DMS分類分級掃描能夠對資料庫中的敏感性資料進行檢測,並自動為符合識別規則的欄位打上相應的分類分級標籤,還可以保護高敏感等級的欄位,並將敏感欄位直觀地展示在識別結果中。本文介紹DMSSensitive Data Discovery and Protection分類分級掃描功能的原理。
原理介紹
DMS分類分級掃描由底層識別模型掃描和上層分類分級掃描組成。先使用識別模型掃描表中欄位和資料,再使用分類分級掃描表中欄位。其中,識別模型掃描可以識別資料資訊類型,例如姓名、時間等。分類分級掃描則基於識別模型掃描的結果,通過執行個體關聯的分類分級模板對欄位進行業務歸類,同時自動化佈建欄位的安全層級和脫敏演算法。
分類分級掃描基於識別模型掃描,但兩者相互獨立,互不干擾。
識別模型掃描
識別模型掃描支援如下兩種識別方式:
資料內容識別(正則匹配)
通過識別模型匹配欄位內容來對欄位進行歸類。例如識別模型名稱為身份證,若欄位資料符合身份證校正演算法,則將該欄位標記為身份證類型。
在進行資料內容識別時,DMS會隨機採樣部分資料進行識別,以保證識別效率;當採樣資料中符合識別模型要求的資料量大於特定閾值時,系統可以確定該欄位為身份證類型。
中繼資料識別
通過識別模型匹配欄位名稱,對欄位進行歸類。例如,當DMS內建的身份證識別模型識別到表中欄位名稱為id_card時,會將該欄位標記為身份證類型。
識別結果
每個欄位可對應多個識別結果。例如識別模型手機號與11位元字均可識別手機號內容。對於單個欄位,DMS最多儲存3個識別結果。
DMS內建部分識別模型,使用者也可以自訂識別模型。自訂識別模型僅支援資料內容識別。
識別模型有禁用和啟用(預設)兩種狀態。僅已啟用的識別模型,會被系統逐一應用到欄位進行識別。
分類分級掃描
