本文介紹資料庫自治服務DAS(Database Autonomy Service)的Cost-based SQL診斷引擎。
背景資訊
- 應用程式層面最佳化:應用代碼邏輯最佳化,以更高效的方式處理資料。
- 執行個體層面最佳化:通過環境參數調整,最佳化執行個體的運行效率。
- SQL層面最佳化:通過物理資料庫設計、SQL語句改寫等最佳化手段,確保以最佳的方式擷取資料。
開發人員通常對於前面兩個層面的最佳化比較熟悉,對於第三個即SQL層面的最佳化會有些生疏,甚至會因由誰(資料庫管理員或應用開發人員)來負責而產生爭論,但SQL最佳化是整個資料庫最佳化中非常關鍵的一環,線上SQL效能問題不僅會給業務帶來執行效率上的低下,甚至是穩定性上的故障。
按照經驗,約80%的資料庫效能問題能通過SQL最佳化手段解決,但SQL最佳化一直以來都是一個非常複雜的過程,需要多方面的資料庫領域專家知識和經驗。
例如如何準確地識別執行計畫中的瓶頸點,通過最佳化物理庫設計或SQL改寫等手段,讓資料庫最佳化器執行最佳計劃。另外,由於SQL工作負載及其基礎資料龐大且不斷變化,SQL最佳化還是一項非常耗時且繁重的任務,這些都決定了SQL最佳化是一項高門檻、高投入的工作。
面臨挑戰
- 能力是否靠譜?
- 能力是否全面?
- 如何選擇靠譜的最佳化推薦演算法產生靠譜的建議?在SQL診斷最佳化領域,基於規則和基於代價模型是兩種常被選擇的最佳化推薦演算法。
- 基於規則在目前許多產品和服務中,基於規則的推薦方式被廣泛使用,特別是針對MySQL這種WHAT-IF核心能力缺失的資料庫,因為該方式相對來說比較簡單,容易實現,但另一面也造成了推薦過於機械化,推薦品質難以保證的問題,例如對如下簡單SQL進行索引推薦:
基於規則,通常會首先產生如下四個候選索引:SELECT * FROM t1 WHERE time_created >= '2017-11-25' AND consuming_time > 1000 ORDER BY consuming_time DESC;IX1(time_created) IX2(time_created, consuming_time) IX3(consuming_time) IX4(consuming_time, time_created)但最終推薦給使用者的是哪個(或哪幾個,考慮index oring/anding的情況)索引呢?基於規則的方式很難給出精確的回答,會出現模稜兩可的局面。在這個例子中,SQL只是簡單的單表查詢,那對於再複雜一點的SQL,例如多個表Join,以及帶有複雜的子查詢,情況又會如何呢?情況變得更糟糕,更加難以為繼。
- 基於代價模型與基於規則不同,DAS中的SQL診斷最佳化服務採用的是基於代價模型方式實現,即採用和資料庫最佳化器相同的方式去思考最佳化問題,最終會以執行代價的方式量化評估所有的(或儘可能所有的,因為是最優解求解的NP類問題,因此在一些極端情況下無法做到所有,只是實現次優)可能推薦候選項,最終作出推薦。即便是如此,但對於MySQL這樣的開來源資料庫支援,還將面臨其它不一樣的挑戰:
- WHAT-IF核心能力缺失:無法複用核心的資料庫最佳化器能力來對候選最佳化方案進行代價量化評估。
- 統計資訊缺失:候選最佳化方案的代價評估,其本質是執行計畫的代價計算,統計資訊的缺失便是無米之炊。
- 基於規則
- 如何具備足夠的SQL相容性?
SQL診斷最佳化服務如何做到SQL相容性,其中包括SQL的解析以及SQL語義的驗證,這直接關係到能力的全面性和診斷的成功率,它就像入場券,做不到做不全面都是問題。
- 如何構建具有足夠覆蓋度的能力測試集?
