新版資料訂閱支援使用0.11版本至2.7版本的Kafka用戶端消費訂閱資料,DTS為您提供了Kafka用戶端Demo,本文將介紹該用戶端的使用說明。
注意事項
使用本文提供的Demo消費資料時,如果採用auto commit(自動認可),可能會因為資料還沒被消費完就執行了提交操作,從而丟失部分資料,建議採用手動提交的方式以避免該問題。
說明如果發生故障沒有提交成功,重啟用戶端後會從上一個記錄的位點進行資料消費,期間會有部分重複資料,您需要手動過濾。
資料以Avro序列化儲存,詳細格式請參見Record.avsc文檔。
警告如果您使用的不是本文提供的Kafka用戶端,在進行還原序列化解析(DTS Avro的還原序列化樣本)時,可能出現解析的資料有誤,您需要自行驗證資料的正確性。
關於
offsetForTimes介面,DTS的搜尋單位為秒,原生Kafka的搜尋單位為毫秒。由於資料訂閱服務端會因容災等原因導致網路閃斷,若您未使用本文提供的Kafka用戶端,您使用的Kafka用戶端需具備網路重試能力。
若您使用原生的Kafka用戶端消費訂閱資料,則可能會在DTS發生增量資料擷取模組切換行為,從而使subscribe模式下訂閱用戶端儲存在服務端的消費位點被清除,您需要手動調整訂閱的消費位點以實現按需消費資料。若您需要使用subscribe模式建議使用DTS提供的訂閱SDK消費訂閱資料,或者自行管理位點,詳情請參見使用SDK消費訂閱資料和管理位點。
Kafka用戶端運行流程說明
請下載Kafka用戶端Demo代碼。更多關於代碼使用的詳細介紹,請參見Demo中的Readme文檔。
單擊
 ,然後選擇Download ZIP下載檔案。
,然後選擇Download ZIP下載檔案。如需使用Kafka用戶端2.0版本,您需要修改subscribe_example-master/javaimpl/pom.xml檔案,將kafka用戶端的版本號碼修改成2.0.0。
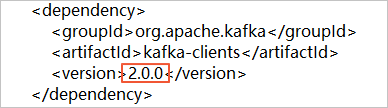
表 1. 運行流程說明
步驟 | 相關目錄或檔案 |
1、使用原生的Kafka consumer從資料訂閱通道中擷取增量資料。 | subscribe_example-master/javaimpl/src/main/java/recordgenerator/ |
2、將擷取的增量資料鏡像執行還原序列化,並從中擷取 前鏡像 、 後鏡像 和其他屬性。 警告
| subscribe_example-master/javaimpl/src/main/java/boot/RecordPrinter.java |
3、將還原序列化後的資料中的dataTypeNumber欄位轉換為對應資料庫的欄位類型。 說明 關於對應關係的詳情,請參見欄位類型與dataTypeNumber數值的對應關係。 | subscribe_example-master/javaimpl/src/main/java/recordprocessor/mysql/ |
操作步驟
本文以IntelliJ IDEA軟體(Community Edition 2018.1.4 Windows版本)為例,介紹如何運行該用戶端消費訂閱通道中的資料。
建立新版資料訂閱通道,詳情請參見訂閱者案概覽中的相關配置文檔。
建立一個或多個消費組,詳情請參見新增消費組。
下載Kafka用戶端Demo代碼,然後解壓該檔案。
說明單擊
,然後選擇Download ZIP下載檔案。開啟IntelliJ IDEA軟體,然後單擊Open。

在彈出的對話方塊中,定位至Kafka用戶端Demo代碼下載的目錄,參照下圖依次展開檔案夾,找到專案物件模型檔案:pom.xml。

在彈出對話方塊中,選擇Open as Project。
在IntelliJ IDEA軟體介面,依次展開檔案夾,找到並雙擊開啟Kafka用戶端Demo檔案:NotifyDemoDB.java。
設定NotifyDemoDB.java檔案中的各參數對應的值。
參數
說明
擷取方式
USER_NAME
消費組的帳號。
警告如您未使用本文提供的用戶端,請按照
<消費組的帳號>-<消費組ID>的格式設定使用者名稱(例如:dtstest-dtsae******bpv),否則無法正常串連。在DTS控制台單擊目標訂閱執行個體ID,然後單擊左側導覽列的數據消費,您可以擷取到消費組ID/名稱和消費組的帳號資訊。
說明消費組帳號的密碼已在您建立消費組時指定。
PASSWORD_NAME
該帳號的密碼。
SID_NAME
消費組ID。
GROUP_NAME
消費組名稱,需保持和消費組ID相同(即本參數也填入消費組ID)。
KAFKA_TOPIC
資料訂閱通道的訂閱Topic。
在DTS控制台單擊目標訂閱執行個體ID,在基本資料頁面,您可以擷取到訂閱Topic和網路資訊。
KAFKA_BROKER_URL_NAME
資料訂閱通道的網路地址資訊。
說明如果您部署Kafka用戶端所屬的ECS執行個體與資料訂閱通道屬於傳統網路或同一專用網路,建議通過內網地址進行資料訂閱,網路延遲最小。
鑒於網路穩定性因素,不建議使用公網地址。
INITIAL_CHECKPOINT_NAME
消費的資料時間點,格式為Unix時間戳記,例如1592269238。
說明您需要自行儲存時間點資訊,以便:
當業務程式中斷後,傳入已消費的資料時間點繼續消費資料,防止資料丟失。
在訂閱用戶端啟動時,傳入所需的消費位點,調整訂閱位點,實現按需消費資料。
若SUBSCRIBE_MODE_NAME為subscribe時,傳入的INITIAL_CHECKPOINT_NAME僅在訂閱用戶端初次開機時生效。
消費的資料時間點必須在訂閱執行個體的資料範圍之內,並需轉化為Unix時間戳記。
