本文為您介紹即時同步任務延遲時的自助解決方案。
確認造成延遲問題在同步任務的讀端還是寫端
如果是在DataStudio建立的即時同步任務,您需要在介面單擊運行中的任務名稱,彈出任務運行詳情對話方塊。詳情請參見即時同步任務運行與管理。
在運行資訊詳情中,查看視窗等待時間(5 min),該指標表示最近5分鐘視窗內,同步任務讀取資料或寫入資料的等待時間。用於協助您判斷資料同步延遲的瓶頸方,當資料同步發生延遲時,指標資料較大的一般為瓶頸方。

確認造成延遲問題的系統是否有異常
當確認了延遲瓶頸是在同步任務的讀端還是寫端後,可在上述任務運行詳情中切換至日誌頁簽,使用Error/error/Exception/exception/OutOfMemory等關鍵字搜尋,查看在延遲時間段內是否有類似下圖所示的相關異常棧,如果有,根據異常資訊,參考常見異常處理辦法,判斷是否可以通過最佳化任務配置進行解決。
即時同步任務從一個系統讀資料,並將資料寫入另一個系統,當寫資料比讀資料慢時,則讀資料一側的系統會受到反壓,導致速度變慢。即造成瓶頸的系統可能會由於反壓導致另一側系統的一些異常,此時要優先關注造成瓶頸的系統的異常情況。
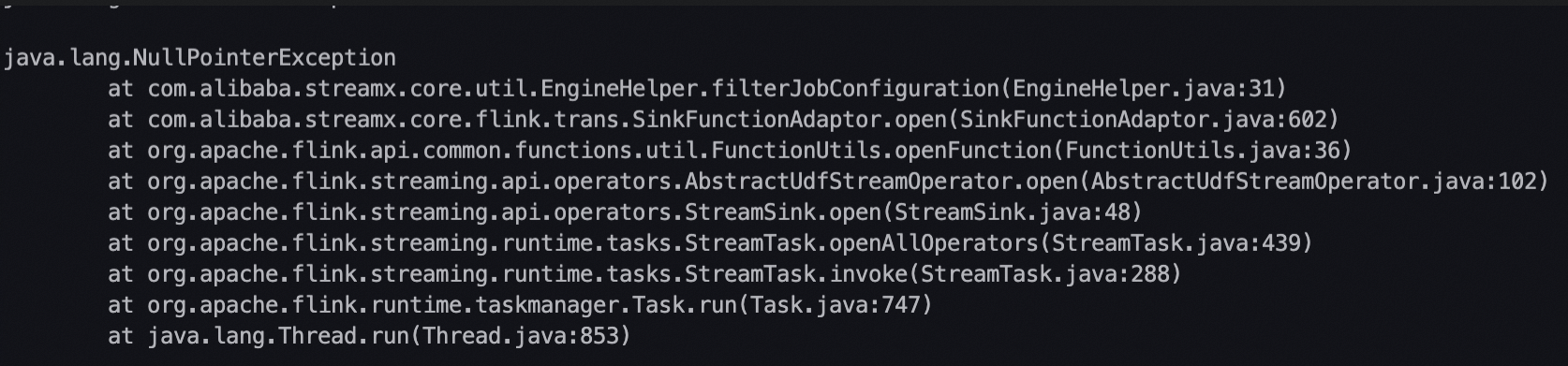
確認即時同步任務是否有頻繁OOM
您還可以在上述任務運行詳情介面中切換到Failover頁面,確認任務是否有頻繁的Failover(10分鐘內發生1一次以上Failover則表示頻繁),如果有,可在Failover事件列查看導致Failover的異常資訊,並單擊查看詳情連結查看Failover發生前的完整任務日誌,如果在Failover事件列的異常資訊或者任務作業記錄中能夠搜尋到OutOfMemory關鍵字的異常資訊,則說明即時同步任務記憶體設定不足,需要加大任務記憶體設定。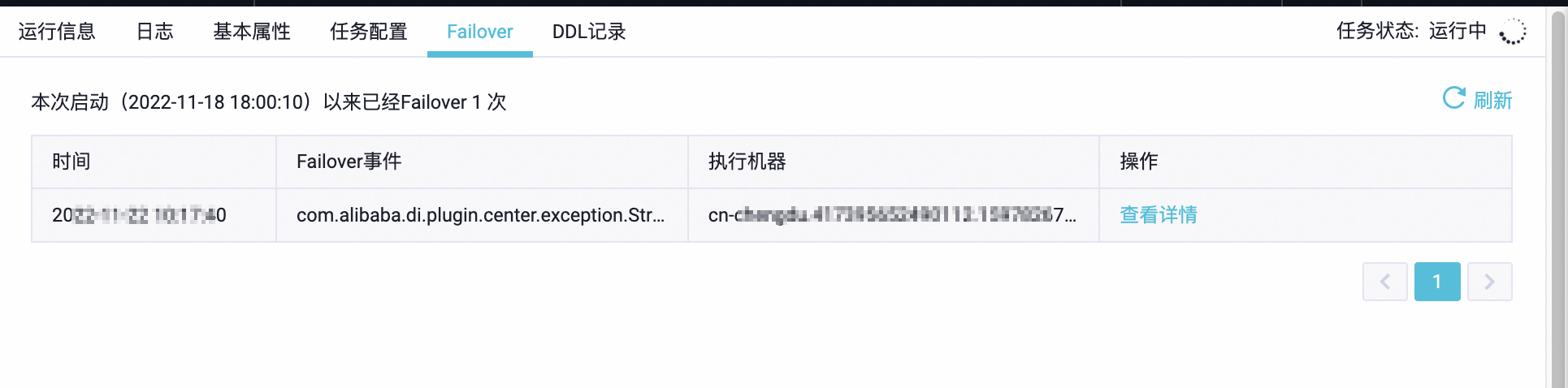
任務記憶體設定方法如下:
對於DataStudio建立的單表到單表ETL即時同步任務,您可以單擊右側的基本配置設定任務記憶體。

在DataStudio建立的資料庫遷至DataHub等類型即時同步任務,您可以單擊右側的基本配置設定任務記憶體。
同步解決方案任務,您可以在運行資源設定步驟中設定記憶體。
確認源端資料是否有傾斜或者是否需要擴充分區或shard的數量
對於源端是Kafka、DataHub和Loghub三種類型的即時同步任務,如果根據上述步驟未發現異常或Failover,則需要檢查源端系統資料是否有傾斜或者分區、shard的讀取流量是否達到了同步速率的上限。