分類分級掃描會將待掃描的欄位與分類規則進行一一匹配。若欄位符合分類規則的定義,則標記為該欄位的分類規則。
分級分類原理
首先篩選出分類分級模板中所有已啟用的分類規則,再針對單個識別規則,分以下三步進行識別:
根據欄位識別模型的掃描結果,判斷分類規則中是否包含識別模型。
例如識別模型為識別模型A、識別模型B,分類規則定義的識別模型為識別模型B、識別模型C,則系統會取兩者交集識別模型B,並認為該分類規則包含欄位的識別模型,繼續識別下一個規則。若分類規則中沒有命中的識別模型,則認為識別失敗,繼續識別下一個規則。
根據欄位的中繼資料(庫名、表名、欄位名及欄位備忘)進行識別範圍判斷。
判斷該欄位的資料是否在識別範圍內。若存在,則將該分類暫存至欄位的分類結果中,繼續選取下一個分類規則對欄位進行識別。
標記欄位的分類。
當使用所有分類規則對欄位進行識別後,僅有一個符合要求的規則,則標記為該欄位的分類。若欄位符合多種分類規則,則根據規則的安全層級進行排序(由低到高),最終選定安全層級最高的分類。
如下為單個欄位的分類分級掃描過程:
識別規則基本資料說明
在分類分級掃描前,您可以自訂分類分級識別規則。如下為部分重要參數說明:
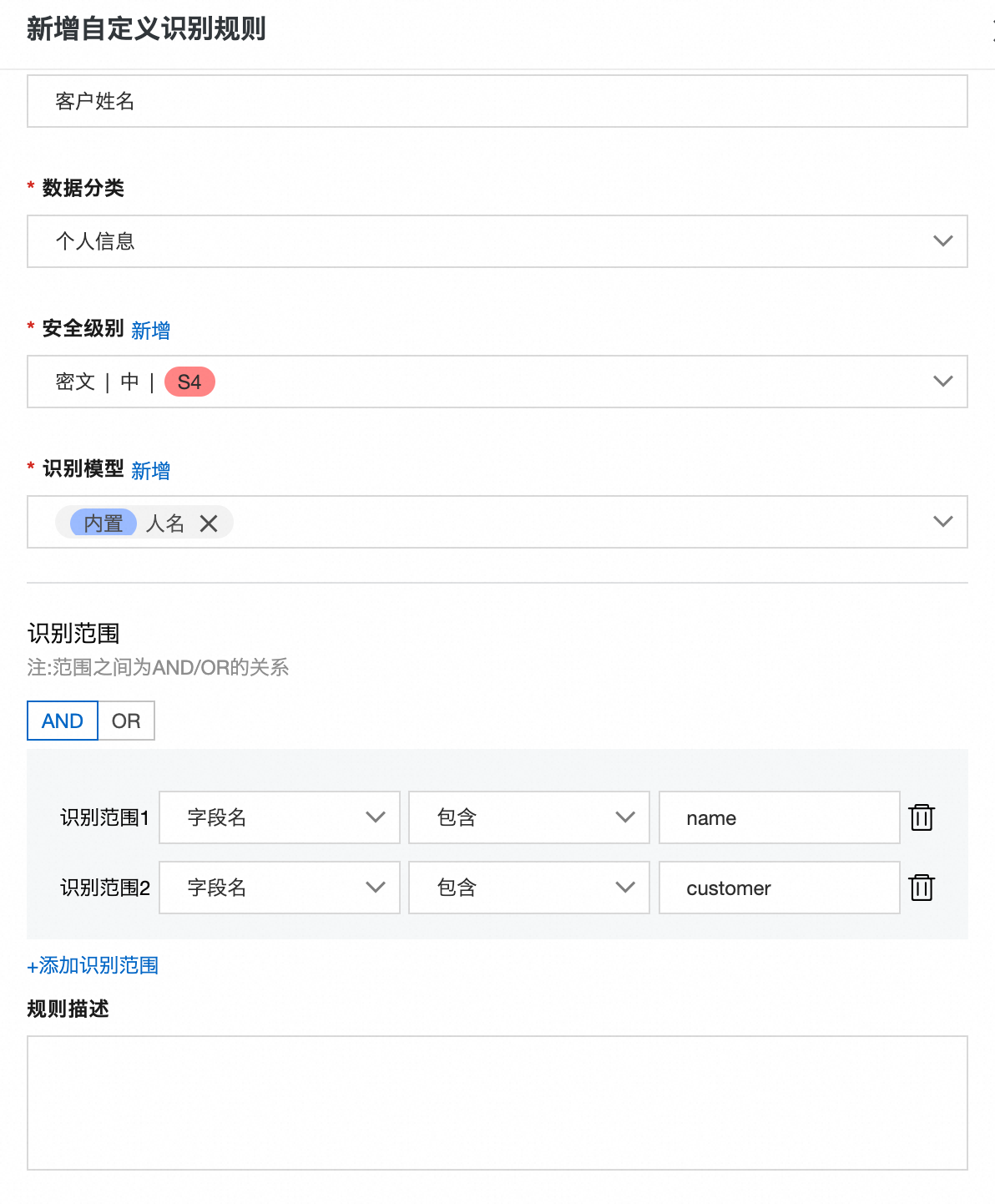
安全層級:使用者可自訂欄位的安全層級,等級越高表示資料越敏感、越重要。更多資訊,請參見欄位安全層級。
識別模型:該識別規則對應的底層識別模型,可多選,邏輯關係為OR。例如某一欄位命中了多個識別模型,只要該規則的識別模型中包含其中一種即可。
識別範圍:篩選中繼資料。識別範圍之間的關係包含AND或OR,若為AND,則欄位的中繼資料必須符合所有的識別範圍;若為OR,則欄位中繼資料符合其中一種即可。