Data Studio是阿里巴巴基於十幾年巨量資料經驗打造的智能湖倉一體資料開發平台,支援阿里雲多種計算服務,提供智能化ETL、資料目錄管理及跨引擎工作流程編排的產品能力。通過個人開發環境執行個體支援Python開發、Notebook分析與Git整合,Data Studio還支援豐富多樣的外掛程式生態,實現即時離線一體化、湖倉一體化、巨量資料AI一體化,助力“Data+AI”全生命週期的資料管理。
Data Studio 介紹
Data Studio是智能湖倉一體資料開發平台,內建阿里巴巴巨量資料建設方法論,深度適配阿里雲MaxCompute、E-MapReduce、Hologres、Flink、PAI等數十種巨量資料和AI計算服務,為資料倉儲、資料湖、OpenLake湖倉一體資料架構提供智能化ETL開發服務,它支援:
湖倉一體與多引擎支援
通過統一的資料目錄和豐富的引擎節點,實現對湖(例如,OSS)倉(例如,MaxCompute)資料的無差別訪問與多引擎混合開發。靈活的工作流程與調度
提供豐富的流程式控制制節點,支援在工作流程中對跨引擎任務進行可視化編排,並提供時間驅動的周期調度和事件驅動的觸發式調度。開放的Data+AI開發環境
提供可自訂依賴的個人開發環境、支援SQL與Python混編的Notebook,並通過資料集、Git整合等功能,構建開放、靈活的AI研發工作站。智能輔助與AI工程化
內建強大的Copilot智能助手賦能代碼開發全過程,並通過專業的PAI演算法節點和大模型節點,為端到端的AI工程化提供原生支援。
Data Studio 基本概念
概念 | 專業術語 | 核心價值 | 關鍵詞 |
工作流程 | 任務的組織與編排單元 | 實現複雜任務的依賴管理與自動化調度,是開發和調度的“容器”。 | 可視化、DAG、周期/觸發、編排 |
節點 | 工作流程中的最小執行單元 | 編寫代碼、實現具體商務邏輯的地方,是資料處理的原子操作。 | SQL、Python、Shell、Data Integration |
自訂鏡像 | 環境的標準化快照 | 保證環境的可拓展性、一致性與可複現性。 | 環境固化、標準化、可複製、一致性 |
調度 | 任務自動觸發的規則 | 實現資料生產的自動化,將手動任務轉化為可自動啟動並執行生產力。 | 周期調度、觸發式調度、依賴、自動化 |
