MySQL資料來源為您提供讀取和寫入MySQL的雙向通道,本文為您介紹DataWorks的MySQL資料同步能力的支援情況。
支援的MySQL版本
離線讀寫:
支援MySQL 5.5.x、MySQL 5.6.x、MySQL 5.7.x、MySQL 8.0.x,相容Amazon RDS for MySQL、Azure MySQL、Amazon Aurora MySQL。
離線同步支援閱讀檢視表。
即時讀取:
Data Integration即時讀取MySQL資料是基於即時訂閱MySQL實現的,當前僅支援即時同步MySQL 5.5.x、MySQL 5.6.x、MySQL 5.7.x、MySQL 8.0.x(非8.0新特性,比如functional index,僅相容原有功能)版本的MySQL資料,相容Amazon RDS for MySQL、Azure MySQL、Amazon Aurora MySQL。
重要如果需要同步DRDS的MySQL,請不要將DRDS的MySQL配置為MySQL資料來源,您可以參考配置DRDS資料來源文檔直接將其配置為DRDS資料來源。
使用限制
即時讀
不支援同步5.6.x版本以下的MySQL唯讀庫執行個體的資料。
不支援同步含有Functional Index的表。
不支援XA ROLLBACK。
針對已經XA PREPARE的交易資料,即時同步會將其同步到目標端,如果XA ROLLBACK,即時同步不會針對XA PREPARE的資料做復原寫入的操作。若要處理XA ROLLBACK情境,需要手動將XA ROLLBACK的表從即時同步任務中移除,再添加表後重新進行同步。
僅支援同步MySQL伺服器Binlog配置格式為ROW。
即時同步不會同步被串聯刪除的關聯表記錄。
對於Amazon Aurora MySQL資料庫,需要串連到您的主/寫資料庫,因為AWS不允許在Aurora MySQL的唯讀副本上啟用Binlog功能。即時同步任務需要Binlog來執行累加式更新。
即時同步線上DDL變更僅支援通過Data Management對MySQL表進行加列(Add Column)線上DDL變更。
不支援讀取MySQL中的預存程序。
離線讀
MySQL Reader外掛程式在進行分庫分表等多表同步時,若要對單表進行切分,則需要滿足任務並發數大於表個數這一條件,否則切分的Task數目等於表的個數。
不支援讀取MySQL中的預存程序。
支援的欄位類型
各版本MySQL的全量欄位類型請參見MySQL官方文檔。以下以MySQL 8.0.x為例,為您羅列當前主要欄位的支援情況。
欄位類型 | 離線讀(MySQL Reader) | 離線寫(MySQL Writer) | 即時讀 | 即時寫 |
TINYINT | ||||
SMALLINT | ||||
INTEGER | ||||
BIGINT | ||||
FLOAT | ||||
DOUBLE | ||||
DECIMAL/NUMBERIC | ||||
REAL | ||||
VARCHAR | ||||
JSON | ||||
TEXT | ||||
MEDIUMTEXT | ||||
LONGTEXT | ||||
VARBINARY | ||||
BINARY | ||||
TINYBLOB | ||||
MEDIUMBLOB | ||||
LONGBLOB | ||||
ENUM | ||||
SET | ||||
BOOLEAN | ||||
BIT | ||||
DATE | ||||
DATETIME | ||||
TIMESTAMP | ||||
TIME | ||||
YEAR | ||||
LINESTRING | ||||
POLYGON | ||||
MULTIPOINT | ||||
MULTILINESTRING | ||||
MULTIPOLYGON | ||||
GEOMETRYCOLLECTION |
準備工作
配置DataWorks資料來源前,請按本文指引完成MySQL環境準備,確保後續任務正常運行。
以下為您介紹MySQL同步前的相關環境準備。