長期以來,SQL診斷最佳化能力的構建一直都是頗具挑戰性的課題,挑戰不僅在於如何融入資料庫最佳化領域專家知識,還包括如何構建一個龐大的測試案例庫用於其核心能力驗證,它就像一把尺子可以衡量能力,同時又可以以此為驅動,加速能力的構建,因此在整個過程中,擁有足夠覆蓋度,準確的測試案例庫是能力構建過程中至關重要的一環。
但構建足夠好的測試案例庫是一件非常困難的事情,挑戰主要體現在兩個方面:- 足夠完備性保證:影響SQL最佳化的因素很多,例如影響索引選擇的因素有上百個,加之各因素之間形成組合,這就形成了龐大的案例特徵集合,如何讓這些特徵一一映射到測試案例也是非常龐大的工程。
- 測試案例設計需要專業知識且資訊量大,例如對於單一測試案例設計也需要專業知識且測試案例中攜帶的資訊量大,如索引推薦測試案例,它包括:
- schema設計:如表、已有索引、約束等。
- 各類統計資訊資料。
- 環境參數等等。
- 如何構建大規模的診斷服務能力?
SQL診斷最佳化服務需要具備服務於雲上百萬級資料庫執行個體的能力,其線上服務能力同樣面臨巨大挑戰,例如如何?複雜的計算服務化拆分,計算服務的橫向伸縮,最大化的並行,資源訪問分布式環境下的並發控制,不同優先順序的有效調度消除隔離,峰值緩衝等等。
解決方案
SQL診斷最佳化服務是阿里雲資料庫自治服務DAS中最為核心的服務之一,它以SQL語句作為輸入,由DAS完成診斷分析並提供專家最佳化建議(包括索引建議、語句最佳化建議以及預期收益等資訊),使用者不必精通資料庫最佳化領域專家知識,即可獲得SQL最佳化診斷、改寫和最佳化相關的專家建議,最大化SQL執行效能。
另外,依託該能力,DAS的SQL自動最佳化服務將SQL最佳化推向了更高的境界,將重人工的被動式最佳化轉變為以智能化為基礎的主動式最佳化,以自最佳化的自治能力實現SQL最佳化的無人值守。
能力構建
面對上面提到的眾多挑戰,本文著重從DAS中的SQL診斷最佳化引擎核心技術架構以及能力測試集的構建兩個維度進一步解讀。
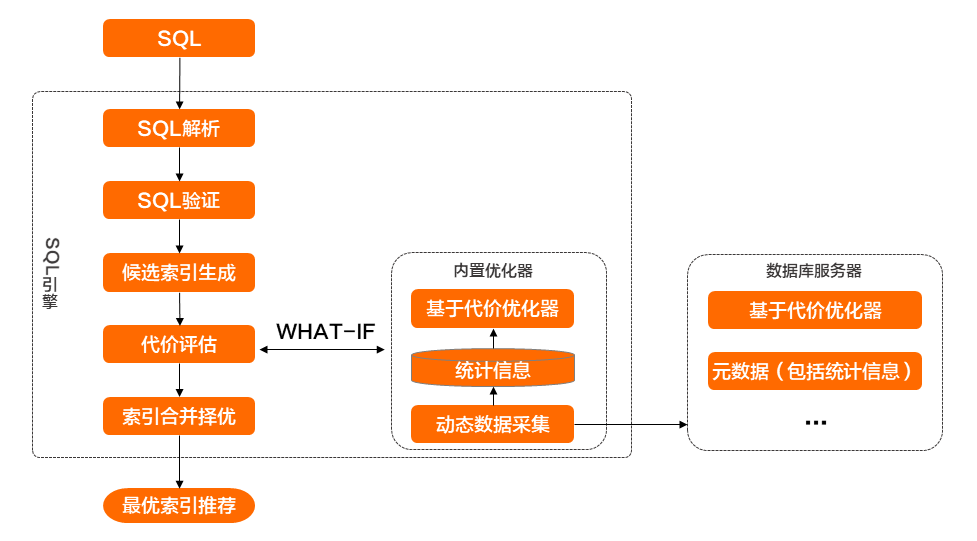
- SQL解析與驗證:引擎對查詢語句做解析驗證,驗證輸入查詢語句是否符合標準,識別查詢語句的組成形成文法樹,例如:謂詞以及謂詞類型、排序欄位、彙總欄位、查詢欄位等,識別查詢語句相關欄位的資料類型。驗證SQL使用到的表、欄位是否符合目標資料庫的結構設計。