資料目錄 | 統一的中繼資料工作台 | 結構化組織和管理資料資產(如表)及計算資源(如函數、資源)。 | 中繼資料、表管理、資料探查 |
資料集 | 外部儲存的邏輯映射 | 打通與外部非結構化資料(圖片/文檔)的串連,是 AI 開發的關鍵資料橋樑。 | OSS/NAS 接入、資料掛載、非結構化 |
Notebook | 互動 Data+AI 開發畫布 | 實現 SQL 與 Python 代碼的融合,加速資料探索與演算法驗證。 | 互動式、多語言、可視化、探索分析 |
Data Studio 流程指引
Data Studio提供面向數倉開發和AI開發的流程,以下展示常見兩種路徑。更多重路徑請按實際情況探索。
通用路徑:數倉開發流程(周期性ETL任務)
此流程適用於構建企業級資料倉儲,實現穩定、自動化的批量資料處理。
面向人群:資料工程師、ETL 開發人員。
核心目標:構建穩定、規範、可自動調度的企業級資料倉儲,進行批量資料處理和報表產生。
關鍵技術:資料目錄、周期工作流程、SQL 節點、調度配置。

步驟 | 階段名稱 | 核心操作與目的 | 關鍵路徑和參考文檔 |
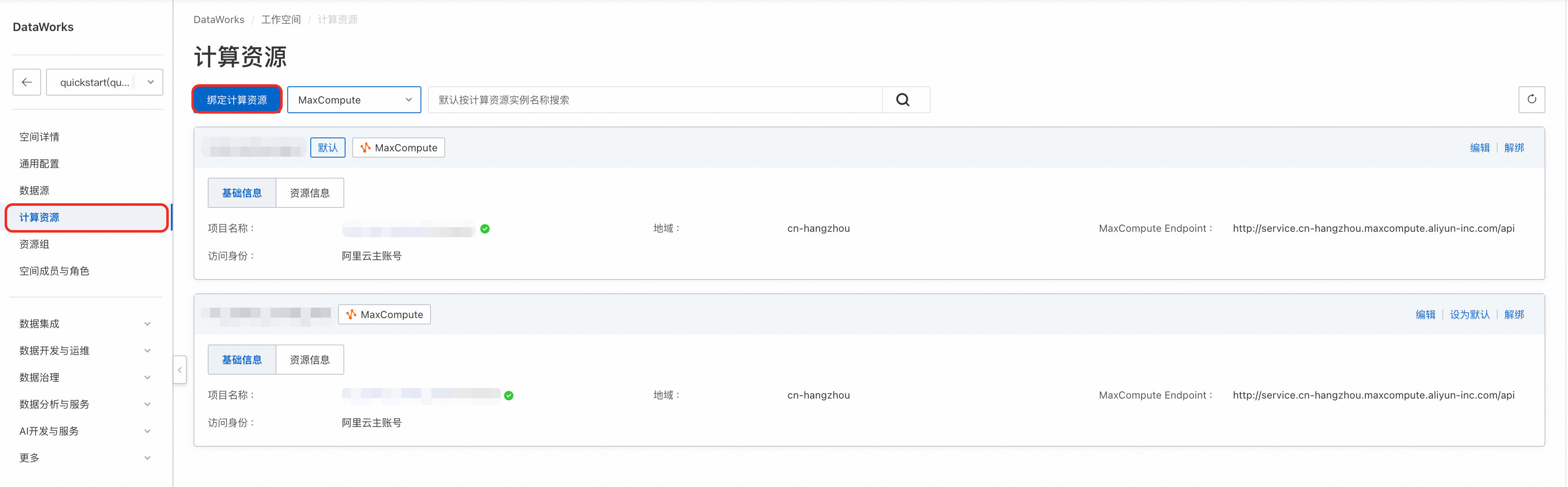
1 | 綁定計算引擎 | 為工作空間關聯一個或多個核心的計算引擎(如MaxCompute),作為所有SQL任務的執行環境。
| 控制台 > 工作空間配置 相關文檔,請參見綁定計算資源。 |
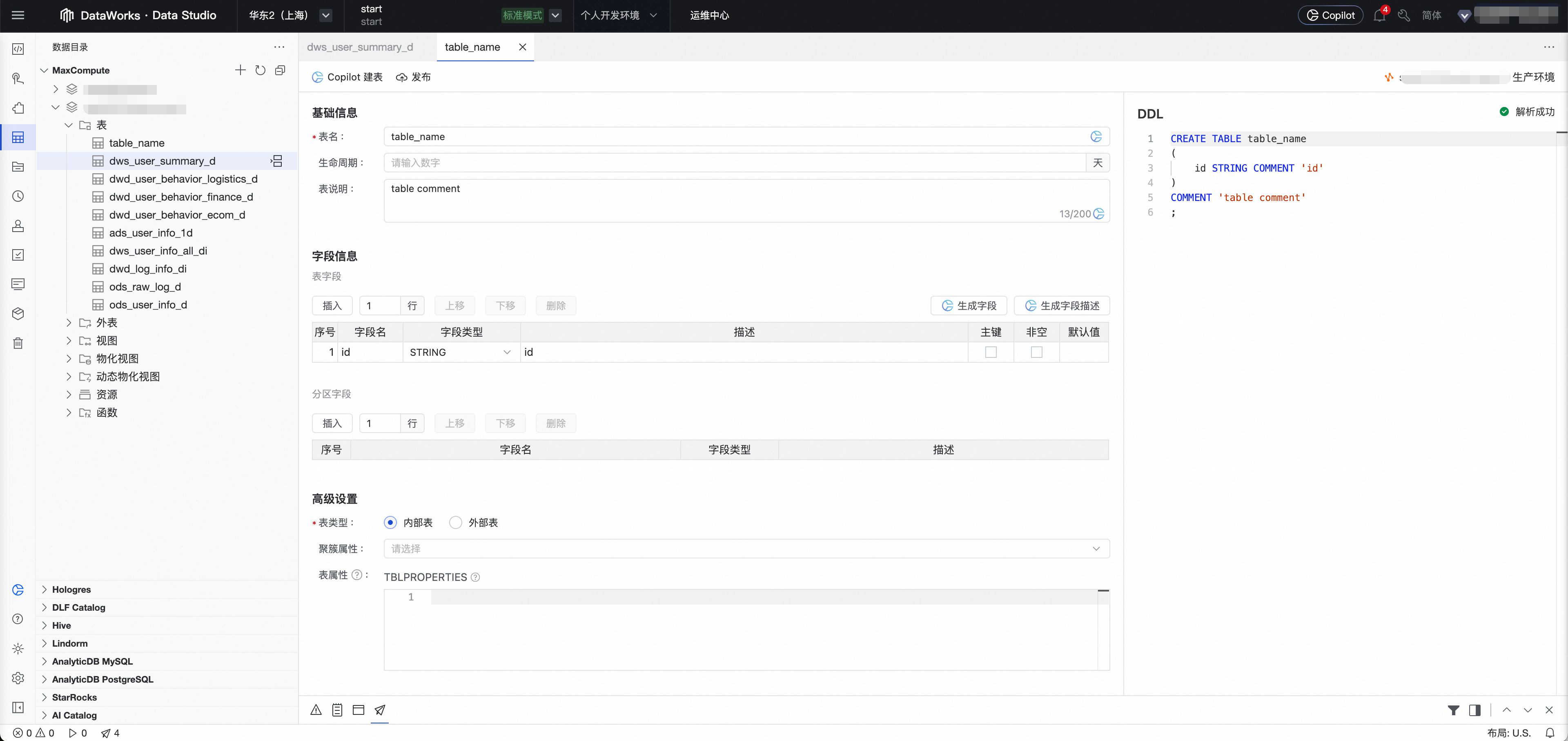
2 | 資料目錄管理 | 在資料目錄中建立或探查數倉各層所需的表結構(ODS, DWD, ADS等),為資料處理定義好輸入和輸出。 推薦使用資料建模模組構建數倉體系。
| Data Studio > 資料目錄 相關文檔,請參見資料目錄。 |
3 | 建立周期工作流程 | 在專案目錄中建立一個周期工作流程,作為組織和管理相關ETL任務的容器。 | Data Studio > 專案目錄 > 周期工作流程 相關文檔,請參見周期工作流程。 |
4 | 節點開發和調試 | 建立ODPS SQL等節點,在編輯器中編寫核心的ETL(資料清洗、轉換、彙總)邏輯,並進行節點調試。 |
