如果您的應用遇到流量不均、單機故障、慢介面治理、業務流量統計、灰階發布監控等問題,可以通過應用監控的調用鏈分析快速定位問題代碼。本文介紹如何通過調用鏈分析快速定位五種經典線上問題,更直觀地瞭解調用鏈分析的用法與價值。
背景資訊
除了使用調用鏈排查單次請求的異常,或者使用預彙總的鏈路統計指標進行服務監控與警示之外,鏈路追蹤還支援基於明細鏈路資料的後彙總分析,簡稱調用鏈分析(Trace Explorer)。相比調用鏈,調用鏈分析能夠更快地定位問題;相比預彙總的監控圖表,調用鏈分析可以更靈活地實現自訂診斷。
調用鏈分析是基於已儲存的全量鏈路詳細資料,自由組合篩選條件與彙總維度進行即時分析,可以滿足不同情境的自訂診斷需求。例如,查看耗時大於3秒的慢調用時序分布,查看錯誤請求在不同機器上的分布,或者查看VIP客戶的流量變化等。
問題一:流量不均
負載平衡配置錯誤,導致大量請求打到少量機器,造成“熱點”影響服務可用性,怎麼辦?
流量不均導致的“熱點擊穿”問題,很容易造成服務不可用。在生產環境中出現過多起這樣的案例,比如因負載平衡配置錯誤,註冊中心異常導致重啟節點的服務無法上線,DHT雜湊因子異常等。
