當 DataWorks 的預設運行環境無法滿足任務(如 PyODPS、Shell)的特定依賴需求時,例如需要安裝額外的 Python 庫 (pandas,jieba),可以建立自訂鏡像。通過將所有依賴預先打包並固化,自訂鏡像提供一個可複用、標準化的任務執行環境,確保環境一致性並顯著提升開發與部署效率。
適用範圍
版本限制:
所有版本均可建立和使用自訂鏡像。
僅專業版及以上版本支援鏡像構建能力。
資源群組限制:鏡像功能僅支援Serverless資源群組。
舊版資源群組請使用營運助手安裝外部依賴。
許可權限制:擁有AliyunDataWorksFullAccess或ModifyResourceGroup權限原則。
授權詳情請參見產品及控制台許可權控制詳情:RAM Policy。
配額與限制
鏡像數量:不同DataWorks版本,支援建立的自訂鏡像數量上限不同。
基礎版和標準版:10個。
專業版:50個。
企業版:100個。
構建並發:每個地區最多支援 2 個鏡像同時進行構建。
ACR 鏡像要求:
執行個體版本:僅支援企業版的阿里雲ACR執行個體。
執行個體架構:僅支援AMD64架構。
鏡像大小:單個鏡像大小不能超過5GB。
時區配置:需要安裝時區相關的基礎包
tzdata,避免因與DataWorks設定的時區不一致導致容器異常退出。
鏡像構建:僅支援基於 DataWorks 官方鏡像建立的自訂鏡像。引用阿里雲 ACR 鏡像建立的自訂鏡像不支援持久化構建,每次運行任務時均需重新拉取和部署。
支援的節點類型與對應方式:
節點類型
直接基於官方鏡像構建
引用ACR鏡像構建
PyODPS2PyODPS3EMR SparkEMR Spark SQLEMR SHELLShellPythonNotebookCDH賦值節點
操作流程
一、建立自訂鏡像
DataWorks建立自訂鏡像時,支援以DataWorks官方鏡像或阿里雲ACR鏡像作為鏡像參考型別來建立鏡像,以下為選擇不同參考型別時的不同配置參數:
基於DataWorks官方鏡像直接建立
登入DataWorks控制台,單擊左側導覽列上的鏡像管理進入鏡像管理頁面。
在DataWorks官方鏡像頁簽下,選擇目標鏡像作為基礎,單擊操作欄的建立自訂鏡像。在彈窗中系統將自動填滿目標鏡像相關資訊,其他參數如下。
參考型別:預設選中DataWorks官方鏡像。鏡像命名空間:預設選中DataWorks Default。鏡像倉庫:預設選中DataWorks Default。
參數
說明
鏡像名稱/ID
預設選中目標官方鏡像,可按需切換。
可見範圍
支援配置自訂鏡像的可見範圍,包括僅建立者可見和全員可見。
使用子產品
當前自訂鏡像僅支援用於資料開發。
支援任務類型
根據不同鏡像類型,按需選擇需要支援的節點任務類型。在資料開發中運行匹配的節點任務時,可配置該鏡像為其啟動並執行鏡像。
安裝包
按需添加第三方包,可同時選擇多種模式並安裝多個包。支援以下方式:
快捷安裝:在安裝包下拉選擇框選擇
Python2、Python3、Yum,可以直接選擇需要安裝的環境、資源。若下拉式清單中沒有需要的第三方包,切換至Script模式手動安裝。
手動輸入:在安裝包下拉選擇框選擇