相關文檔,請參見節點開發。 |
5 | Copilot輔助開發 | 通過DataWorks Copilot能力,實現SQL、Python的代碼產生、代碼錯誤修正、代碼改寫、代碼轉換。 |
|
6 | 節點編排和調度 | 在工作流程的DAG畫布中,通過拖拽和連線的方式,定義各節點之間的上下遊依賴關係。支援各種流程式控制制節點,可實現複雜的流程編排。 為工作流程或節點配置生產環境的調度屬性,如周期、時間和依賴。支援日均千萬級超大規模調度。 |
相關文檔,請參見通用流程式控制制節點、節點調度配置。 |
7 | 工作流程/節點發布與營運 |
|
|
相關入門案例可參見:進階:商品訂單暢銷類目分析。
進階路徑:巨量資料AI開發流程
此流程適用於AI模型開發、資料科學探索和構建即時響應的AI應用,強調環境的靈活性與互動性。具體流程可因實際而定。
面向人群:AI 工程師、資料科學家、演算法工程師。
核心目標:進行資料探索、模型訓練、演算法驗證,或構建即時響應的 AI 應用(如 RAG、即時推理服務)。
關鍵技術:個人開發環境、Notebook、觸發式工作流程、資料集、自訂鏡像。

步驟 | 階段名稱 | 核心操作與目的 | 關鍵路徑和參考文檔 |
1 | 建立個人開發環境 | 建立一個隔離的、可自訂的雲端容器執行個體,作為安裝複雜Python依賴和進行專業AI開發的環境。 | Data Studio > 個人開發環境 相關文檔,請參見個人開發環境。 |
2 | 建立觸發式工作流程 | 在專案目錄中建立一個由外來事件驅動的工作流程,為即時AI應用提供編排容器。 | Data Studio > 專案目錄 > 觸發式工作流程 相關文檔,請參見觸發式工作流程。 |
3 | 建立和設定觸發器 | 在營運中心配置一個觸發器,定義何種外來事件(如OSS事件、Kafka訊息事件)會啟動工作流程。 |
相關文檔,請參見管理觸發器、設計觸發式工作流程。 |
4 | 建立Notebook節點 | 建立用於編寫AI/Python代碼的核心開發單元。通常先在個人目錄的Notebook中進行探索。 | 專案目錄 > 觸發式工作流程 > Notebook節點 相關文檔,請參見建立節點。 |
5 | 建立和使用資料集 | 將儲存在OSS/NAS上的非結構化資料(圖片、文檔等)註冊為資料集,並掛載到開發環境或任務中,供代碼訪問。 |