流量不均的最大風險在於能否及時發現“熱點”現象。它的問題表象更多是服務響應變慢或報錯,傳統的監控無法直觀地反映熱點現象,所以大部分營運人員都不會第一時間考慮這個因素,從而浪費了寶貴的應急處理時間,造成故障影響面不斷擴散。
通過調用鏈分析按IP分組統計鏈路資料,可以直觀地看到調用請求分布在哪些機器上,特別是問題發生前後的流量分布變化。如果大量請求突然集中在一台或少量機器,很可能是流量不均導致的熱點問題,然後再結合問題發生點的變更事件,快速定位造成故障的錯誤變更,及時復原。
在調用鏈分析版面設定按IP彙總,如下圖所示,可以發現大部分流量集中在opentelemetry-demo-frontend-XX這台機器上。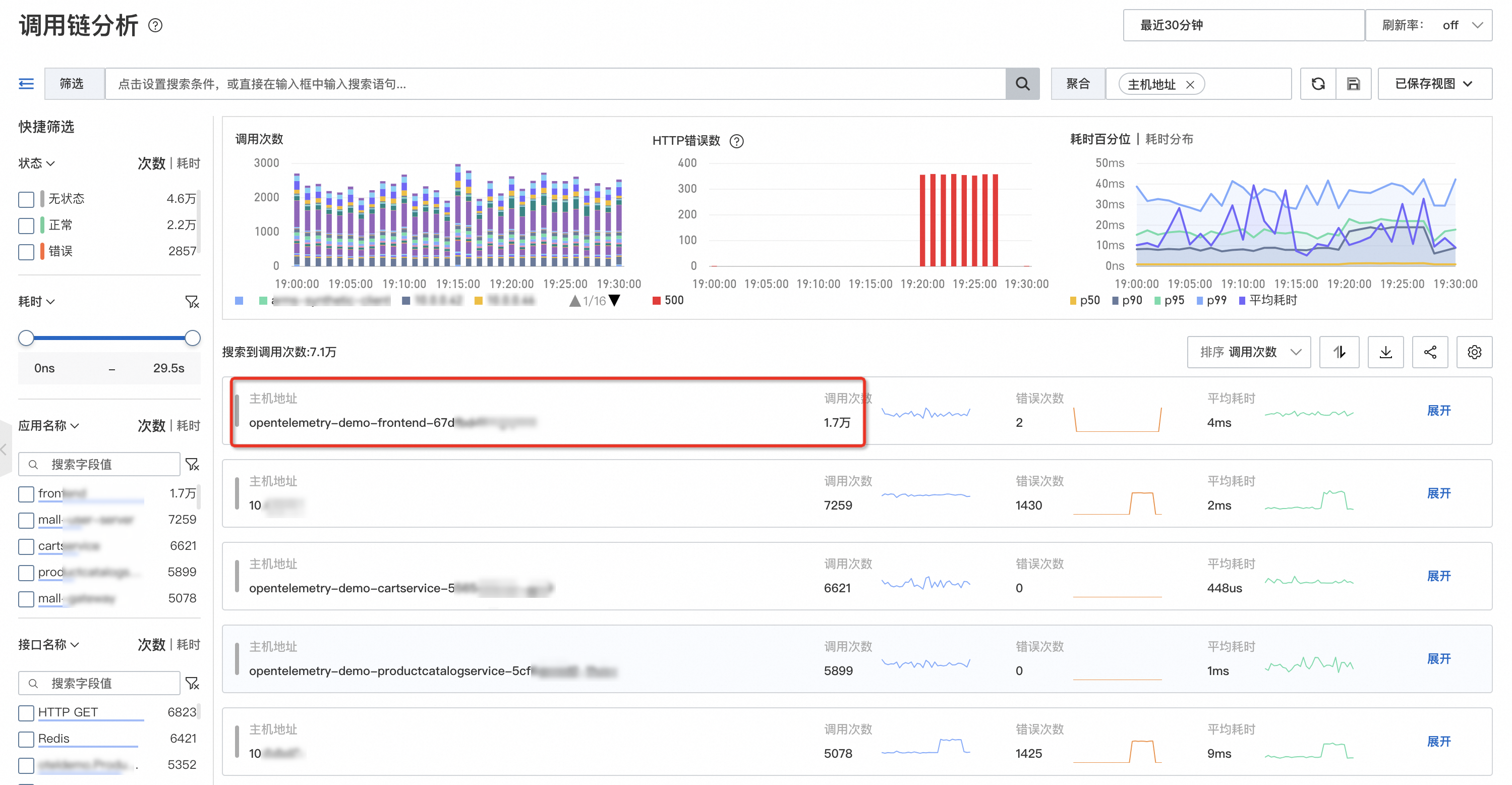
問題二:單機故障
網卡損壞、CPU超賣、磁碟打滿等單機故障,導致部分請求失敗或逾時,如何排查?
單機故障每時每刻都在頻繁發生,特別是核心叢集由於節點數量比較多,從統計機率來看幾乎是一種“必然”事件。單機故障不會造成服務大面積不可用,但是會造成少量的使用者請求失敗或逾時,持續影響使用者體驗和答疑成本,需要及時處理。