Script。可通過Script命令框手動輸入安裝命令。您可選擇以下手動輸入樣本命令下載第三方包。pip樣本命令:
pip install xx,支援Python2使用。pip3樣本命令:
/home/tops/bin/pip3 install 'urllib3<2.0',支援Python3使用。yum樣本命令:
yum install -y git。wget樣本命令:
wget git。更多安裝命令說明,請參見附錄:安裝命令參考。
重要若需安裝或依賴位於公網的第三方包,則Serverless資源群組綁定的VPC需具備公網訪問能力。
單擊確定,完成鏡像建立。
基於阿里雲ACR鏡像建立
基於ACR鏡像建立自訂鏡像,需開通Container Registry。僅支援通過企業版、AMD64架構的阿里雲ACR鏡像執行個體來建立DataWorks鏡像。
登入DataWorks控制台,單擊左側導覽列上的鏡像管理進入鏡像管理頁面。
在自訂鏡像頁簽下,單擊建立鏡像。在彈窗中配置關鍵參數:
參數
說明
參考型別
選擇阿里雲ACR鏡像
鏡像執行個體ID
選擇在阿里雲Container Registry中建立的企業版執行個體。
鏡像命名空間
選擇該鏡像執行個體下的命名空間。
鏡像倉庫
選擇該鏡像執行個體下的鏡像倉庫。
鏡像版本
支援根據所選中的鏡像倉庫,選擇鏡像倉庫下您需要建立自訂鏡像的鏡像版本。
關聯的VPC
選擇鏡像執行個體綁定的VPC網路,配置VPC網路詳情請參見:配置專用網路的存取控制。
重要DataWorks僅支援選擇一個VPC訪問阿里雲ACR鏡像執行個體。
同步至MaxCompute
預設為否。選項與您選擇的鏡像執行個體有關,執行個體規格為標準版及以上版本的ACR鏡像執行個體是可選擇的,其他預設不可選。
選擇是:預設產生DataWorks自訂鏡像,DataWorks鏡像發布時同步構建為MaxCompute鏡像。
詳情請參見個人開發環境製作MaxCompute鏡像。
選擇否:僅產生DataWorks自訂鏡像,不會同步構建為MaxCompute鏡像。
可見範圍
支援配置自訂鏡像的可見範圍,包括僅建立者可見和全員可見。
使用子產品
當前自訂鏡像僅支援用於資料開發。
支援任務類型
ACR鏡像啟動方式為
啟動命令+使用者任務代碼檔案路徑的方式啟動,以下為不同任務類型和預設啟動命令:ShellPython:若需將阿里雲ACR鏡像建立的自訂鏡像應用於Python任務,需確認您的ACR鏡像執行個體內是否包含Python環境,否則無法支援Python任務。Notebook若需將阿里雲ACR鏡像建立的自訂鏡像應用於Notebook任務,請將DataWorks提供的Notebook基礎鏡像作為您ACR鏡像的基礎鏡像,為Notebook任務提供運行環境。DataWorks提供的Notebook基礎鏡像:
dataworks-public-registry.cn-shanghai.cr.aliyuncs.com/public/dataworks-notebook:py3.11-ubuntu22.04-20241202。請確保您構建鏡像使用的環境已具備公網訪問能力,以便正常擷取DataWorks提供的Notebook基礎鏡像。
