DataWorks的Data Integration為您提供MongoDB Writer外掛程式,可從其他資料來源中讀取資料,並將資料同步至MongoDB。本文以一個具體的樣本,為您示範如何通過Data Integration將MaxCompute的資料離線同步至MongoDB。
前提條件
本實踐進行操作時,需滿足以下條件。
已開通DataWorks並建立MaxCompute資料來源。
本實踐使用獨享Data Integration資源群組進行離線任務運行,因此您需先購買並配置獨享Data Integration資源群組。操作詳情請參見新增和使用獨享Data Integration資源群組。
說明您也可以使用新版資源群組(通用型資源群組),更多資訊,請參見新增和使用新版通用型資源群組。
準備樣本資料表
本實踐需準備一個MongoDB資料集合、一個MaxCompute表,用於後續進行離線資料同步。
準備MaxCompute表並構造表資料。
建立一個名稱為
test_write_mongo的分區表,分區欄位為pt。CREATE TABLE IF NOT EXISTS test_write_mongo( id STRING , col_string STRING, col_int int, col_bigint bigint, col_decimal decimal, col_date DATETIME, col_boolean boolean, col_array string ) PARTITIONED BY (pt STRING) LIFECYCLE 10;添加一個分區取值
20230215。insert into test_write_mongo partition (pt='20230215') values ('11','name11',1,111,1.22,cast('2023-02-15 15:01:01' as datetime),true,'1,2,3');檢查分區表是否正確建立。
SELECT * FROM test_write_mongo WHERE pt='20230215';
準備MongoDB資料集合,後續將MaxCompute資料同步至此MongoDB資料集合。
本實踐使用阿里雲ApsaraDB for MongoDB作為樣本,建立一個名稱為
test_write_mongo的資料集合。db.createCollection('test_write_mongo')
離線任務配置
step1:添加MongoDB資料來源
添加一個MongoDB資料來源,保障資料來源與獨享Data Integration資源群組之間網路連通。操作詳情請參見配置MongoDB資料來源。
step2:建立離線同步節點,並配置離線同步任務
在DataWorks的DataStudio中建立一個離線同步節點,並配置離線同步的來源與去向等任務配置參數,核心配置要點如下,其他參數可保持預設值即可。詳細操作請參見通過嚮導模式配置離線同步任務。
配置同步網路連接。
選擇上述步驟中建立的MongoDB、MaxCompute資料來源和對應的獨享Data Integration資源群組,測試完成連通性。
配置任務:選擇資料來源。
選擇上述準備資料步驟中準備的MaxCompute分區表和MongoDB資料集合。任務關鍵參數配置詳細介紹如下。
參數
配置說明
寫入模式(是否覆蓋)
指定了傳輸資料時是否覆蓋的資訊,包括
寫入模式和業務主鍵:寫入模式:當設定為否時,每條寫入資料執行插入。此選項為預設項。
當設定為是時,需指定
業務主鍵,表示針對相同的業務主鍵做覆蓋操作。
業務主鍵:指定了每行記錄的業務主鍵,用來做覆蓋時使用(不支援配置為多個業務主鍵,通常指Mongo中的主鍵)。
說明當
寫入模式設定為是,且將非 _id欄位配置為業務主鍵,任務運行時可能會出現類似以下的報錯:After applying the update, the (immutable) field '_id' was found to have been altered to _id: "2"原因是寫入資料中,存在 _id與 replaceKey不匹配的資料,詳情請參報錯:After applying the update, the (immutable) field '_id' was found to have been altered to _id: "2"。匯入前準備語句
即前置條件(PreSQL)的配置。配置格式為JSON格式,包含了
type和json兩個屬性。type:必填項,可取值為:remove、drop(注意為小寫字母)。json:當
type為remove時,為必填項,配置文法為MongoDB的標準Query,詳情請參見Query Documents。當
type為drop時,無需填寫。
配置任務:欄位對應。
資料來源為MongoDB時,預設使用同行映射。您也可以單擊
 表徵圖手動編輯源表欄位,手動編輯的樣本如下。
表徵圖手動編輯源表欄位,手動編輯的樣本如下。{"name":"id","type":"string"} {"name":"col_string","type":"string"} {"name":"col_int","type":"long"} {"name":"col_bigint","type":"long"} {"name":"col_decimal","type":"double"} {"name":"col_date","type":"date"} {"name":"col_boolean","type":"bool"} {"name":"col_array","type":"array","splitter":","}手動後,介面可展示來源欄位與目標欄位的映射關係。
step3:提交發布離線同步節點
如果您使用的是標準模式的DataWorks工作空間,並且希望後續在生產環境中周期性調度此離線同步任務的話,您可以將離線同步節點提交發布到生產環境。操作詳情請參見發布任務。
step4:運行離線同步節點,查看同步結果
完成上述配置後,您可以運行同步節點,待運行完成後,查看同步至MongoDB資料集合中的資料。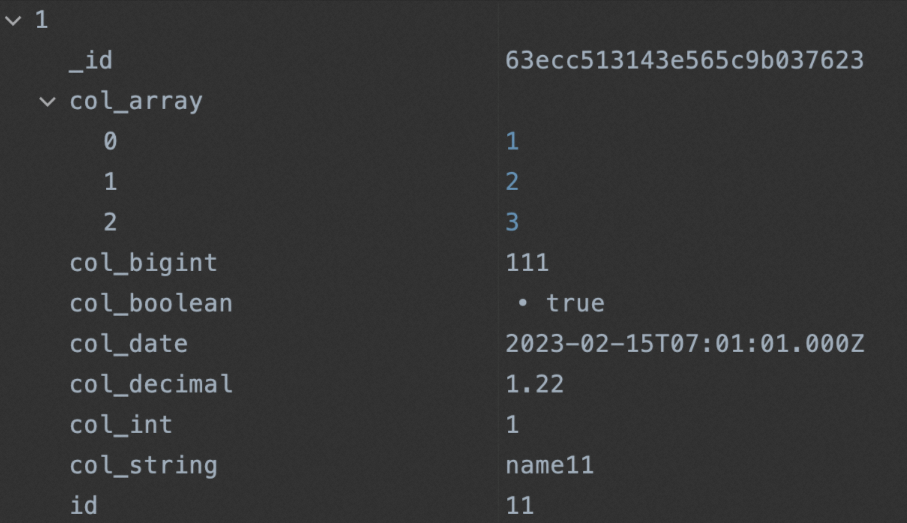
附錄:同步過程中的資料格式轉換說明
關於type取值
支援的type包括:INT、LONG、DOUBLE、STRING、BOOL、DATE、ARRAY。
關於數群組類型
當配置類型為ARRAY時,需配置對應的splitter屬性,可以輸出到MongoDB的數群組類型。如:
源端資料為字串:
a,b,c。同步任務配置type為
ARRAY,splitter為,。同步任務執行後,寫入MongoDB的資料為:
["a","b","c"]。