單機故障可以分為宿主機故障和容器故障兩類(在Kubernetes環境可以分為Node和Pod)。例如CPU超賣、硬體故障等都是宿主機分級,會影響所有容器;而磁碟打滿、記憶體溢出等故障僅影響單個容器。因此,在排查單機故障時,可以根據宿主機IP和容器IP兩個維度分別進行分析。
面對這類問題,可以通過調用鏈分析先篩選出異常或逾時請求,然後再根據宿主機IP或容器IP進行彙總分析,可以快速判斷是否存在單機故障。如果異常請求集中在單台機器,可以嘗試替換機器進行快速恢複,或者排查該機器的各項系統參數:例如磁碟空間是否已滿、CPU Steal Time是否過高等。如果異常請求分散在多台機器,那麼大機率可以排除單機故障因素,可以重點分析下遊依賴服務或程式邏輯是否異常。
在調用鏈分析頁面篩選錯誤調用或慢調用,並設定按IP進行分組統計,如果異常調用集中出現在特定機器,則有較大機率是機器故障。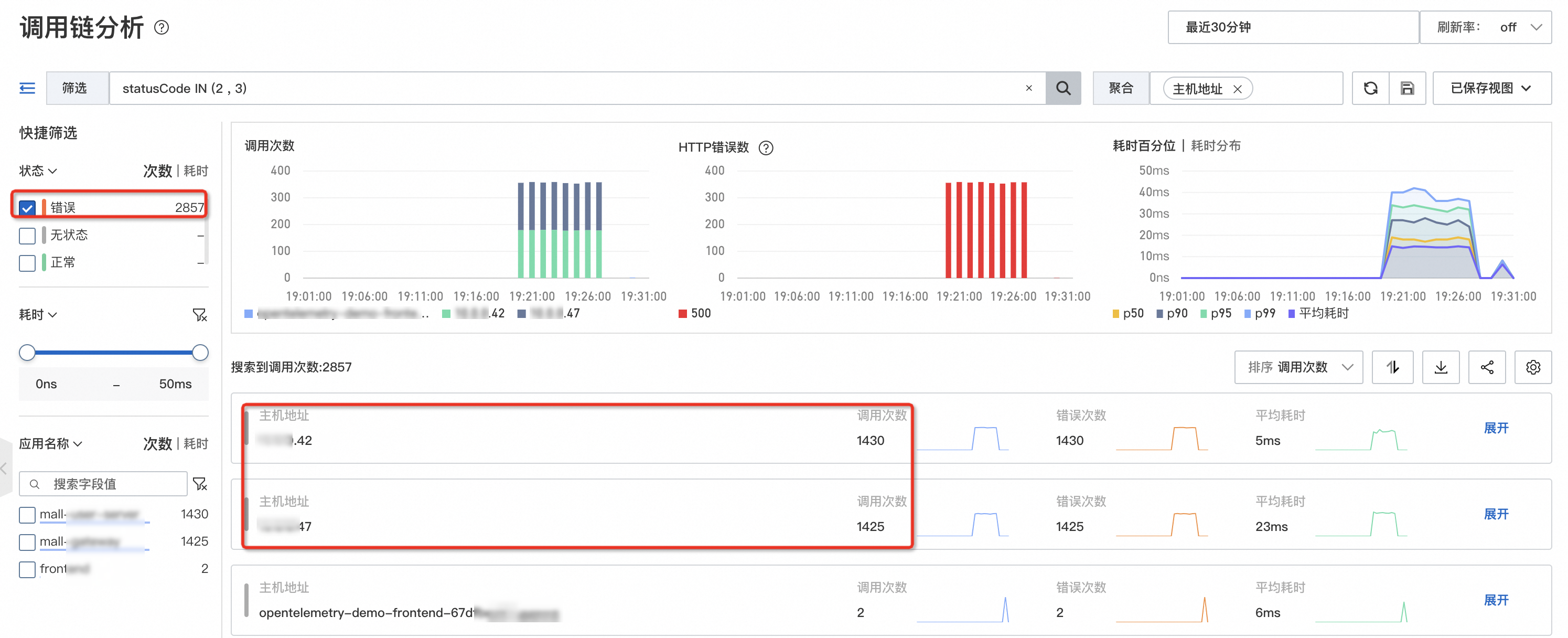
問題三:慢介面治理
新應用上線或大促前效能最佳化,如何快速梳理慢介面列表,解決效能瓶頸?