說明您可以在訂閱工作清單的數據範圍列,查看訂閱執行個體的資料範圍。
Unix時間戳記轉換工具可用搜尋引擎擷取。
USE_CONFIG_CHECKPOINT_NAME
預設取值為true,即強制使用指定的資料時間點來消費資料,避免丟失已接收到的但未處理的資料。
無
SUBSCRIBE_MODE_NAME
一個消費組下支援同時啟動兩個及以上Kafka用戶端,如需實現該功能,請將所有用戶端該參數的值設定為subscribe。
預設值為assign,即不使用該功能,建議只部署一個用戶端。
無
在IntelliJ IDEA軟體介面的頂部,選擇運行該用戶端。
說明首次運行時,軟體需要一定時間自動載入相關依賴包並完成安裝。
執行結果
運行結果如下圖所示,該用戶端可正常訂閱到源庫的資料變更資訊。

您也可以去除NotifyDemoDB.java檔案中的列印日誌詳情的注釋(即刪除第25行//log.info(ret);中的//),然後再次運行該用戶端即可查看詳細的資料變更資訊。
常見問題
Q:為什麼需要自行記錄用戶端的消費位點?
A:由於DTS記錄的消費位點是接收到Kafka消費用戶端執行commit操作的時間點,可能與當前實際消費到的時間點存在一定的時間差。當業務程式或Kafka消費用戶端異常中斷後,您可以傳入自行記錄的消費位點以繼續消費,避免消費到重複的資料或缺失部分資料。
管理位點
配置訂閱用戶端監聽DTS的資料擷取模組的切換行為。
通過配置訂閱用戶端的Consumer的properties,監聽DTS的資料擷取模組的切換行為,實現方法的主要內容如下所示:
properties.setProperty(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, ClusterSwitchListener.class.getName());ClusterSwitchListener的實現方法如下所示:
public class ClusterSwitchListener implements ClusterResourceListener, ConsumerInterceptor { private final static Logger LOG = LoggerFactory.getLogger(ClusterSwitchListener.class); private ClusterResource originClusterResource = null; private ClusterResource currentClusterResource = null; public ConsumerRecords onConsume(ConsumerRecords records) { return records; } public void close() { } public void onCommit(Map offsets) { } public void onUpdate(ClusterResource clusterResource) { synchronized (this) { originClusterResource = currentClusterResource; currentClusterResource = clusterResource; if (null == originClusterResource) { LOG.info("Cluster updated to " + currentClusterResource.clusterId()); } else { if (originClusterResource.clusterId().equals(currentClusterResource.clusterId())) { LOG.info("Cluster not changed on update:" + clusterResource.clusterId()); } else { LOG.error("Cluster changed"); throw new ClusterSwitchException("Cluster changed from " + originClusterResource.clusterId() + " to " + currentClusterResource.clusterId() + ", consumer require restart"); } } } } public boolean isClusterResourceChanged() { if (null == originClusterResource) { return false; } if (originClusterResource.clusterId().equals(currentClusterResource.clusterId())) { return false; } return true; } public void configure(Map<String, ?> configs) { } public static class ClusterSwitchException extends KafkaException { public ClusterSwitchException(String message, Throwable cause) { super(message, cause); } public ClusterSwitchException(String message) { super(message); } public ClusterSwitchException(Throwable cause) { super(cause); } public ClusterSwitchException() { super(); } }處理捕獲到DTS資料擷取模組的切換行為。
