本次測試採用3種不同的測試情境,針對開源自建的Hadoop+Spark叢集與阿里雲雲原生資料湖分析DLA Spark在執行Terasort基準測試的效能做了對比分析。本文檔主要展示了開源自建Spark和DLA Spark在3種測試情境下的測試結果及效能對比分析。
1 TB測試資料下DLA Spark+OSS與自建Hadoop+Spark叢集效能對比結果
| 叢集類型 | 運行Terasort基準測試集耗時(h) |
| DLA Spark+OSS | 0.701 |
| 自建Hadoop+Spark | 0.733 |
通過上述耗時對比結果可以看出,作業效能上DLA Spark跟自建Spark基本持平。
需要強調的是,DLA Spark完全按需使用儲存和計算資源,對OSS訪問實現了深度定製最佳化,效能相比於最佳化前提升1倍左右,與Spark訪問HDFS效能持平。
10 TB測試資料下DLA Spark+OSS與自建Hadoop+Spark效能對比結果
| 叢集類型 | 運行Terasort基準測試集耗時(h) |
| DLA Spark+OSS | 5.2 |
| 自建Hadoop+Spark | 13.9 |
在分析效能時發現,在10 TB情境下,本地碟的儲存和shuffle之間會有IO頻寬上的明顯爭搶,而Serverless Spark計算節點內建essd雲端硬碟,與shuffle盤完全獨立,能較高的提升效能。
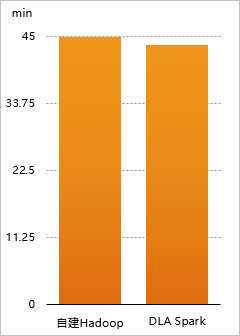
1 TB測試資料下DLA Spark+使用者自建Hadoop叢集與自建Hadoop+Spark效能對比結果
| 叢集類型 | 運行Terasort基準測試集耗時(min) |
| DLA Spark+OSS | 43.5 |
| 自建Hadoop+Spark | 44.8 |
您可以將自建Hadoop和DLA Spark混合使用,自建Hadoop叢集在高峰期需要更多的計算資源。DLA Spark可以直接跟您的VPC網路打通,直接使用內網的頻寬,計算效能相對於本地計算並沒有降低。DLA Spark完全彈性的模式,1分鐘內可以拉起500~1000個計算節點,可以很好滿足您對彈性計算的需求。