確認MySQL版本
Data Integration對MySQL版本有要求,您可參考上文支援的MySQL版本章節,查看當前待同步的MySQL是否符合版本要求。您可以在MySQL資料庫通過如下語句查看當前MySQL資料庫版本。
SELECT version();配置帳號許可權
建議您提前規劃並建立一個專用於DataWorks訪問資料來源的MySQL帳號,操作如下。
可選:建立帳號。
操作詳情請參見建立MySQL帳號。
配置許可權。
離線
在離線同步情境下:
在離線讀MySQL資料時,此帳號需擁有同步表的讀(
SELECT)許可權。在離線寫MySQL資料時,此帳號需擁有同步表的寫(
INSERT、DELETE、UPDATE)許可權。
即時
在即時同步情境下,此帳號需要擁有資料庫的
SELECT、REPLICATION SLAVE、REPLICATION CLIENT許可權。
您可以參考以下命令為帳號添加許可權,或直接給帳號賦予
SUPER許可權。如下執行語句在實際使用時,請替換'同步帳號'為上述建立的帳號。-- CREATE USER '同步帳號'@'%' IDENTIFIED BY '密碼'; //建立同步帳號並設定密碼,使其可以通過任意主機登入資料庫。%表示任意主機。 GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '同步帳號'@'%'; //授權同步帳號資料庫的SELECT, REPLICATION SLAVE, REPLICATION CLIENT許可權。*.*表示授權同步帳號對所有資料庫的所有表擁有上述許可權。您也可以指定授權同步帳號對目標資料庫的指定表擁有上述許可權。例如,授權同步帳號對test資料庫的user表擁有上述許可權,則可以使用GRANT SELECT, REPLICATION CLIENT ON test.user TO '同步帳號'@'%';語句。說明REPLICATION SLAVE語句為全域許可權,不能指定授權同步帳號對目標資料庫的指定表擁有相關許可權。
開啟MySQL Binlog(僅即時同步需要)
Data Integration通過即時訂閱MySQL Binlog實現增量資料即時同步,您需要在DataWorks配置同步前,先開啟MySQL Binlog服務。操作如下:
如果Binlog在消費中,則無法被資料庫刪除。如果即時同步任務運行延遲將可能導致源端Binlog長時間被消費,請合理配置任務的延遲警示,並及時關注資料庫的磁碟空間。
Binlog至少保留72小時以上,避免任務失敗後因Binlog已經消失,再啟動無法重設位點到故障發生前而導致的資料丟失(此時只能使用全量離線同步來補齊資料)。
檢查Binlog是否開啟。
使用如下語句檢查Binlog是否開啟。
SHOW variables LIKE "log_bin";返回結果為
ON時,表明已開啟Binlog。如果您使用備用庫同步資料,則還可以通過如下語句檢查Binlog是否開啟。
SHOW variables LIKE "log_slave_updates";返回結果為
ON時,表明備用庫已開啟Binlog。
如果返回的結果與上述結果不符:
開源MySQL請參考MySQL官方文檔開啟Binlog。
阿里雲RDS MySQL請參考RDS MySQL記錄備份開啟Binlog。
阿里雲PolarDB MySQL請參考開啟Binlog開啟Binlog。
查詢Binlog的使用格式。
使用如下語句查詢Binlog的使用格式。
SHOW variables LIKE "binlog_format";返回結果說明:
返回ROW,表示開啟的Binlog格式為
ROW。返回STATEMENT,表示開啟的Binlog格式為
STATEMENT。返回MIXED,表示開啟的Binlog格式為
MIXED。
重要DataWorks即時同步僅支援同步MySQL伺服器Binlog配置格式為ROW。如果返回非ROW請修改Binlog Format。
查詢Binlog完整日誌是否開啟。
使用如下語句查詢Binlog完整日誌是否開啟。