單擊確定,完成鏡像建立。
基於個人開發環境執行個體建立
Data Studio新版資料開發支援將個人開發環境製作成新的鏡像,詳情可參見:個人開發環境製作DataWorks鏡像。
二、測試與發布自訂鏡像
在DataWorks控制台的頁簽下,對目標鏡像進行發布。只有測試成功的鏡像才發行就緒。如果測試失敗,可在目標自訂鏡像的操作列單擊![]() > 修改,修改鏡像配置。
> 修改,修改鏡像配置。
測試與發布時,需注意以下內容:
測試自訂鏡像時,資源群組請選擇Serverless資源群組。
如果您基於阿里雲ACR鏡像建立或基於個人開發環境製作鏡像,則需確保測試與發布時選擇的Serverless資源群組綁定的VPC需與阿里雲鏡像容器內綁定的VPC一致。
如果您配置的自訂鏡像是從公網擷取第三方包,且長時間測試不通過,請檢查測試資源群組綁定的VPC是否具備公網訪問能力。
三、綁定鏡像歸屬空間
發布後的鏡像,可通過修改鏡像歸屬空間在不同工作空間中應用。
在DataWorks控制台的頁簽下,查看並找到發行的自訂鏡像。
在目標鏡像操作列單擊
 > 修改歸屬工作空間,為自訂鏡像綁定歸屬工作空間。
> 修改歸屬工作空間,為自訂鏡像綁定歸屬工作空間。
四、在任務中使用鏡像
新版資料開發使用鏡像
進入資料開發:進入DataWorks工作空間列表頁,在頂部切換至目標地區,找到目標工作空間,單擊操作列的,進入Data Studio。
配置鏡像:在資料開發功能中找到待測試自訂鏡像的任務節點,單擊右側調度配置,配置資源屬性。
資源群組:選擇Serverless資源群組。
如果此處未顯示目標資源群組,請檢查是否將該資源群組綁定至當前工作空間。您可以前往資源群組列表頁,找到目標資源群組,然後單擊操作列的綁定工作空間,完成綁定。
重要為確保任務節點順利運行,請確保資源群組與發布鏡像時選擇的測試資源群組一致。
鏡像:選擇發行的自訂鏡像。
若切換鏡像,需將節點發布後,才能在生產環境中生效。
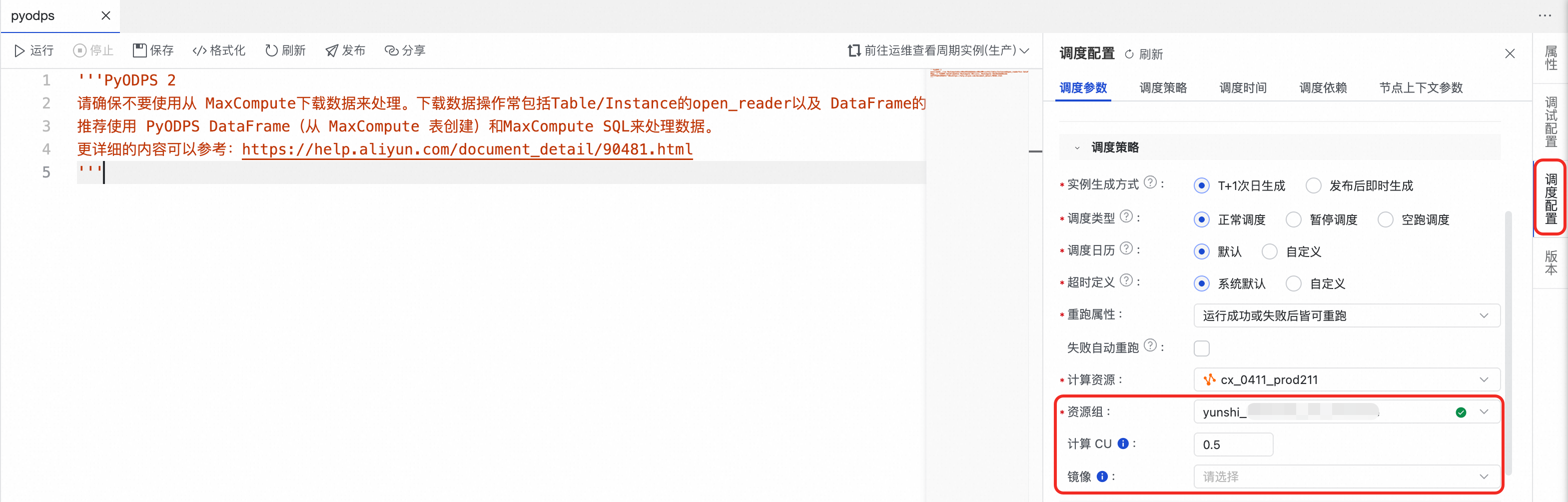
調試節點:在節點右側回合組態中,配置計算資源、資源群組、計算CU、鏡像和指令碼參數,然後在節點頂部工具列單擊運行。
發布節點:在節點頂部工具列單擊發布,將節點發布至生產環境。
舊版資料開發使用鏡像
進入資料開發:登入DataWorks控制台,切換至目標地區後,單擊左側導覽列的,在下拉框中選擇對應工作空間後單擊進入資料開發。
配置鏡像:在資料開發功能中找到待測試自訂鏡像的任務節點,單擊右側調度配置,配置資源屬性。
調度資源群組:選擇Serverless資源群組。
如果此處未顯示目標資源群組,請檢查是否將該資源群組綁定至當前工作空間。您可以前往資源群組列表頁,找到目標資源群組,然後單擊操作列的綁定工作空間,完成綁定。
重要為確保任務節點順利運行,請確保調度資源群組與發布鏡像時選擇的測試資源群組一致。
鏡像:選擇發行的自訂鏡像。
若切換鏡像,需將節點發布後,才能在生產環境中生效。
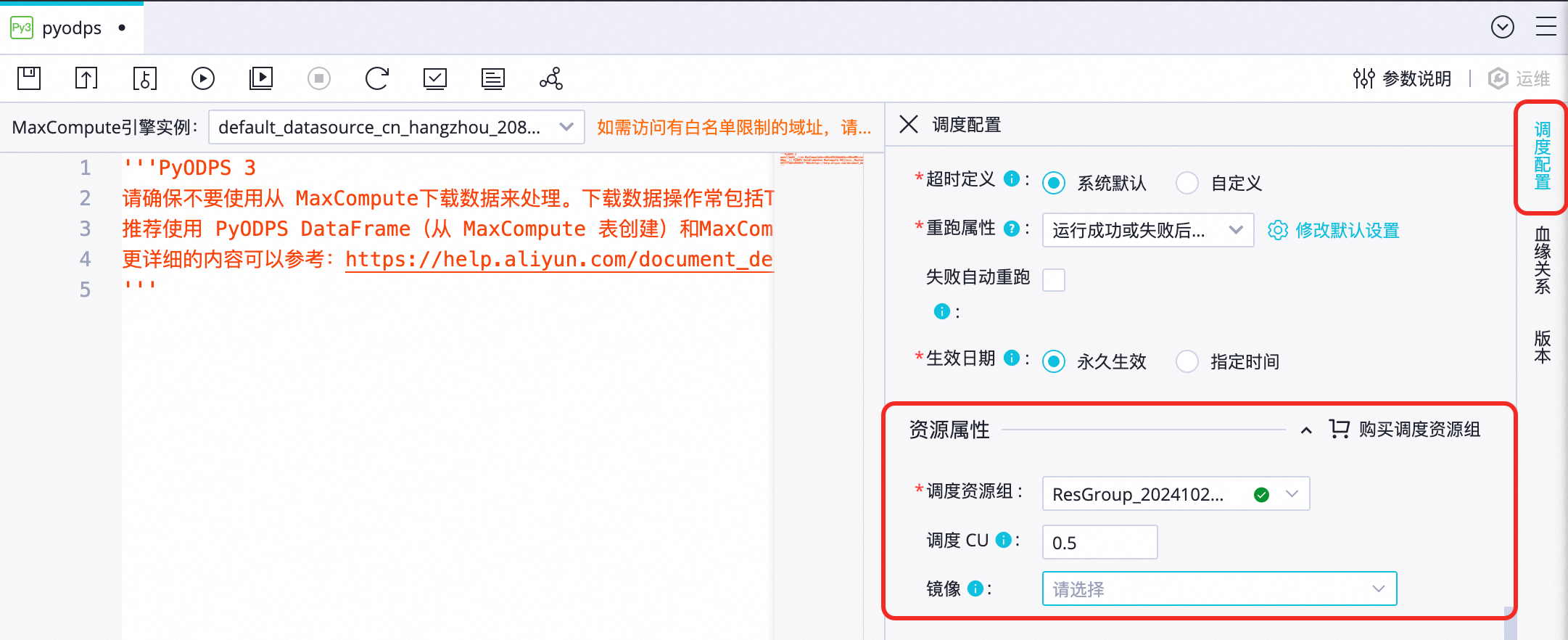
調試節點:在節點頂部工具列單擊帶參運行(