對於源端是Kafka、DataHub和Loghub三種類型的即時同步任務,每個分區或者shard只能由一個並發消費,如果存在寫入源端系統的資料集中在個別分區或者shard,而其他分區或shard資料很少的情況,則很可能導致資料扭曲分區或shard的消費瓶頸,造成延遲。此時將無法通過Data Integration任務設定解決延遲問題,需要從Kafka、DataHub和Loghub系統的上遊資料生產側解決資料寫入傾斜問題後,延遲問題才能恢複。
您可以通過在上述任務運行詳情中切換到運行資訊頁簽,查看不同Reader線程總位元組數統計,如果有個別Reader現場總位元組數明顯大於其他Reader線程,可以判斷存在資料扭曲情況。但由於總位元組數包括任務從上次指錨點啟動開始的資料量,如果任務已耗用時間已經很長,則可能無法反映出最近的資料扭曲情況,您需要繼續通過源端系統的監控指標確認是否存在資料扭曲情況。
如果寫入源端系統的單個分區或者shard資料流量已經達到了同步速率的上限,例如,Kafka叢集側可以對分區讀取流量配置限流、DataHub單分區的最大讀取流量有4MB/s限制、Loghub單shard最大讀取流量有10MB/s限制,如果即時同步任務對於單分區的讀取速度超過了限制,則可通過擴充源端系統磁碟分割或shard數量來解決延遲。
如果有多個即時同步任務消費同一個Kafka Topic、DataHub Topic或者Loghub logstore的情況,您需要注意所有即時同步任務的讀取速度之和是否超過限制。
確認MySQL源端是否有提交大事務或者變更過於頻繁(如大量的DML和DDL的操作)
對於源端是MySQL的即時同步任務,如果根據上述步驟未發現異常或Failover,則需要檢查源端系統是否提交了大事務或者源端系統變更過於頻繁(如大量的DML和DDL的操作),導致Binlog增長過快超過同步任務消費速度導致延遲。
例如,更新全表某個欄位的值或者刪除大量資料等。您可以在任務運行詳情中切換到運行資訊頁簽,查看任務同步速度:
當同步速度很大時,說明Binlog增長速度快。
當同步速度不大,您可以在MySQL服務端查看Binlog的統計指標和審計日誌確認實際增長速率。
但同步速度可能無法反映當前同步任務消費MySQL源端Binlog的實際速度,因為當事務或者變更涉及的庫表沒有包含在同步任務的配置中,同步任務會將這部分資料在讀取過後過濾掉,也不計入對同步速度和資料量統計。