SHOW variables LIKE "binlog_row_image";返回結果說明:
返回FULL,表示Binlog開啟了完整日誌。
返回MINIMAL,表示Binlog開啟了最小日誌,未開啟完整日誌。
重要DataWorks即時同步,僅支援同步開啟了Binlog完整日誌的MySQL伺服器資料。若查詢結果返回非FULL,請修改binlog_row_image的配置。
OSS Binlog讀取授權配置
在添加MySQL資料來源時,如果配置模式為阿里雲執行個體模式,且RDS MySQL執行個體地區與DataWorks專案空間在同一地區,您可以開啟支援OSS binlog讀取,開啟後,在無法訪問RDS Binlog時,將會嘗試從OSS擷取Binlog,以避免即時同步任務中斷。
如果選擇的OSS binlog訪問身份為阿里雲RAM子帳號或阿里雲RAM角色,您還需參考如下方式配置帳號授權。
阿里雲RAM子帳號。
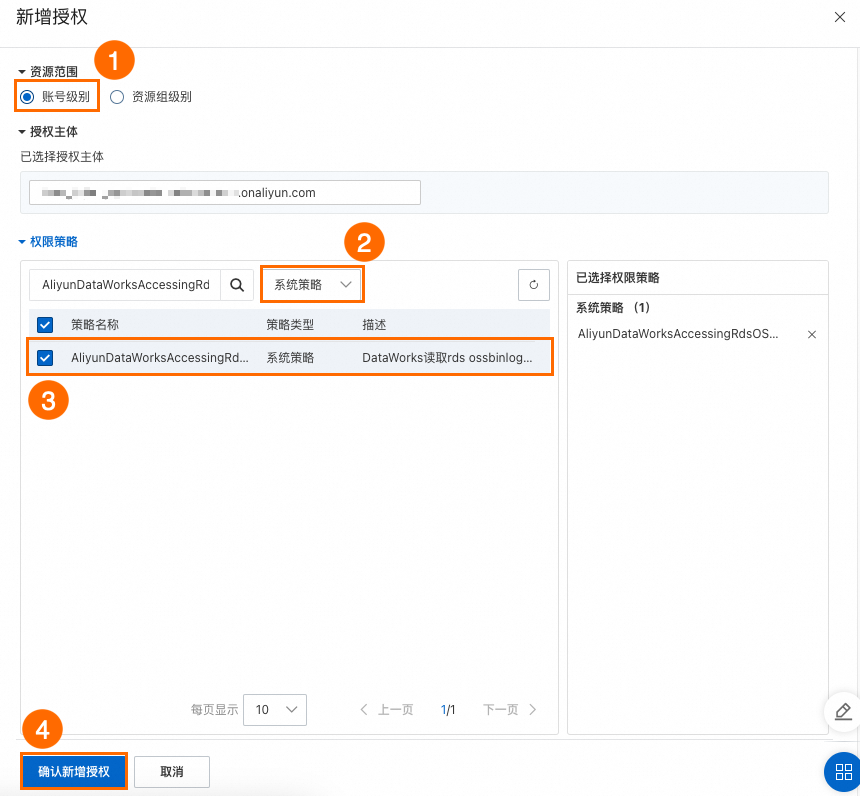
登入RAM 存取控制-使用者控制台,找到需要授權的子帳號。具體操作:
單擊操作列的添加許可權。
配置如下關鍵參數後,單擊確認新增授權。
資源範圍:帳號層級。
權限原則:系統策略。
策略名稱稱:
AliyunDataWorksAccessingRdsOSSBinlogPolicy。
阿里雲RAM角色。
登入RAM 存取控制-角色控制台,建立一個RAM角色。具體操作,請參見建立可信實體為阿里雲帳號的RAM角色。
關鍵參數:
信任主體類型:雲帳號。
信任主體名稱:其他雲帳號,需要填寫DataWorks工作空間所屬的雲帳號。
角色名稱:自訂。
為建立好的RAM角色精確授權。具體操作,請參見管理RAM角色的許可權。
關鍵參數:
權限原則:系統策略。
策略名稱稱:
AliyunDataWorksAccessingRdsOSSBinlogPolicy。
為建立好的RAM角色修改信任策略。具體操作,請參見修改RAM角色的信任策略。
{ "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "Service": [ "<DataWorks使用者主帳號的雲帳號ID>@di.dataworks.aliyuncs.com", "<DataWorks使用者主帳號的雲帳號ID>@dataworks.aliyuncs.com" ] } } ], "Version": "1" }
建立資料來源
阿里雲執行個體模式
若您的MySQL為阿里雲RDS執行個體,建議您選擇阿里雲執行個體模式建立資料來源。參數配置方式如下:
參數 | 說明 |
資料來源名稱 | 資料來源名稱在工作空間內唯一。建議使用可清晰識別業務和環境的命名,例如 |
配置模式 | 此處選擇阿里雲執行個體模式。配置模式說明見:情境1:執行個體模式(當前雲帳號),情境2:執行個體模式(其他雲帳號)。 |
所屬雲帳號 | 根據執行個體的歸屬選擇,若選擇其他雲帳號,需要注意跨帳號許可權配置:跨帳號授權(RDS、Hive或Kafka)。 若選擇其他雲帳號,需填寫以下資訊:
|
地區 | 執行個體所在的地區。 |
執行個體 | 選擇要串連的執行個體名稱。 |
備庫設定 | 如果此資料來源具備唯讀執行個體(備庫),可以在配置任務時選擇備庫讀取。優勢是防止幹擾主庫,不影響主庫效能。 |
執行個體地址 | 選擇正確的執行個體後,點擊擷取最新地址,可以查看執行個體的公網/私網地址、VPC和交換器等資訊。 |
資料庫 | 資料來源要訪問的資料庫名稱。請確保指定的使用者具備對該資料庫的存取權限。 |
使用者名稱/密碼 | MySQL資料庫建立的使用者名稱和密碼。若使用RDS執行個體,可在該執行個體的帳號管理中建立和維護。 |
支援OSS binlog讀取 | 開啟後,在訪問不到RDS binlog時,會嘗試從OSS擷取binlog,避免即時同步任務中斷。配置詳情參見:OSS Binlog讀取授權配置。並根據授權配置,設定OSS binlog訪問身份。 |
認證選項 | 可選擇無認證或SSL認證。若選擇SSL認證,需要執行個體本身開啟SSL認證。準備好認證檔案後上傳至認證檔案管理。 |
