資料湖構建(DLF)可以結合阿里雲Realtime ComputeFlink版(Flink VVP),以及Flink CDC相關技術,實現靈活定製化的資料入湖。並利用DLF統一中繼資料管理、許可權管理等能力,實現資料湖多引擎分析、資料湖管理等功能。本文為您介紹Flink+DLF資料湖方案具體步驟。
背景資訊
阿里雲Realtime ComputeFlink版是一套基於Apache Flink構建的即時巨量資料分析平台,支援多種資料來源和結果表類型。Flink任務可以利用資料湖統一儲存的優勢,使用Hudi結果表或Iceberg結果表,將作業的結果輸出到資料湖中,實現資料湖分析。在寫入資料湖的過程中,Flink可以通過設定DLF Catalog,將表的中繼資料同步到資料湖構建(DLF)中。依託資料湖構建產品(DLF)提供的企業級統一中繼資料能力,Flink+DLF方案可以實現寫入的資料湖表無縫對接阿里雲上的計算引擎,如EMR、MaxCompute、Hologres等。也可以通過DLF提供的豐富的資料湖管理能力,實現資料湖生命週期管理和湖格式的最佳化。
前提條件
已開通阿里雲Realtime ComputeFlink版,建立Flink全託管工作空間。
已開通阿里雲資料湖構建(DLF)服務。如果您沒有開通,則可以在DLF產品首頁,單擊開通。
本文以MySQL資料來源為例,需要建立RDS MySQL,詳情請參見建立RDS MySQL執行個體。如果使用其他資料來源入湖可忽略。
建立的RDS MySQL需要和Realtime ComputeFlink版在同一個地區同一個VPC內,RDS MySQL須為5.7及以上版本。
操作流程
步驟一:準備MySQL資料
登入準備好的MySQL執行個體,詳情請參見通過DMS登入RDS MySQL。
執行如下命令,建立一張表,並插入若干測試資料。
CREATE DATABASE testdb; CREATE TABLE testdb.student ( `id` bigint(20) NOT NULL, `name` varchar(256) DEFAULT NULL, `age` bigint(20) DEFAULT NULL, PRIMARY KEY (`id`) ); INSERT INTO testdb.student VALUES (1,'name1',10); INSERT INTO testdb.student VALUES (2,'name2',20);
步驟二:Flink建立DLF Catalog
進入建立Catalog頁面。
在Flink全託管頁簽,單擊目標工作空間操作列下的控制台。
在左側導覽列,單擊中繼資料管理。
單擊建立Catalog。
建立DLF Catalog。
在建立Catalog頁面,選擇DLF,單擊下一步。
填寫以下參數配置資訊,單擊確定。詳情請參見管理DLF Catalog。
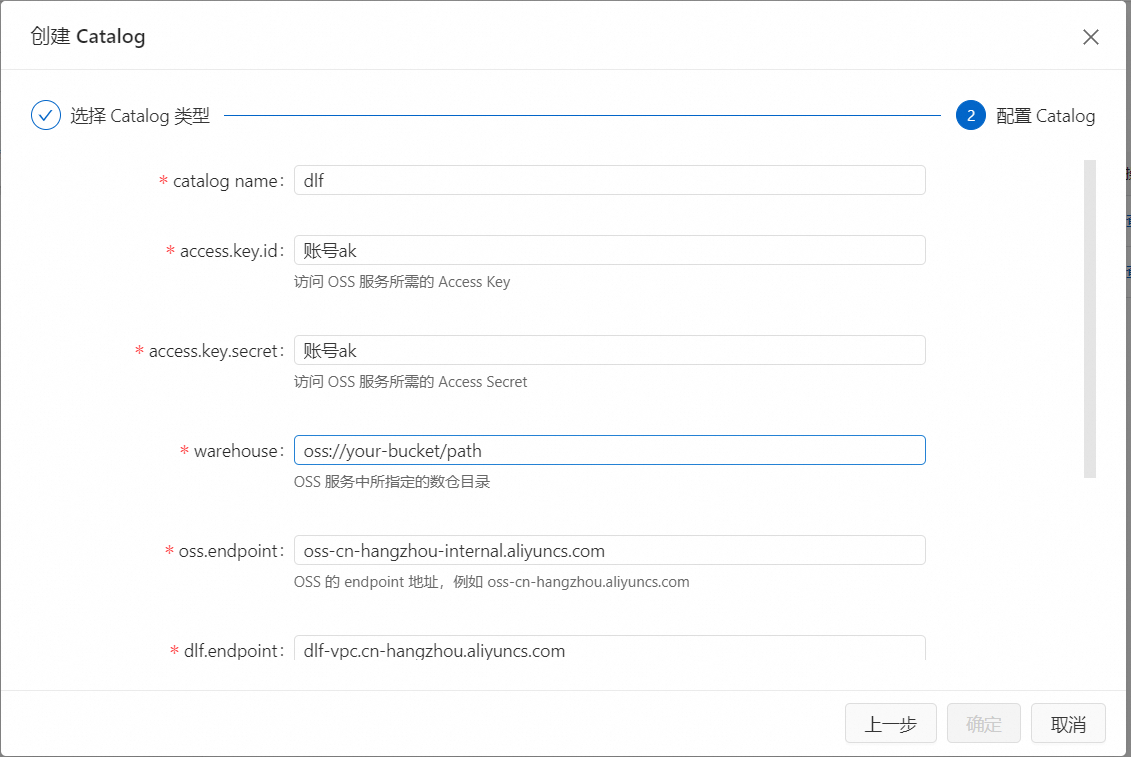
當您成功建立DLF之後,可在中繼資料管理中看到新增的dlf資料目錄,預設連結的是DLF的default資料目錄。

步驟三:建立Flink入湖作業
在Flink全託管頁簽,單擊目標工作空間操作列下的控制台。
建立資料來源表和目標表。
在左側導覽列,單擊。
在SQL編輯地區,輸入以下代碼,單擊運行。