 ),配置資源群組名稱、運行CU、鏡像,然後單擊運行。
),配置資源群組名稱、運行CU、鏡像,然後單擊運行。發布節點:在節點頂部工具列單擊儲存並提交,將節點發布至生產環境。
五、構建持久化鏡像
強烈建議在鏡像發布並通過業務驗證後進行鏡像持久化。該做法可有效規避因鏡像源依賴庫被篡改或版本未明確指定,導致任務初始化時下載到非預期版本而引發運行失敗的風險。
常規自訂鏡像每次運行都會重新部署,會增加節點已耗用時間且可能承擔更多的計算費用。DataWorks 的持久化鏡像功能只需構建一次即可無限次複用,能夠提升任務運行效率、降低計算與流量成本,同時確保環境的高度一致性。構建持久化鏡像只支援通過官方鏡像建立的自訂鏡像。
在DataWorks控制台的頁簽下,查看並找到發行的自訂鏡像。
在目標鏡像操作列單擊
> 構建,將自訂鏡像構建為持久化鏡像。在彈出的請選擇構建鏡像的資源群組對話方塊中,配置構建鏡像使用的資源群組,然後單擊繼續。
重要為避免因網路等原因出現構建失敗的情況,請確保構建鏡像的資源群組與發布自訂鏡像時選擇的測試資源群組一致。
構建鏡像大約耗時5~10分鐘,具體視鏡像大小而定。成功構建之後,目標鏡像的發布狀態變成發行(構建成功)。
計費說明
構建鏡像會按照CU數量 × 構建時間長度收取計算費用,系統預設分配0.5CU。計費詳情,請參見Serverless資源群組計費標準。
應用於生產
為確保在生產環境中穩定、高效、經濟地使用自訂鏡像,請參考以下建議。
持久化鏡像:建議對發行且配置穩定的鏡像進行鏡像構建,形成持久化鏡像。這樣可避免任務每次運行時都重新安裝依賴,從而縮短啟動時間、降低計算成本並提高穩定性。
環境一致性:確保用於測試、構建和生產調度的Serverless 資源群組所綁定的VPC和網路設定一致,尤其是在訪問私人 ACR 倉庫或公網時。
版本鎖定:在通過
Script方式安裝依賴時,強烈建議明確指定版本號碼(如pip install pandas==1.5.3),避免上遊庫更新導致非預期的行為變更。復原方案:如果更新鏡像後生產任務失敗,可通過任務發布歷史復原到上一個版本,或在調度配置中將鏡像重新指向舊的、穩定的版本。
情境實踐案例
本實踐示範如何通過PyODPS節點使用鏡像實現中文分詞能力。假設需要對MaxCompute表中的某一列中文資料進行分詞,然後將分詞結果存入另一張表中,用於下遊調度節點使用。您可在自訂鏡像中預裝jieba分詞工具包,然後通過PyODPS任務使用該鏡像對資料表中的中文資料進行分詞處理,並將結果儲存至新表,無縫整合至下遊調度流程。
建立測試資料。
建立自訂鏡像。
參見建立自訂鏡像,關鍵參數如下:
鏡像名稱/ID:選擇
dataworks_pyodps_task_pod,DataWorks PyODPS節點官方鏡像。支援任務類型:支援
PyODPS2、PyODPS 3。安裝包:選擇
Python3和jieba。
在調度任務中使用自訂鏡像。
在資料開發中,建立PyODPS3節點,配置如下內容:
在右側調度配置中,設定如下關鍵參數:
調度參數:參數名
bday,參數值為$[yyyymmdd]。調度資源群組:選擇Serverless資源群組,與發布鏡像時選擇的測試資源群組相同。