相關文檔,請參見管理資料集、使用資料集。 |
6 | 開發&調試Notebook/節點 | 在個人開發環境提供的互動式環境中編寫演算法邏輯,進行資料探索、模型驗證和快速迭代。 | Data Studio > Notebook編輯器 相關文檔,請參見Notebook 基礎開發。 |
7 | 安裝自訂依賴包 | 在個人開發環境的終端或Notebook的儲存格中,使用 | Data Studio > 個人開發環境 > 終端 相關文檔,請參見附錄:完善個人開發環境。 |
8 | 製作自訂鏡像 | 將配置好所有依賴的個人開發環境固化成一個標準化的鏡像,以保證生產環境與開發環境完全一致。 若沒有安裝自訂依賴包,則跳過此步驟。 |
相關文檔,請參見個人開發環境製作DataWorks鏡像。 |
9 | 節點調度配置 | 在生產節點的調度配置中,必須指定使用上一步製作的自訂鏡像作為運行環境,並掛載所需的資料集。 | Data Studio > Notebook節點 > 調度配置 相關文檔,請參見節點調度配置。 |
10 | 節點/工作流程發布與營運 |
|
Data Studio 核心模組

核心模組 | 主要能力 |
工作流程編排 | 提供可視化的 DAG 畫布,支援通過拖拽方式輕鬆構建和管理複雜的任務工程。支援周期工作流程、觸發式工作流程、手動商務程序,滿足不同情境的自動化需求。 |
執行環境與模式 | 提供靈活、開放的開發環境,提升開發效率與協同能力。 |
節點開發 | 支援豐富的節點類型和計算引擎,實現靈活的資料處理與分析。
更多詳情,請參見計算資源管理和節點開發。 |
節點調度 | 提供強大、靈活的自動化調度能力,確保任務按時、有序執行。
|
開發資源管理 | 實現對資料開發過程中涉及的各類資產的統一管理。 |
品質管控 | 內建多重管控機制,保障資料生產流程的規範性和產出資料的準確性。
|
開放與拓展 | 提供豐富的開放介面和擴充點,方便與外部系統整合和二次開發。
|
Data Studio 產品計費
DataWorks側收費(費用在DataWorks相關賬單中)
資源群組費用:節點開發和個人開發環境使用依賴資源群組進行。根據資源群組不同,將產生Serverless資源群組費用或獨享調度資源群組費用。