-- 建立資料來源表 CREATE TABLE IF NOT EXISTS student_source ( id INT, name VARCHAR (256), age INT, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', -- hostname替換為RDS的串連地址 'hostname' = 'rm-xxxxxxxx.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = '<RDS user name>', 'password' = '<RDS password>', 'database-name' = '<RDS database>', -- table-name為資料來源表,本例中填步驟二建立的student表 'table-name' = 'student' ); -- catalog名為步驟二建立的dlf catalog name,本例中填dlf CREATE DATABASE IF NOT EXISTS dlf.dlf_testdb; -- 建立目標表 CREATE TABLE IF NOT EXISTS dlf.dlf_testdb.student_hudi ( id BIGINT PRIMARY KEY NOT ENFORCED, name STRING, age BIGINT ) WITH( 'connector' = 'hudi' );建立成功後,可在中繼資料管理中看到新增的資料來源表和目標表。
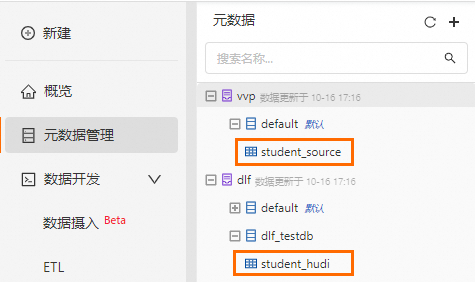
建立Flink SQL入湖作業。
在左側導覽列,單擊。
單擊建立後,在新增作業草稿對話方塊,選擇空白的流作業草稿,單擊下一步。
填寫作業資訊,單擊建立。
在SQL編輯地區,輸入以下代碼,建立一個Flink SQL作業。
-- 建立流SQL作業 INSERT INTO dlf.dlf_testdb.student_hudi SELECT * FROM student_source /*+ OPTIONS('server-id'='123456') */;說明關於MySQL源表的參數設定和使用條件,請參見MySQL的CDC源表。
關於Hudi結果表的參數設定,請參見Hudi結果表。
在SQL編輯地區右上方,單擊部署。在部署新版本對話方塊,可根據需要填寫或選中相關內容,單擊確定。
啟動作業。
在左側導覽列,單擊。
單擊目標作業名稱操作列中的啟動。
選擇無狀態啟動後,單擊啟動。當您看到作業狀態變為運行中,則代表作業運行正常。作業啟動參數配置,詳情請參見作業啟動。
步驟四:使用DLF資料湖分析
在左側導覽列,單擊。
在SQL編輯地區,輸入以下代碼,單擊運行。
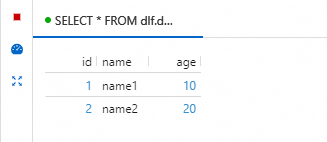
SELECT * FROM dlf.dlf_testdb.student_hudi;查詢結果如下圖所示,可以直接對Flink寫入資料湖的資料進行查詢和分析。
如果您購買了EMR叢集,並且開啟了資料湖DLF中繼資料,也可以直接通過EMR叢集對Flink入湖結果進行資料湖分析,參考Hudi與Spark SQL整合。
相關資料
如果您想要通過EMR DataFlow叢集的Flink讀寫DLF,請參考文章DataFlow叢集通過DLF讀寫Hudi表。