版本 | 可以登入MySQL伺服器後,使用SELECT VERSION()查詢來查看版本號碼。 |
串連串模式
你也可以選擇串連串模式建立資料來源,方式更為靈活。串連串模式的參數配置方式如下:
參數 | 說明 |
資料來源名稱 | 資料來源名稱在工作空間內唯一。建議使用可清晰識別業務和環境的命名,例如 |
配置模式 | 此處選擇串連串模式。即通過JDBC URL的方式串連資料庫。 |
串連串預覽 | 填寫完下文的串連地址和資料庫名稱後,DataWorks會自動拼接將其拼接成JDBC URL供您預覽。 |
串連地址 | 主機地址IP:填寫資料庫所在的IP或網域名稱。若該資料庫為阿里雲RDS執行個體,可在該執行個體的詳情頁,點擊資料庫連接查看地址。 連接埠號碼:資料庫連接埠,預設為3306。 |
資料庫名稱 | 資料來源要訪問的資料庫名稱。請確保指定的使用者具備對該資料庫的存取權限。 |
使用者名稱/密碼 | MySQL資料庫建立的使用者名稱和密碼。若使用RDS執行個體,可在該執行個體的帳號管理中建立和維護。 |
版本 | 可以登入MySQL伺服器後,使用SELECT VERSION()查詢來查看版本號碼。 |
認證選項 | 可選擇無認證或SSL認證。若選擇SSL認證,需要執行個體本身開啟SSL認證。準備好認證檔案後上傳至認證檔案管理。 |
進階參數 | 參數:點擊參數下拉框,選擇已支援的參數名稱。如: 值:根據選擇的參數填入合適的值。如:3000。 則URL會自動拼接為: |
請確保資料來源與資源群組的網路聯通,否則後續任務將運行失敗。根據資料來源的網路環境和串連模式配置網路聯通。詳情參見:測試連通性。
資料同步任務開發:MySQL同步流程引導
資料同步任務的配置入口和通用配置流程可參見下文的配置指導。
單表離線同步任務配置指導
指令碼模式配置的全量參數和指令碼Demo請參見下文的附錄:MySQL指令碼Demo與參數說明。
單表即時同步任務配置指導
操作流程請參見DataStudio側即時同步任務配置。
整庫離線、整庫(即時)全增量、整庫(即時)分庫分表等整庫層級同步配置指導
操作流程請參見整庫即時同步任務配置。
常見問題
更多其他Data Integration常見問題請參見Data Integration常見問題。
附錄:MySQL指令碼Demo與參數說明
離線任務指令碼配置方式
如果您配置離線任務時使用指令碼模式的方式進行配置,您需要按照統一的指令碼格式要求,在任務指令碼中編寫相應的參數,詳情請參見指令碼模式配置,以下為您介紹指令碼模式下資料來源的參數配置詳情。
Reader指令碼Demo
本文為您提供單庫單表和分庫分表的配置樣本:
本文JSON樣本中的注釋僅用於展示部分重要參數含義,實際配置時,請移除注釋內容。
配置單庫單表
{ "type": "job", "version": "2.0",//版本號碼。 "steps": [ { "stepType": "mysql",//外掛程式名。 "parameter": { "column": [//列名。 "id" ], "connection": [ { "querySql": [ "select a,b from join1 c join join2 d on c.id = d.id;" ], "datasource": ""//資料來源名稱。 } ], "where": "",//過濾條件。 "splitPk": "",//切分鍵。 "encoding": "UTF-8"//編碼格式。 }, "name": "Reader", "category": "reader" }, { "stepType": "stream", "parameter": {}, "name": "Writer", "category": "writer" } ], "setting": { "errorLimit": { "record": "0"//錯誤記錄數。 }, "speed": { "throttle": true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。 "concurrent": 1,//作業並發數。 "mbps": "12"//限流,此處1mbps = 1MB/s。 } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }配置分庫分表