若使用大模型服務,也將產生Serverless資源群組費用。
任務調度費用:若任務發布至生產環境調度運行,將產生任務調度費用(使用Serverless資源群組時)或獨享調度資源群組費用(使用獨享資源群組時)。
資料品質費用:若為週期性任務配置品質監控並成功觸發執行個體,將產生資料品質執行個體費用。
智能基準費用:若為週期性任務配置智能基準,開啟狀態的智能基準將產生智能基準執行個體費用。
警示簡訊和電話費用:若為週期性任務配置監控警示並成功觸發簡訊和電話,將產生警示簡訊和電話費用。
說明費用涉及模組:資料開發、資料品質、營運中心模組。
非DataWorks側收費(費用不在DataWorks相關賬單中)
運行資料開發節點任務時,可能產生的計算引擎計儲存費用(例如,OSS儲存費)不在DataWorks收取。
Data Studio 快速開始
建立或啟用新版資料開發
建立工作空間時,選擇使用新版資料開發(Data Studio)。具體操作請參見建立工作空間。
舊版資料開發(DataStudio)支援通過單擊資料開發頁面頂部的升級新版按鈕,按介面提示,將資料移轉至新版資料開發(Data Studio)。詳情請參見Data Studio 升級指南。

進入新版資料開發
進入DataWorks工作空間列表頁,在頂部切換至目標地區,找到目標工作空間,單擊操作列的,進入Data Studio。
常見問題與答疑
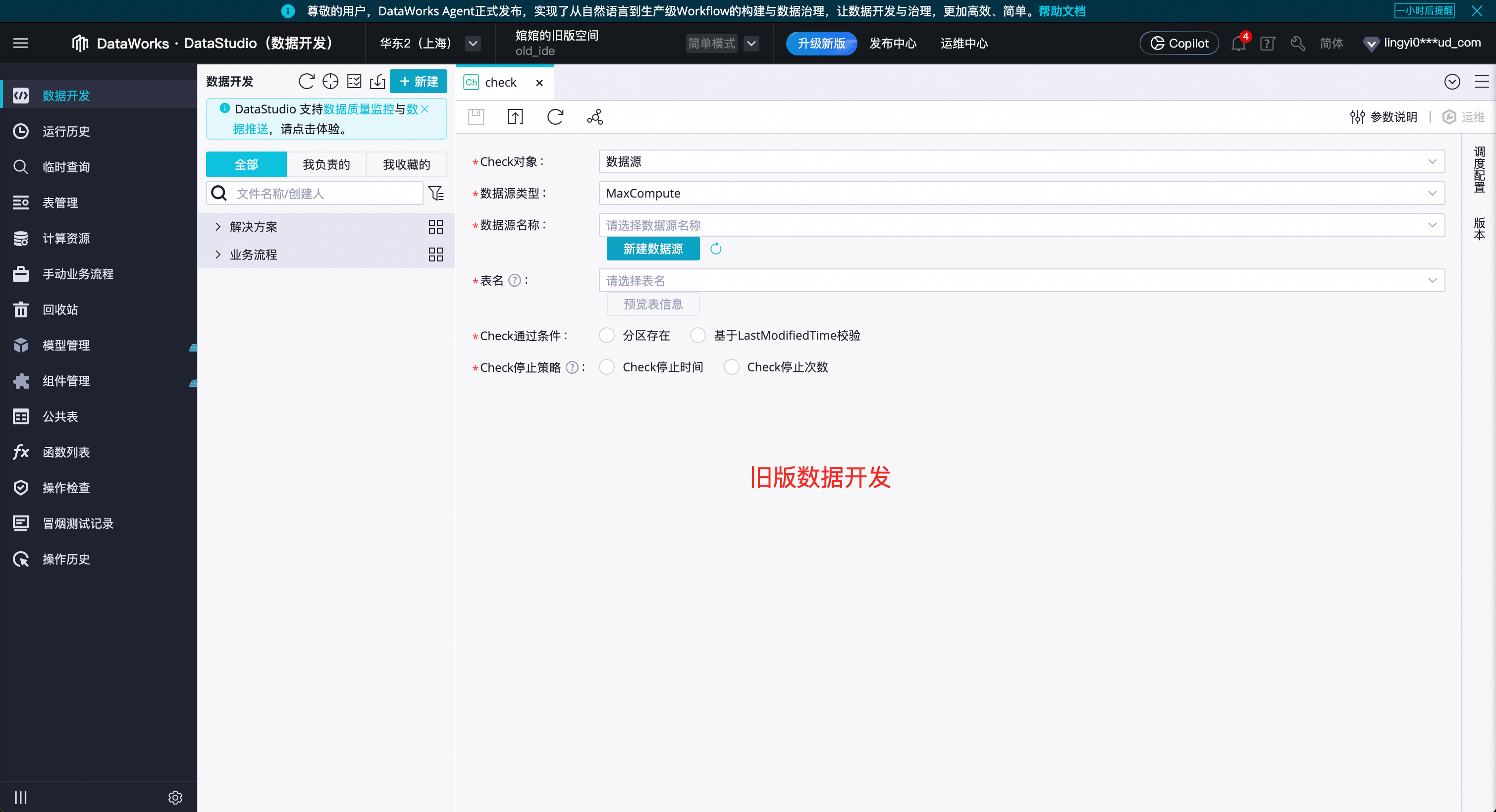
Q:如何區分新版資料開發還是舊版資料開發?
A:兩者頁面風格完全不同,新版為本文截圖樣式,舊版如下圖。
Q:升級成新版資料開發之後,能退回舊版資料開發嗎?
A:舊版資料開發升級新版為無法復原操作,成功升級後將無法回退至舊版。切換前建議先建立開啟新版資料開發的工作空間進行測試,確保新版資料開發滿足業務需求後再升級。另外,新版資料開發與舊版資料開發中的資料相互獨立。
Q:為什麼我建立工作空間時,沒看到使用新版資料開發(Data Studio)配置項?
A:若您在介面上未看到此選項,代表您的工作空間已預設啟用新版資料開發。
重要如您在使用新版資料開發過程中遇到問題,可添加DataWorks資料開發升級到新版專屬答疑群進行諮詢。