如果確認是大事務或者臨時的大量變更導致了任務延遲,則可以等待大事務或者大量變更包含的變更資料被同步任務處理完成後,任務延遲會逐步被追上。
確認是否有寫入動態分區頻繁切換問題(uploader map size has reached uploaderMapMaximumSize)
對於寫入MaxCompute的即時同步任務,當分區方式選擇根據欄位內容動態分區時,要特別注意選擇對應於MaxCompute表分區列的源端列,在即時同步任務右側基本配置中配置的Flush間隔內(預設為1分鐘)包含的可枚舉值個數不能太大。
由於在Flush間隔內待寫入MaxCompute表的資料實際是在即時同步任務的一組隊列中儲存,每個隊列會緩衝一個MaxCompute的寫入資料,隊列的預設最大個數是5個,如果對應於MaxCompute表分區列的源端列在配置的Flush間隔內可枚舉值個數超過了緩衝隊列的最大個數,會立即觸發對所有寫入資料的Flush操作,而頻繁的Flush操作將嚴重影響寫入效能。
您需要確認是否存在MaxCompute表分區緩衝隊列個數耗盡觸發頻繁Flush操作問題。您可以在即時同步任務的運行詳情頁切換到日誌頁簽,在日誌中搜尋是否有uploader map size has reached uploaderMapMaximumSize。
增加並發設定或開啟分布式運行模式解決延遲問題
如果根據上述步驟確認非讀寫異常引發的任務延遲,而是源端業務流量增長導致的延遲,則需要通過提高即時同步任務並發設定緩解延遲。
並發加大後也需要同步增加任務的記憶體設定,比例關係可以按照並發每增大4,記憶體增加1GB。
任務並發及記憶體設定方法如下:
對於DataStudio建立的單表到單表ETL即時同步任務,您可以單擊右側的基本配置設定任務並發和記憶體。
在DataStudio建立的資料庫遷至DataHub等類型即時同步任務,您可以在運行資源設定步驟中設定並發,在右側的基本配置設定任務記憶體。
同步解決方案任務,您可以在運行資源設定步驟中設定並發和記憶體。
在未開啟分布式運行模式情況下,任務並發建議不超過32,如果超過20則會由於單機資源瓶頸導致任務延遲,此時特定通道可以通過開啟分布式運行模式提升效能,目前支援開啟分布式運行模式的通道如下:
任務類型 | 源端 | 目標端 |
DataStudio ETL任務 | Kafka | MaxCompute |
DataStudio ETL任務 | Kafka | Hologres |