebec5e206f4b3cfc11c Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:16:50 2020 +0200 x86, sched: Bail out of frequency invariance if turbo frequency is unknown (bsc#1176925). suse-commit: 53cd83ab2b10e7a524cb5a287cd61f38ce06aab7 commit 22d60a7b159c7851c33c45ada126be8139d68b87 Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:10:30 2020 +0200 x86, sched: check for counters overflow in frequency invariant accounting (bsc#1176925).CentOS 8系統如果使用命令yum update升級到最新核心版本
kernel-4.18.0-240及以上,在高主頻通用型執行個體規格類型系列hfg6的執行個體中,可能出現Kernel panic。如果發生該問題,請回退至上一個核心版本。
pip操作時的逾時問題
問題描述:pip請求偶爾出現逾時或失敗現象。
涉及鏡像:CentOS、Debian、Ubuntu、SUSE、OpenSUSE、Alibaba Cloud Linux。
原因分析:阿里雲提供了以下三個pip源地址。其中,預設訪問地址為mirrors.aliyun.com,訪問該地址的執行個體需能訪問公網。當您的執行個體未分配公網IP時,會出現pip請求逾時故障。
(預設)公網:mirrors.aliyun.com
Virtual Private Cloud內網:mirrors.cloud.aliyuncs.com
傳統網路內網:mirrors.aliyuncs.com
修複方案:您可採用以下任一方法解決該問題。
方法一
為您的執行個體分配公網IP,即為執行個體綁定一個Elastic IP Address(EIP)。具體操作,請參見EIP 綁定雲資源。
訂用帳戶執行個體還可通過升降配重新分配公網IP。具體操作,請參見訂用帳戶執行個體升配規格。
方法二
一旦出現pip響應延遲的情況,您可在ECS執行個體中運行指令碼fix_pypi.sh,然後再重試pip操作。具體步驟如下:
遠端連線執行個體。
具體操作,請參見通過VNC串連執行個體。
運行以下命令擷取指令檔。
wget http://image-offline.oss-cn-hangzhou.aliyuncs.com/fix/fix_pypi.sh運行指令碼。
Virtual Private Cloud執行個體:運行命令
bash fix_pypi.sh "mirrors.cloud.aliyuncs.com"。傳統網路執行個體:運行命令
bash fix_pypi.sh "mirrors.aliyuncs.com"。
重試pip操作。
fix_pypi.sh指令碼內容如下:
#!/bin/bash function config_pip() { pypi_source=$1 if [[ ! -f ~/.pydistutils.cfg ]]; then cat > ~/.pydistutils.cfg << EOF [easy_install] index-url=http://$pypi_source/pypi/simple/ EOF else sed -i "s#index-url.*#index-url=http://$pypi_source/pypi/simple/#" ~/.pydistutils.cfg fi if [[ ! -f ~/.pip/pip.conf ]]; then mkdir -p ~/.pip cat > ~/.pip/pip.conf << EOF [global] index-url=http://$pypi_source/pypi/simple/ [install] trusted-host=$pypi_source EOF else sed -i "s#index-url.*#index-url=http://$pypi_source/pypi/simple/#" ~/.pip/pip.conf sed -i "s#trusted-host.*#trusted-host=$pypi_source#" ~/.pip/pip.conf fi } config_pip $1