- 候選索引產生:依據解析驗證後的文法樹,產生多種候選索引組合。
- 基於代價評估:代價評估基於內建獨立於資料庫核心的最佳化器,擷取資料庫統計資訊,在診斷引擎內部作緩衝。診斷引擎內建最佳化器基於統計資訊計算代價,評估每個索引的代價以及不同SQL改寫方法下的代價評估,從而從代價選擇最優索引或SQL改寫方法。
- 索引合并與擇優:引擎輸入可以是一條查詢語句,也可以為多個查詢語句,或者整個資料庫執行個體所有的查詢語句。為多個查詢語句做索引推薦,不同的查詢語句的索引建議,以及已經存在的物理索引,有可能存在相同索引、首碼相同索引、雷同索引。
構建具有足夠覆蓋度的能力測試集,並以此為尺,度量能力,驅動能力構建。在這一過程中,如下圖所示,DAS構建了以用例系統為中心的開發模式。
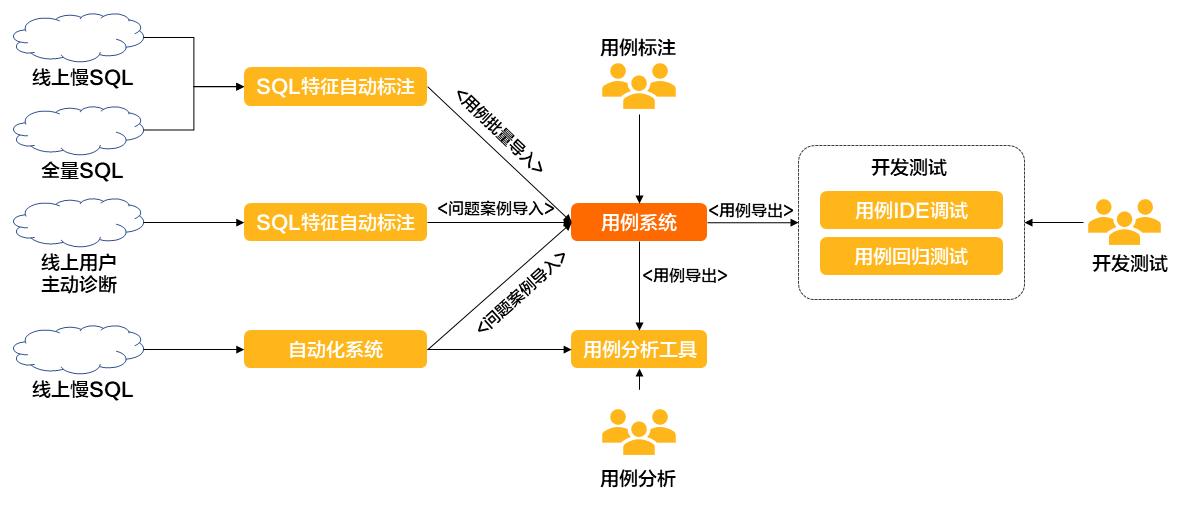
能力測試集構建的基本思想,首先通過特徵化實現測試案例基於特徵的形式化描述,形成測試案例形式化特徵庫,並具備足夠的完備性。
- 哪些測形式化特徵測試案例已被測試案例覆蓋,完備度是多少?
- 哪些形式化特徵測試案例,當前的診斷最佳化能力未覆蓋?或測實驗證失敗?
- 在一段時間哪些測形式化特徵測試案例出現頻繁的迴歸問題?
- 各能力級的測試案例覆蓋率怎樣?
最佳化
- 自助最佳化:集團使用者指定問題SQL,服務完成診斷並提供最佳化專家建議。
- 自動最佳化:自動最佳化服務自動識別業務資料庫執行個體工作負載上的慢查詢,主動完成診斷,產生最佳化建議,評估後編排最佳化任務,自動完成後續的最佳化上線操作及效能跟蹤,形成全自動的最佳化閉環,提升資料庫效能,持續保持資料庫執行個體運行在最佳最佳化狀態。
更為重要的是,SQL診斷最佳化服務已經構建了有效主動式分析,反饋系統,線上診斷失敗案例,使用者反饋案例,自動最佳化中的復原案例會自動迴流到案例系統,一刻不停地驅動著診斷服務在快速迭代中成長。
支援的引擎
SQL診斷目前已支援的資料庫引擎包括RDS MySQL、PolarDB MySQL版、RDS PostgreSQL和PolarDB PostgreSQL版(相容Oracle)。