E-HPC用戶端提供了可視化的頁面來配置HPL、iPerf和FIO應用,可以快速提交相關作業,測試叢集benchmark效能,包括浮點計算能力、頻寬效能和讀寫能力。
背景資訊
測試叢集benchmark效能主要使用以下幾個軟體:
HPL:一個測試高效能運算叢集系統浮點效能的基準程式。HPL通過對高效能運算叢集採用高斯消元法求解一元N次稠密線性代數方程組的測試,評價高效能運算叢集的浮點計算能力。
iPerf:一個網路效能測試工具,支援設定協議、時間等相關參數,可以報告頻寬、資料包丟失等。
FIO:一個開源的I/O壓力測試工具,主要用於測試磁碟的IO效能,支援多引擎和多情境測試。
準備工作
使用用戶端運行HPL、iPerf和FIO測試叢集效能,請確保已在叢集中安裝HPL、iPerf和FIO軟體及其依賴。需安裝的軟體及其相關依賴如下:
HPL:需安裝intel-mpi 2018、linpack 2018、 openmpi 3.0.0。
iPerf:需安裝iPerf、intel-mpi 2018。
FIO:需安裝fio 3.1、intel-mpi 2018。
其中,iPerf需要在每個節點上執行yum install -y iperf命令安裝;其他軟體可以通過控制台安裝,具體操作,請參見安裝軟體。
操作步驟
開啟並登入用戶端。
在左側導覽列,單擊應用中心。
測試算力。
單擊hpl應用。
在彈出面板配置相關參數,單擊提交。
參數類型
參數
樣本值
描述
基礎參數
作業名稱
hpltest
自訂設定。
作業隊列
workq
運行該作業的隊列。
CPU核心數
2
單個節點的CPU核心數。
節點數
1
運行該作業所需的計算節點數。
輸出日誌
hpl_test.log
作業作業記錄的輸出路徑。
應用參數
求解規模
10000
求解的矩陣規模(N)。規模越大,有效計算所佔的比例越大,則系統浮點處理效能越高。但矩陣規模越大會導致記憶體消耗量越多,如果系統實際記憶體空間不足,使用緩衝、效能會大幅度降低。矩陣佔用系統總記憶體的80%左右為最佳,即N×N×8=系統總記憶體×80%(其中總記憶體的單位為位元組)。
分塊大小
192 256
求解矩陣過程中矩陣分塊的大小(NB)。NB值的選擇主要是通過實際測試得出最優值。
測試頻寬。
單擊iperf應用。
在彈出面板配置相關參數,單擊提交。
參數類型
參數
樣本值
描述
基礎參數
作業名稱
iperftest
自訂設定。
作業隊列
workq
運行該作業的隊列。
CPU核心數
2
單個節點的CPU核心數。
節點數
1
運行該作業所需的計算節點數。
輸出日誌
iperf_test.log
作業作業記錄的輸出路徑。
應用參數
HostName
login0
要測試的節點主機名稱。
主機網卡
eth0
要測試的節點主機網卡。
測試讀寫能力。
單擊fio應用。
在彈出面板配置相關參數,單擊提交。
參數類型
參數
樣本值
描述
基礎參數
作業名稱
fiotest
自訂設定。
作業隊列
workq
運行該作業的隊列。
CPU核心數
2
單個節點的CPU核心數。
節點數
1
運行該作業所需的計算節點數。
輸出日誌
fio_test.log
作業作業記錄的輸出路徑。
應用參數
ioengine
psync
I/O引擎使用的測試方式。可選項:
psync
libaio
讀寫方式
rw
測試的讀寫方式。可選項:
read:順序讀
write:順序寫
rw:順序讀寫
randread:隨機讀
randwrite:隨機寫
randrw:隨機讀寫
IO塊大小
4K
單次I/O測試的塊檔案大小,可配置為4K或16K。
線程數
1
測試線程數。
測試時間
100s
測試時間。
讀寫資料量
1024M
要測試的資料量。
測試檔案
/home/username
存放系統產生的測試檔案的路徑。
查看結果
在用戶端的左側導覽列,單擊作業查詢。
找到HPL、iPerf和FIO作業,分別確認作業狀態並擷取結果。
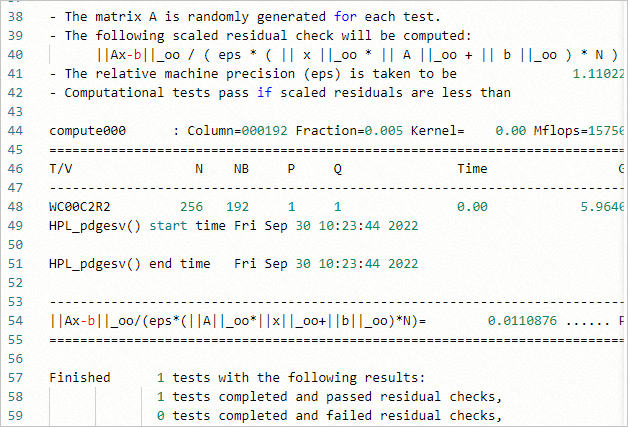
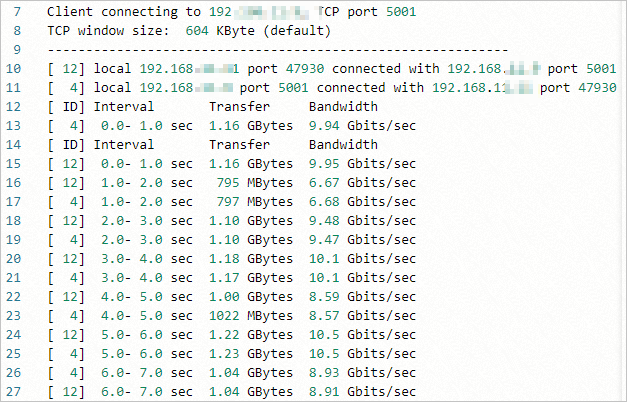
當作業狀態變為FINISHED時,單擊作業對應的詳情,在作業詳情頁面單擊作業輸出檔案與路徑後的查看,即可查看結果。結果樣本如下:
HPL
iPerf
FIO