說明分庫分表是指在MySQL Reader端可以選擇多個MySQL資料表,且表結構保持一致。此處的‘分庫分表’是指多個MySQL寫入同一個目標表,如想要支援整庫層級配置分庫分表,還請在Data Integration網站建立任務並選擇整庫分庫分表能力
{ "type": "job", "version": "2.0", "steps": [ { "stepType": "mysql", "parameter": { "indexes": [ { "type": "unique", "column": [ "id" ] } ], "envType": 0, "useSpecialSecret": false, "column": [ "id", "buyer_name", "seller_name", "item_id", "city", "zone" ], "tableComment": "測試訂單表", "connection": [ { "datasource": "rds_dataservice", "table": [ "rds_table" ] }, { "datasource": "rds_workshop_log", "table": [ "rds_table" ] } ], "where": "", "splitPk": "id", "encoding": "UTF-8" }, "name": "Reader", "category": "reader" }, { "stepType": "odps", "parameter": {}, "name": "Writer", "category": "writer" }, { "name": "Processor", "stepType": null, "category": "processor", "copies": 1, "parameter": { "nodes": [], "edges": [], "groups": [], "version": "2.0" } } ], "setting": { "executeMode": null, "errorLimit": { "record": "" }, "speed": { "concurrent": 2, "throttle": false } }, "order": { "hops": [ { "from": "Reader", "to": "Writer" } ] } }
Reader指令碼參數
指令碼參數名 | 描述 | 是否必選 | 預設值 |
datasource | 資料來源名稱,指令碼模式支援添加資料來源,此配置項填寫的內容必須與添加的資料來源名稱保持一致。 | 是 | 無 |
table | 選取的需要同步的表名稱。一個Data Integration任務只能從一張表中讀取資料。
說明 任務會讀取匹配到的所有表,具體讀取這些表中 | 是 | 無 |
column | 所配置的表中需要同步的列名集合,使用JSON的數組描述欄位資訊。預設使用所有列配置,例如
| 是 | 無 |
splitPk | MySQL Reader進行資料幫浦時,如果指定
| 否 | 無 |
splitFactor | 切分因子,可以配置同步資料的切分份數,如果配置了多並發,會按照 說明 建議取值範圍:1~100,過大會導致記憶體溢出。 | 否 | 5 |
where | 篩選條件,在實際業務情境中,往往會選擇當天的資料進行同步,將
| 否 | 無 |
querySql(進階模式,嚮導模式不支援此參數的配置) | 在部分業務情境中, 說明
| 否 | 無 |
useSpecialSecret | 多來來源資料源時,是否使用各自資料來源的密碼。取值包括:
