企業構建和應用資料湖一般需要經歷資料入湖、資料湖儲存與管理、資料湖探索與分析等幾個過程。本文主要介紹基於阿里雲資料湖構建(DLF)構建一站式的資料入湖與分析實戰。
背景資訊
隨著資料時代的不斷髮展,資料量爆髮式增長,資料形式也變的更加多樣。傳統資料倉儲模式的成本高、響應慢、格式少等問題日益凸顯。於是擁有成本更低、資料形式更豐富、分析計算更靈活的資料湖應運而生。
資料湖作為一個集中化的資料存放區倉庫,支援的資料類型具有多樣性,包括結構化、半結構化以及非結構化的資料,資料來源上包含資料庫資料、binglog 增量資料、日誌資料以及已有數倉上的存量資料等。資料湖能夠將這些不同來源、不同格式的資料集中儲存管理在高性價比的儲存如 OSS等Object Storage Service中,並對外提供統一的資料目錄,支援多種計算分析方式,有效解決了企業中面臨的資料孤島問題,同時大大降低了企業儲存區和使用資料的成本。
企業級資料湖架構

資料湖儲存與格式
資料湖儲存主要以雲上Object Storage Service作為主要介質,其具有低成本、高穩定性、高可擴充性等優點。
資料湖上我們可以採用支援ACID的資料湖儲存格式,如Delta Lake、Hudi、Iceberg。這些資料湖格式有自己的資料meta管理能力,能夠支援Update、Delete等操作,以批流一體的方式解決了巨量資料情境下資料即時更新的問題。
資料湖構建與管理
1. 資料入湖
企業的未經處理資料存在於多種資料庫或儲存系統,如關聯式資料庫MySQL、日誌系統SLS、NoSQL儲存HBase、訊息資料庫Kafka等。其中大部分的線上儲存都面向線上事務型業務,並不適合線上分析的情境,所以需要將資料以無侵入的方式同步至成本更低且更適合計算分析的Object Storage Service。
常用的資料同步方式有基於DataX、Sqoop等資料同步工具做批量同步;同時在對於即時性要求較高的情境下,配合使用Kafka+spark Streaming / flink等流式同步鏈路。目前很多雲廠商提供了一站式入湖的解決方案,協助客戶以更快捷更低成本的方式實現資料入湖,如阿里雲DLF資料入湖。
2. 統一中繼資料服務
Object Storage Service本身是沒有面向巨量資料分析的語義的,需要結合Hive Metastore Service等中繼資料服務為上層各種分析引擎提供資料的Meta資訊。
資料湖計算與分析
相比於資料倉儲,資料湖以更開放的方式對接多種不同的計算引擎,如傳統開源巨量資料計算引擎Hive、Spark、Presto、Flink等,同時也支援雲廠商自研的巨量資料引擎,如阿里雲MaxCompute、Hologres等。在資料湖儲存與計算引擎之間,一般還會提供資料湖加速的服務,以提高計算分析的效能,同時減少頻寬的成本和壓力。

操作流程
資料湖構建與分析鏈路
企業構建和應用資料湖一般需要經歷資料入湖、資料湖儲存與管理、資料湖探索與分析等幾個過程。本文主要介紹基於阿里雲資料湖構建(DLF)構建一站式的資料入湖與分析實戰。
其主要資料鏈路如下:
步驟一:服務開通並準備資料
1. 服務開通
確保DLF、OSS、DDI、RDS、DTS等雲產品服務已開通。注意DLF、RDS、DDI執行個體均需在同一Region下。
2. 資料準備
RDS資料準備,在RDS中建立資料庫dlf-demo。在賬戶中心建立能夠讀取employees資料庫的使用者帳號,如dlf_admin。

通過DMS登入資料庫,運行以下語句建立employees表,及插入少量資料。
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
`create_time` DATETIME NOT NULL,
`update_time` DATETIME NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
INSERT INTO `employees` VALUES (10001,'1953-09-02','Georgi','Facello','M','1986-06-26', now(), now());
INSERT INTO `employees` VALUES (10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21', now(), now());
步驟二:資料入湖
1. 建立資料來源
a. 進入DLF控制台介面:https://dlf.console.alibabacloud.com/cn-hangzhou/home,點擊菜單“資料入湖 -> 資料來源管理”。
b. 點擊“建立資料來源”。填寫串連名稱,選擇資料準備中的使用的RDS執行個體,填寫帳號密碼,點擊“串連測試”驗證網路連通性及帳號可用性。

 c. 點擊下一步,確定,完成資料來源建立。
c. 點擊下一步,確定,完成資料來源建立。
2. 建立中繼資料庫
a. 在OSS中建立Bucket,dlf-demo;
b. 點擊左側菜單“中繼資料管理”->“中繼資料庫”,點擊“建立中繼資料庫”。填寫名稱,建立目錄delta-test,並選擇。