新應用上線或大促備戰時通常需要做一次系統性的效能調優。第一步就是分析當前系統存在哪些效能瓶頸,梳理出慢介面的列表和出現頻率。
此時,可以通過調用鏈分析篩選出耗時大於一定閾值的調用,再根據介面名稱進行分組統計,這樣就可以快速定位慢介面的列表與規律,然後對出現頻率最高的慢介面逐一進行治理。
找到慢介面後,可以結合相關的調用鏈、方法棧和線程池等資料定位慢調用根因。常見原因包括以下幾類:
資料庫或微服務串連池過小,大量請求處於擷取串連狀態。可以調大串連池最大線程數解決。
N+1問題。例如一次外部請求內部調用了上百次的資料庫調用,可以將片段化的請求進行合并,降低網路傳輸耗時。
單次請求資料過大,導致網路傳輸和還原序列化時間過長,而且容易導致Full GC。可以將全量查詢改為分頁查詢,避免一次請求過多資料。
日誌架構“熱鎖”。可以將日誌同步輸出改為非同步輸出。
在調用鏈分析頁面篩選大於5秒的慢調用,並設定按介面名進行分組統計,發現慢介面的規律。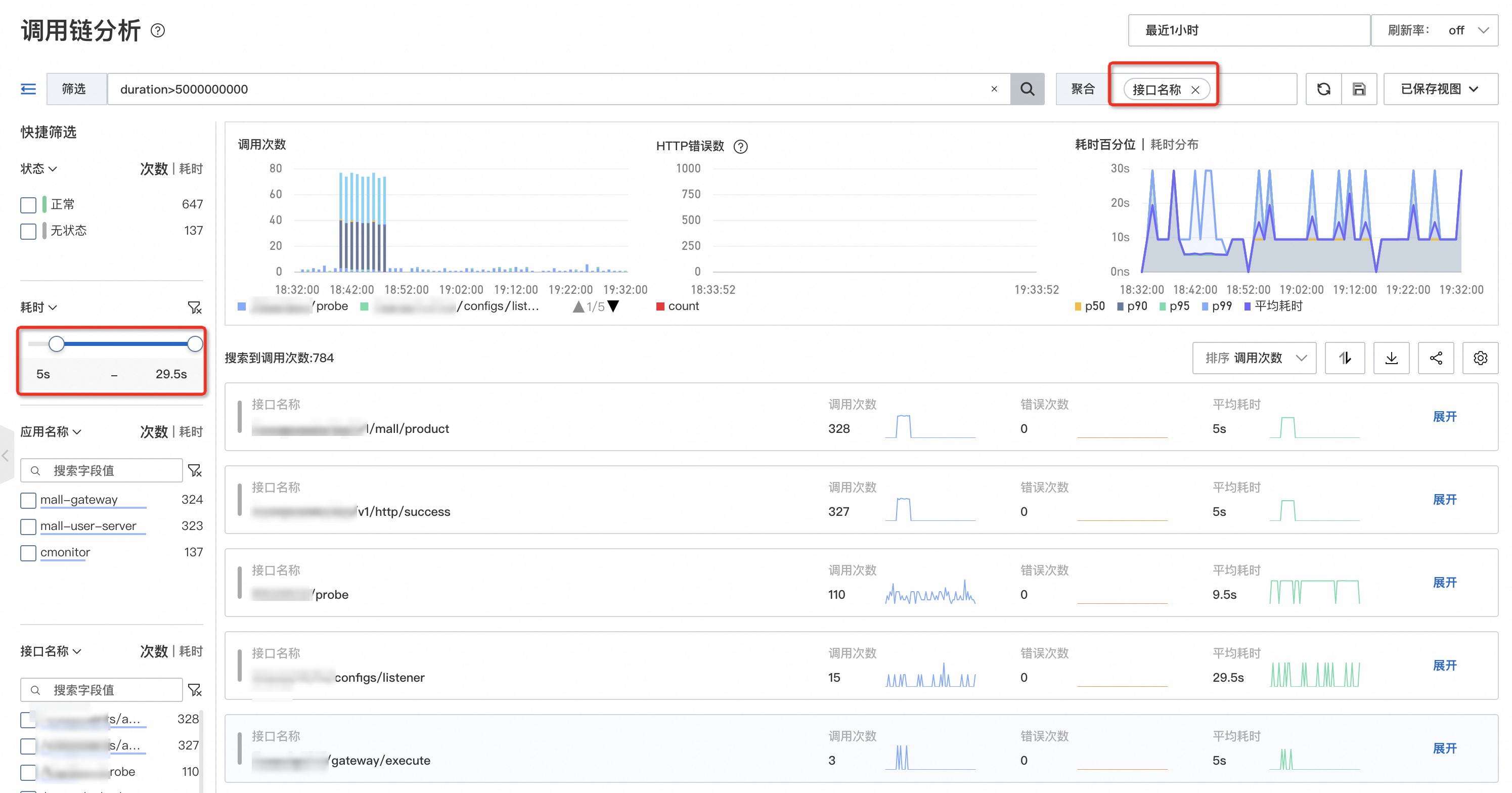
問題四:業務流量統計
如何分析重保客戶或渠道的流量變化和服務品質?