如果您配置了多個來來源資料源,且各個資料來源使用的使用者名稱密碼不一致,您可以設定使用各自資料來源的密碼,即此參數設定為true。 | 否 | false |
Writer指令碼Demo
{
"type": "job",
"version": "2.0",//版本號碼。
"steps": [
{
"stepType": "stream",
"parameter": {},
"name": "Reader",
"category": "reader"
},
{
"stepType": "mysql",//外掛程式名。
"parameter": {
"postSql": [],//匯入後的準備語句。
"datasource": "",//資料來源。
"column": [//列名。
"id",
"value"
],
"writeMode": "insert",//寫入模式,您可以設定為insert、replace或update。
"batchSize": 1024,//一次性批量提交的記錄數大小。
"table": "",//表名。
"nullMode": "skipNull",//NULL值處理策略。
"skipNullColumn": [//需要跳過NULL值的列。
"id",
"value"
],
"preSql": [
"delete from XXX;"//匯入前的準備語句。
]
},
"name": "Writer",
"category": "writer"
}
],
"setting": {
"errorLimit": {//錯誤記錄數。
"record": "0"
},
"speed": {
"throttle": true,//當throttle值為false時,mbps參數不生效,表示不限流;當throttle值為true時,表示限流。
"concurrent": 1,//作業並發數。
"mbps": "12"//限流,控制同步的最高速率,防止對上遊/下遊資料庫讀取/寫入壓力過大,此處1mbps = 1MB/s。
}
},
"order": {
"hops": [
{
"from": "Reader",
"to": "Writer"
}
]
}
}Writer指令碼參數
指令碼參數名 | 描述 | 是否必選 | 預設值 |
datasource | 資料來源名稱,指令碼模式支援添加資料來源,此配置項填寫的內容必須與添加的資料來源名稱保持一致。 | 是 | 無 |
table | 選取的需要同步的表名稱。 | 是 | 無 |
writeMode | 選擇匯入模式,可以支援
| 否 | insert |
nullMode | NULL值處理策略,取值範圍:
重要 配置為skipNull時,任務會動態拼接寫資料的SQL語句以支援目標端預設值,會增加FLUSH次數,降低同步速度,最差情況下會每條資料FLUSH一次。 | 否 | writeNull |
skipNullColumn | nullMode配置為skipNull時,此參數配置的列不會被強制寫為 配置格式: | 否 | 預設為本任務配置的所有列。 |
column | 目標表需要寫入資料的欄位,欄位之間用英文所逗號分隔,例如 | 是 | 無 |
preSql | 執行資料同步任務之前率先執行的SQL語句。目前嚮導模式僅允許執行一條SQL語句,指令碼模式可以支援多條SQL語句。例如,執行前清空表中的舊資料(TRUNCATE TABLE tablename)。 說明 當有多條SQL語句時,不支援事務。 | 否 | 無 |
postSql | 執行資料同步任務之後執行的SQL語句,目前嚮導模式僅允許執行一條SQL語句,指令碼模式可以支援多條SQL語句。例如,加上某一個時間戳記 說明 當有多條SQL語句時,不支援事務。 | 否 | 無 |
batchSize | 一次性批量提交的記錄數大小,該值可以極大減少資料同步系統與MySQL的網路互動次數,並提升整體輸送量。如果該值設定過大,會導致資料同步運行進程OOM異常。 | 否 | 256 |
updateColumn | 當 | 否 | 無 |