3. 建立入湖任務
a. 點擊菜單“資料入湖”->“入湖任務管理”,點擊“建立入湖任務”。
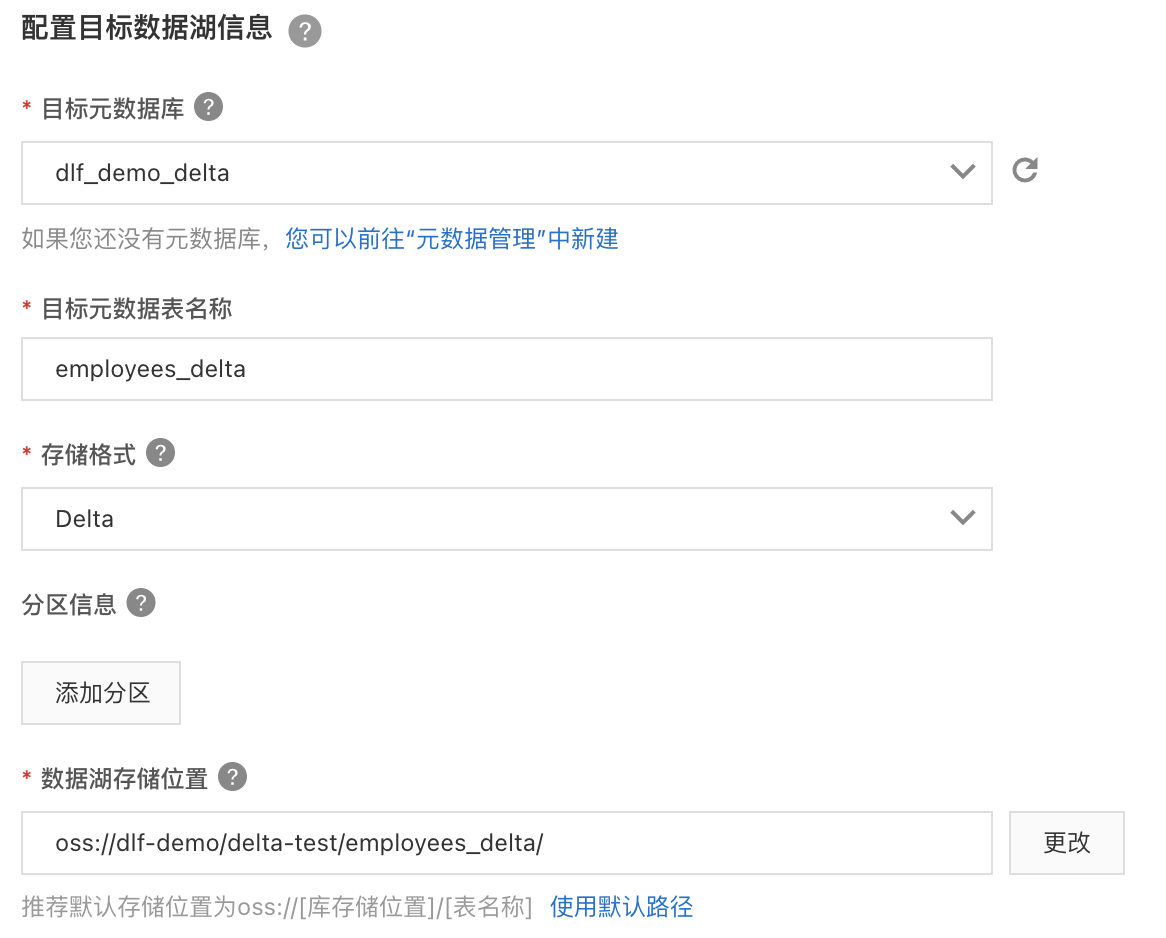
b. 選擇“關聯式資料庫即時入湖”,按照下圖的資訊填寫資料來源、目標資料湖、任務配置等資訊。並儲存。
c. 配置資料來源,選擇剛才建立的“dlf_demo”串連,使用表路徑 “dlf_demo/employees”,選擇建立DTS訂閱,填寫名稱。


d. 回到任務管理頁面,點擊“運行”建立的入湖任務。就會看到任務進入“初始化中”狀態,隨後會進入“運行”狀態。
e. 點擊“詳情”進入任務詳情頁,可以看到相應的資料庫表資訊。

該資料入湖任務,屬於全量+增量入湖,大約3至5分鐘後,全量資料會完成匯入,隨後自動進入即時監聽狀態。如果有資料更新,則會自動更新至Delta Lake資料中。
步驟三:資料湖探索與分析
DLF產品提供了輕量級的資料預覽和探索功能,點擊菜單“資料探索”->“SQL查詢”進入資料查詢頁面。
a. 在中繼資料庫表中,找到“dlf_demo_delta”,展開後可以看到employees表已經自動建立完成。雙擊該表名稱,右側sql編輯框會出現查詢該表的sql語句,點擊“運行”,即可獲得資料查詢結果。

b. 回到DMS控制台,運行下方update、delete和insert SQL語句。
update `employees` set `first_name` = 'dlf-demo', `update_time` = now() where `emp_no` =10001;
delete FROM `employees` where `emp_no` = 10002;
INSERT INTO `employees` VALUES (10011,'1953-11-07','dlf-insert','Sluis','F','1990-01-22', now(), now());
c. 大約1至3分鐘後,在DLF 資料探索再次執行剛才的select語句,所有的資料更新已經同步至資料湖中。