在實際生產環境中,服務通常是標準的,但業務卻是分類分級的。同樣的訂單服務,我們需要按照類目、渠道、使用者等維度進行分類統計,實現精細化營運。例如,對於線下零售渠道而言,每一筆訂單、每一個POS機的穩定性都可能會觸發輿情,線下渠道的SLA要求要遠高於線上渠道。那麼,應該如何在通用的電商服務體系中,精準地監控線下零售鏈路的流量狀態和服務品質呢?
這裡可以使用調用鏈分析的自訂Attributes過濾和統計實現低成本的業務調用鏈分析。例如,在入口服務針對線下訂單打上 {"attributes.channel": "offline"}的標籤,然後再針對不同門店、使用者客群和商品類目分別打標。最後,通過對attributes.channel = offline進行過濾,再對不同的業務標籤進行group by來分組統計調用次數、耗時或錯誤率等指標,就可以快速地分析出每一類業務情境的流量趨勢與服務品質。
問題五:灰階發布監控
500台機器分10批發布,如何在第一批灰階發布後,就能快速判斷是否有異常?
變更三板斧“可灰階、可監控、可復原”是保障線上穩定性的重要準則。其中,分批次灰階變更是降低線上風險、控制爆炸半徑的關鍵手段。一旦發現灰階批次的服務狀態異常,應及時進行復原,而不是繼續發布。然而,生產環境很多故障的發生都是由於缺乏有效灰階監控導致的。
例如,當微服務註冊中心異常時,重啟發布的機器無法進行服務註冊上線。由於缺乏灰階監控,前幾批重啟機器雖然全部註冊失敗,導致所有流量都集中路由到最後一批機器,但是應用監控的總體流量和耗時沒有顯著變化,直至最後一批機器也重啟註冊失敗後,整個應用進入完全不可用狀態,最終導致了嚴重的線上故障。
在上述案例中,如果使用{"attributes.version": "v1.0.x"}對不同機器流量進行版本打標,通過調用鏈分析對attributes.version進行分組統計,可以清晰地區分發布前後或不同版本的流量變化和服務品質,不會出現灰階批次異常被全域監控掩蓋的情況。
調用鏈分析的約束限制
調用鏈分析雖然使用靈活,可以滿足不同情境的自訂診斷需求,但是它也有幾點使用約束限制:
基於鏈路詳細資料進行分析的成本較高。
調用鏈分析的前提是儘可能完整地上報並儲存鏈路詳細資料。如果採樣率比較低導致詳細資料不全,調用鏈分析的效果就會大打折扣。為了降低全量儲存成本,可以在使用者叢集內部署邊緣資料節點,進行臨時資料緩衝與處理,降低跨網路上報開銷。或者,在服務端進行冷熱資料分離儲存,熱儲存進行全量調用鏈分析,冷儲存進行錯慢鏈路診斷。
後彙總分析的查詢效能開銷大,並發小,不適合用於警示。
調用鏈分析是即時的進行全量資料掃描與統計,查詢效能開銷要遠大於預彙總統計指標,所以不適合進行高並發的警示查詢。需要結合自訂指標功能將後彙總分析語句下推至用戶端進行自訂指標統計,以便支援警示與大盤定製。
結合自訂標籤埋點,才能最大化釋放調用鏈分析價值。
調用鏈分析不同於標準的應用監控預彙總指標,很多自訂情境的標籤需要使用者手動埋點打標,這樣才能最有效地區分不同業務情境,實現精準分析。
相關文檔
為避免在出現問題後被動診斷錯誤原因,您還可以使用ARMS的警示功能針對一個介面或全部介面建立警示,即可在出現問題時向營運團隊發送通知。如何建立警示,請參見應用監控警示規則。