將實際消費的最後一條訂閱資料的時間位點(timestamp),設定為下一次訂閱的初始位點,實現方法的主要內容如下所示:
try{ //do some action } catch (ClusterSwitchListener.ClusterSwitchException e) { reset(); } //重設位點 public reset() { long offset = kafkaConsumer.offsetsForTimes(timestamp); kafkaConsumer.seek(tp,offset); }說明實現方法樣本,請參見KafkaRecordFetcher。
欄位類型與dataTypeNumber數值的對應關係
MySQL欄位類型與dataTypeNumber數值的對應關係
MySQL欄位類型 | 對應dataTypeNumber數值 |
MYSQL_TYPE_DECIMAL | 0 |
MYSQL_TYPE_INT8 | 1 |
MYSQL_TYPE_INT16 | 2 |
MYSQL_TYPE_INT32 | 3 |
MYSQL_TYPE_FLOAT | 4 |
MYSQL_TYPE_DOUBLE | 5 |
MYSQL_TYPE_NULL | 6 |
MYSQL_TYPE_TIMESTAMP | 7 |
MYSQL_TYPE_INT64 | 8 |
MYSQL_TYPE_INT24 | 9 |
MYSQL_TYPE_DATE | 10 |
MYSQL_TYPE_TIME | 11 |
MYSQL_TYPE_DATETIME | 12 |
MYSQL_TYPE_YEAR | 13 |
MYSQL_TYPE_DATE_NEW | 14 |
MYSQL_TYPE_VARCHAR | 15 |
MYSQL_TYPE_BIT | 16 |
MYSQL_TYPE_TIMESTAMP_NEW | 17 |
MYSQL_TYPE_DATETIME_NEW | 18 |
MYSQL_TYPE_TIME_NEW | 19 |
MYSQL_TYPE_JSON | 245 |
MYSQL_TYPE_DECIMAL_NEW | 246 |
MYSQL_TYPE_ENUM | 247 |
MYSQL_TYPE_SET | 248 |
MYSQL_TYPE_TINY_BLOB | 249 |
MYSQL_TYPE_MEDIUM_BLOB | 250 |
MYSQL_TYPE_LONG_BLOB | 251 |
MYSQL_TYPE_BLOB | 252 |
MYSQL_TYPE_VAR_STRING | 253 |
MYSQL_TYPE_STRING | 254 |
MYSQL_TYPE_GEOMETRY | 255 |
Oracle欄位類型與dataTypeNumber數值的對應關係
Oracle欄位類型 | 對應dataTypeNumber數值 |
VARCHAR2/NVARCHAR2 | 1 |
NUMBER/FLOAT | 2 |
LONG | 8 |
DATE | 12 |
RAW | 23 |
LONG_RAW | 24 |
UNDEFINED | 29 |
XMLTYPE | 58 |
ROWID | 69 |
CHAR、NCHAR | 96 |
BINARY_FLOAT | 100 |
BINARY_DOUBLE | 101 |
CLOB/NCLOB | 112 |
BLOB | 113 |
BFILE | 114 |
TIMESTAMP | 180 |
TIMESTAMP_WITH_TIME_ZONE | 181 |
INTERVAL_YEAR_TO_MONTH | 182 |
INTERVAL_DAY_TO_SECOND | 183 |
UROWID | 208 |
TIMESTAMP_WITH_LOCAL_TIME_ZONE | 231 |
PostgreSQL欄位類型與dataTypeNumber數值的對應關係
PostgreSQL欄位類型 | 對應dataTypeNumber數值 |
INT2/SMALLINT | 21 |
INT4/INTEGER/SERIAL | 23 |
INT8/BIGINT | 20 |
CHARACTER | 18 |
CHARACTER VARYING | 1043 |
REAL | 700 |
DOUBLE PRECISION | 701 |
NUMERIC | 1700 |
MONEY | 790 |
DATE | 1082 |
TIME/TIME WITHOUT TIME ZONE | 1083 |
TIME WITH TIME ZONE | 1266 |
TIMESTAMP/TIMESTAMP WITHOUT TIME ZONE | 1114 |
TIMESTAMP WITH TIME ZONE | 1184 |
BYTEA | 17 |
TEXT | 25 |
JSON | 114 |
JSONB | 3082 |
XML | 142 |
UUID | 2950 |
POINT | 600 |
LSEG | 601 |
PATH | 602 |
BOX | 603 |
POLYGON | 604 |
LINE | 628 |
CIDR | 650 |
CIRCLE | 718 |
MACADDR | 829 |
INET | 869 |
INTERVAL | 1186 |
TXID_SNAPSHOT | 2970 |
PG_LSN | 3220 |
TSVECTOR | 3614 |
TSQUERY | 3615 |