鏡像:選擇發行並綁定了當前工作空間的自訂鏡像。
節點調試。
如果使用舊版資料開發,請在節點頂部工具列單擊帶參運行(
),配置資源群組名稱、運行CU、鏡像和自訂參數,然後單擊運行。如果使用新版資料開發,請在節點右側回合組態中,配置計算資源、資源群組、計算CU、鏡像和指令碼參數,然後在節點頂部工具列單擊運行。
(可選)建立臨時查詢(舊版資料開發)或在個人目錄下建立SQL檔案(新版資料開發),使用如下SQL查詢產出表中是否有資料。
-- 將<分區日期>替換成具體日期。 SELECT * FROM participle_tb WHERE ds=<分區日期>;
將PyODPS節點發布至生產環境。
說明資料開發中修改的鏡像不會同步到生產環境中,您需要將任務發布後,才能在生產環境中生效。詳情請參見發布任務(舊版資料開發)或節點/工作流程發布(新版資料開發)。
將自訂鏡像構建為持久化鏡像。具體請參見構建持久化鏡像。
常見問題
Q:Python任務報錯urllib3 v2.0 only supports OpenSSL 1.1.1+。
A:urllib3 v2.0僅支援OpenSSL1.1.1+,可降低urllib3版本以相容OpenSSL。例如,安裝三方包的時候強行指定urllib3的版本:/home/tops/bin/pip3 install urllib3==1.26.16。
相關文檔
附錄:安裝命令參考
如果使用自訂鏡像的Script方式配置安裝命令,則可以參考如下命令安裝:
如果依賴PyODPS 2節點,請執行如下命令。
pip install <需要安裝的包> -i https://pypi.tuna.tsinghua.edu.cn/simplepip install <需要安裝的包>說明執行命令後,如果提示需要升級PIP版本,請執行命令
pip install --upgrade pip。如果依賴PyODPS 3節點,請執行如下命令。
/home/tops/bin/pip3 install <需要安裝的包> -i https://pypi.tuna.tsinghua.edu.cn/simple/home/tops/bin/pip3 install <需要安裝的包>說明執行命令後,如果提示需要升級PIP版本,請執行命令
/home/tops/bin/pip3 install --upgrade pip。如果出現報錯
/home/admin/usertools/tools/cmd-0.sh:行3: /home/tops/bin/python3: 沒有那個檔案或目錄,請提交工單申請開啟許可權。
Python公開鏡像源參考如下,可按需切換。
機構/公司
鏡像地址
阿里雲 (Aliyun)
https://mirrors.aliyun.com/pypi/simple/重要從阿里雲擷取Python包,無需開通公網訪問能力。
清華大學 (Tsinghua)
https://pypi.tuna.tsinghua.edu.cn/simple中國科學技術大學 (USTC)
https://pypi.mirrors.ustc.edu.cn/simple/